






 复旦大学DISC团队提出LReasoner系统,聚焦文本逻辑推理,通过逻辑驱动的上下文扩展和数据增强,提升模型对逻辑结构的理解。实验结果超越人类,在ReClor和LogiQA上取得SOTA。研究关注逻辑表达式识别、隐式推理与逻辑文本化,展示了符号逻辑在逻辑推理中的关键作用。
复旦大学DISC团队提出LReasoner系统,聚焦文本逻辑推理,通过逻辑驱动的上下文扩展和数据增强,提升模型对逻辑结构的理解。实验结果超越人类,在ReClor和LogiQA上取得SOTA。研究关注逻辑表达式识别、隐式推理与逻辑文本化,展示了符号逻辑在逻辑推理中的关键作用。
每天给你送来NLP技术干货!
来自:复旦DISC


引言

ACL2022中,复旦大学数据智能与社会计算实验室 (Fudan DISC) 提出了一篇文本逻辑推理的工作,论文题目为:Logic-Driven Context Extension and Data Augmentation for Logical Reasoning of Text,被录取为Findings长文。

文章摘要

基于文本的逻辑推理需要识别文本中的逻辑结构并执行逻辑推断,目前的方法主要关注于文本的上下文语义而难以对逻辑推断过程进行明确建模。本文我们提出了一个LReasoner系统,由两个部分组成:逻辑驱动的文本扩充框架(Logic-Driven Context Extension Framework)和逻辑驱动的样本增强算法(Logic-Driven Data Augmentation Algorithm)。前者通过提取逻辑表达式作为基本推理单元,根据逻辑等价律来符号化地推断隐式存在的表达式,并扩充给定文本以匹配答案。后者构造字面上相似但逻辑上不同的样本,通过对比学习使得模型更好地捕捉文本中的逻辑信息,尤其是逻辑上的否定和条件关系。我们在两个基准数据集ReClor和LogiQA上进行了实验,结果表明了我们提出的推理系统的有效性,甚至在ReClor数据上超过了人类性能。

研究动机

本文关注基于文本的逻辑推理任务(Logical Reasoning of Text),例题如下,给定一段文本,一个问题和四个候选选项,需从选项中识别出和上下文逻辑符合的答案。逻辑推理问题的挑战在于识别文本中的逻辑结构并基于已经明确的信息进行逻辑推断, 这超出了上下文预训练模型的能力。没有逻辑标注的情况下,预训练模型通常将逻辑推理看作传统阅读理解任务并对给定上下文和选项直接进行匹配,而无法对离散逻辑推断过程进行明确建模。DAGN使用篇章结构信息来识别文本中逻辑结构并提出基于篇章结构的图网络来处理逻辑推理问题,但它仍旧关注于提升上下文表示而忽略了逻辑推断过程建模。

针对这些问题,我们提出了一个基于符号逻辑信息的推理三步骤范式。首先我们从文本中识别出逻辑表达式作为基本推理单元,来表示逻辑符号之间的逻辑关系;然后我们根据逻辑等价律执行逻辑推断,从已经识别的表达式中扩展隐式存在的;最后可以通过比较候选答案和推导出的逻辑表达式来选出最有可能的答案。
我们提出了一个逻辑驱动的上下文扩展框架来整合这三个步骤,即逻辑识别(logic identification)来从上下文中解析出逻辑表达式,逻辑扩展(logic extension)来推导出隐式表达式,和逻辑文本化(logic verbalization)来预测答案。为了结合符号推理的可解释性和连续表示的抗噪性,我们遵循了一个神经-符号推理范式,以符号方式执行逻辑识别和扩展,对于逻辑文本化我们采用预训练模型作为基础。为了使得模型更好地捕捉逻辑信息,我们还提出了一个逻辑驱动的数据增强算法,通过修改已识别的逻辑表达式来构造字面上相似但逻辑上不同的文本,并应用对比学习使模型区分不同的文本,从而促使其更好捕捉逻辑表达式中的否定和条件关系。
我们在数据集ReClor和LogiQA上进行了实验并达到了SOTA效果,甚至在ReClor上超过了人类表现,我们还通过实验分别证明了逻辑驱动的上下文扩展框架和数据增强算法的有效性,并论证了LReasoner系统的泛化性。

模型

逻辑驱动的上下文扩展
针对文本逻辑推理,我们提出了一个逻辑驱动的上下文扩展框架,如下图所示,可以分成三个步骤:从上下文和选项中识别出逻辑符号和表达式(logic identification),执行可解释逻辑推断来扩展隐式存在的逻辑表达式(logic extension),将扩展的表达式文本化来扩展上下文从而使用预训练模型匹配答案(logic verbalization)。
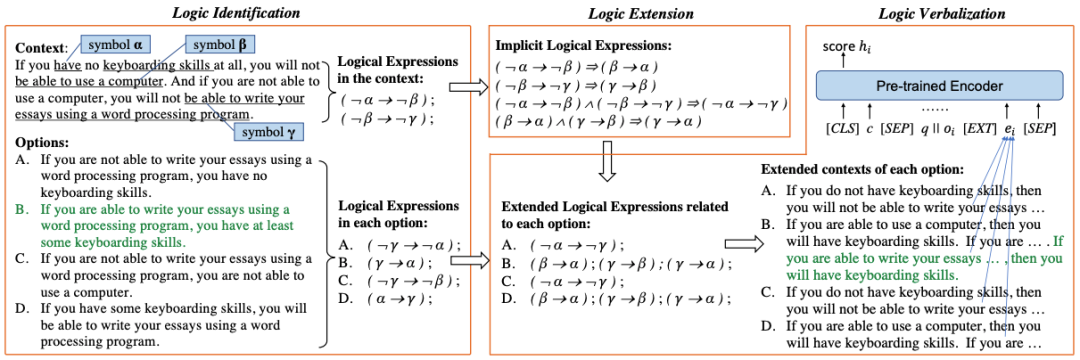
1. 逻辑识别(Logic Identification)
我们首先需要识别出上下文和选项中的逻辑表达式作为基本推理单元,如(¬α→¬β),来挖掘出逻辑符号(如α: have keyboarding skills和β:be able to use a compute)之间的逻辑关系(¬:逻辑否定和→:逻辑条件)。
为了保证框架的通用性,我们设计了一个简单的识别方法,首先通过现成的constituency parser来从文本中抽取出名词短语和动名词短语作为基本逻辑符号,然后每句话中的逻辑符号通过逻辑关系组合构成逻辑表达式:如果存在一个否定词(如“not”)和一个逻辑符号α关联,我们在α前加一个否定连接符作为新的逻辑符号¬ α;如果两个逻辑符号α和β 之间存在条件关系,对应的逻辑表达式可以构造为(α → β)。如上图,根据上下文抽取出了三个逻辑符号{α, β, γ}和两个逻辑表达式(¬α→¬β) 和 (¬β→¬γ)。
2. 逻辑扩展(Logic Extension)
除了上下文中明确存在的逻辑表达式外,还有一些其他隐含的表达式需要我们进行逻辑推断和扩展。基于上下文中已经识别的逻辑表达式,我们根据逻辑等价律扩充出文本中隐式的逻辑表达式,我们采用了两个最适用的逻辑等价定律,涉及命题逻辑中的蕴涵和否定,包括换质换位律(contraposition)和传递律(transitive law)。
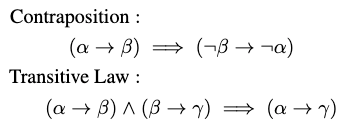
如框架图,我们扩充出了{(β →α),(γ → β),(¬α → ¬γ),(γ → α)}四个逻辑表达式。
3. 逻辑文本化(Logic Verbalization)
扩展出隐式的逻辑表达式之后,考虑到符号逻辑更难编码,我们将其表示为自然语言以便更好地利用预训练模型。针对每个选项,我们根据逻辑符号的重叠来选择相关的扩展表达式,然后通过模板填充将它们转换为自然语言作为扩充的上下文。我们采用了逻辑推理中最为常见的If-Then语句作为文本化模板,但我们会根据时态和单/复数进行一些调整,具体模板如下,然后将扩展上下文输入到预训练模型中来匹配选项预测答案,损失函数计算为。

逻辑驱动的数据增强
我们参考了 SimCLR的思路,通过构造字面上相似但逻辑不同的样本,来训练模型以预测出支持答案的逻辑正确文本,从而让模型可以更好地感知到文本中的逻辑信息,尤其是逻辑否定和逻辑条件关系。我们计算了一个分类损失作为对比学习的损失函数,来预测最有可能支持答案的正确上下文,如下图。
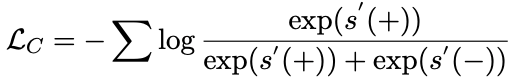
我们使用原始文本来构成正样本,而负样本则是通过随机修改文本中抽取出的逻辑表达式,包括删除、条件逆转、否定操作,并将修改后的逻辑表达式转化成文本而构成,具体构造负样本的过程下图所示。基于此我们的框架通过一个组合损失函数来训练。


实验

我们在数据集ReCloe和LogiQA上进行了实验,其中ReClor根据是否存在bias还分为HARD和EASY数据集。实验结果显示LReasoner优于其他模型,甚至超过ReClor上的人类表现,并且在ReClor的HARD和EASY数据集上都有提升。我们基于不同的基础模型包括RoBERTa, ALBERT和DeBERTa构建了LReasoner系统,都实现了稳定性提升。

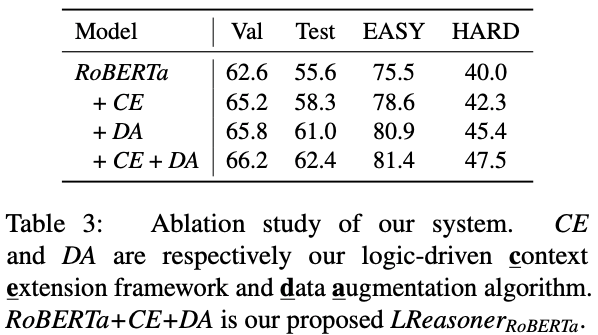
我们还进行了消融实验,如下图所示,可以看出逻辑驱动的文本扩充框架和数据增强算法对于逻辑推理问题的效果都有所提升。
我们还通过对不同的负样本构造策略进行比较,说明了逻辑驱动对比学习中逻辑负样本的有效性。
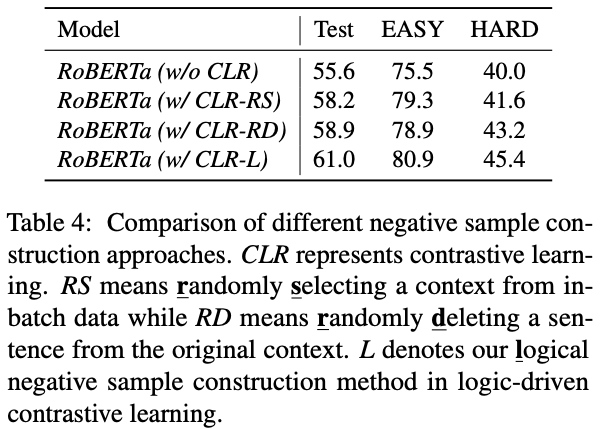
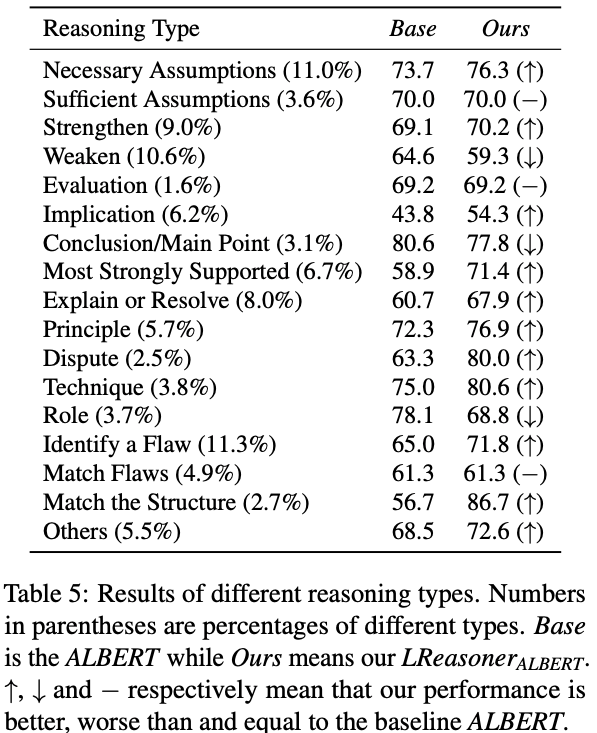
由于ReClor涵盖了不同的逻辑推理技能,我们详细地对不同逻辑推理种类上的效果进行了分析,如下图所示,我们的模型在大多数推理类型上都实现了提升,尤其是Implication和Most Strongly Supported类型,但是Match flaws和Weaken种类对于LReasoner仍具一定的挑战,这需要模型进一步考虑如何对逻辑语句的不同程度进行建模,并抽象出完整的逻辑链以进行缺陷识别。

总结

这篇文章中,我们主要研究文本的逻辑推理问题。遵循三步逻辑推理范式,我们首先提出了一个逻辑驱动的上下文扩展框架。它识别逻辑表达式作为逻辑推理的基本单元,以符号方式推导出隐含的表达式,并将其作为扩展上下文输入到预先训练的模型中以匹配答案。我们还提出了一种逻辑驱动的数据增强算法,构造字面上相似但逻辑上不同的样本,并使用对比学习来帮助我们的模型更好地捕获逻辑信息。实验结果证实了我们的LReasoner的总体有效性,甚至在ReClor数据集上超过了人类的表现。在未来,我们将探索考虑不同逻辑推理类型的模型,并将符号逻辑直接整合进模型结构。
供稿人:王思远丨博士四年级丨研究方向:基于文本的问题生成与回答,知识建模丨邮箱:wangsy18@fudan.edu.cn
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









