






每天给你送来NLP技术干货!

来自:复旦DISC

引言

ACL2022中,复旦大学数据智能与社会计算实验室 (Fudan DISC) 提出了一篇对话预训练的工作,论文题目为:DialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation DialogVED,被录取为主会长文。


文章摘要

本文提出了一种新的对话预训练框架 DialogVED,它将连续隐变量引入增强的编码器-解码器框架中,以提高响应的相关性和多样性。我们使用多个任务在大型对话语料库 Reddit 上对模型进行预训练,并在 PersonaChat、DailyDialog 和 DSTC7-AVSD 基准上进行微调实验。结果表明,我们的模型在所有这些数据集上都达到了最新的水平。

研究背景

近年来,研究者们在自然语言理解和生成领域中广泛探索了预训练语言模型,这种预训练和微调范例为自然语言处理中的各种下游任务提供了启示。与一般的预训练模型相比,根据任务特征设计的面向任务(例如摘要,对话等)的预训练模型可以实现更好的性能并且更健壮。在本文中,我们在先前研究的基础上提出了一种新的预训练对话响应生成模型。
对话响应生成中有一个众所周知的一对多问题,即单个对话上下文可以跟随多个合理的响应。现有的工作引入了潜在变量来模拟这个问题,如 VHRED、VAE-Seq2Seq 、DVAE 等模型。最近,PLATO 在预训练对话模型中引入了离散隐变量,并在多个下游响应生成任务中展示了显著的性能提升。除了离散潜变量外,连续潜变量也通常用于建模对话系统中的一对多映射,但将连续隐变量与大规模语言预训练结合的潜力却很少有人探索。
在本文中,我们提出了一种将连续隐变量引入到编码器-解码器框架的模型 DialogVED,并同时优化以下 4 个训练目标来进行预训练:1)掩码语言模型损失,以增强编码器对上下文的理解,2)具有 n-gram 损失的响应生成损失,以提高解码器的规划能力, 3) Kullback-Leibler 散度损失,以最小化隐变量的后验分布和先验分布之间的差异,以及 4) 词袋损失以减少后验分布崩溃。此外,我们还探讨了绝对和相对位置编码对模型性能的影响。我们在三种不同类型的下游对话任务上进行了实验:闲聊、基于知识的对话和对话式问答。实验结果验证了我们的模型的有效性。我们还进行了消融研究,以更好地了解 DialogVED 中不同组件对模型性能的影响,包括隐变量空间大小、不同的解码策略以及轮次和角色的位置编码。

方法描述

模型架构
DialogVED 由编码器、解码器和隐变量组成,其中编码器决定隐空间的分布,隐变量则从隐空间中抽样得到,编码器和隐变量共同引导解码器,整体框架如下图所示。
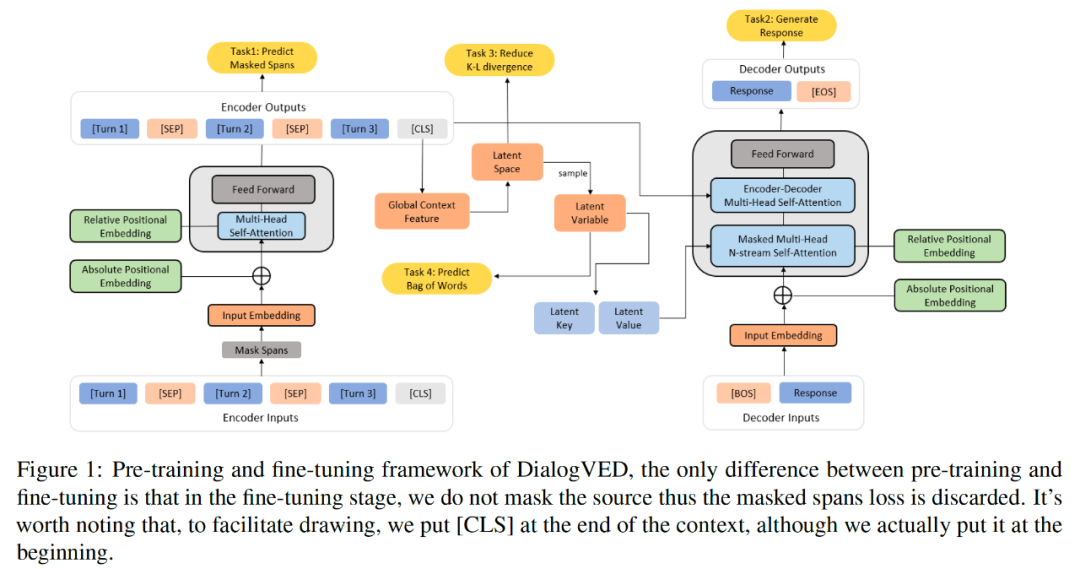
编码器
我们使用多层 Transformer 编码器来编码对话上下文(即 context),为了提高编码器的理解能力和对噪声的鲁棒性,我们使用 span masking 的方式随机遮盖了部分上下文。我们采用一种简单的方法来遮盖 span:1)在上下文中随机选择 个 token,表示为 ;2) 对于每个 token ,将其扩展到一个固定长度为 的文本 span;3) 在排序、去重和检查边界之后遮盖所有选中的标记。和 BERT 类似,我们控制上下文中被掩码的 token 总数约占 15%,并使用被遮盖的 token 经过编码后的隐状态表示去预测自身。值得注意的是,我们仅在预训练阶段屏蔽上下文。
隐变量
直观上,引入隐变量可以提供了分层的生成方式,即利用隐变量确定高级语义,然后进行解码以生成句子级别的句法和词汇细节。我们在上下文的开头添加了一个特殊的分类标记 [CLS],其对应的隐状态表示 用于表示全局的对话上下文。我们假设隐向量的后验分布为正态分布,并使用 MLP 层将 映射为隐空间的均值和对数方差,通过对该正态分布进行抽样,即可得到对应的隐变量。
解码器
我们在解码器中使用了未来预测策略,和每个时间步只预测下一个 token 不同,未来预测同时预测 个未来 token。具体来说,原始的 Seq2Seq 模型旨在优化条件似然函数 ,而未来预测策略将预测的优化目标为 ,其中 表示下一个连续的 个未来 token。未来的 n-gram 预测损失可以明确地鼓励模型规划未来的 token 预测,并防止对强局部相关性的过度拟合。
我们在解码器中采用 ProphetNet 中提出的 n-stream 自注意力。n-stream self-attention 机制在 main stream(主流)之外加入了 个额外的 self-attention predicting stream(预测流),这些预测流分别用于预测 个连续的未来 token。Main stream 和 predicting stream 的工作原理建议读者阅读 ProphetNet。
Memory Scheme
为了连接隐变量和解码器,我们采取了类似 OPTIMUS 中提出的 Memory Scheme,即将隐变量映射为一个额外的 memory vector ,这是一个额外的键值对。
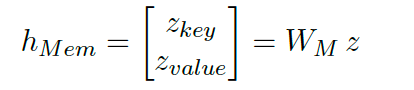
在 decoder 的每一层中是共享的,并通过以下方式进行传播。
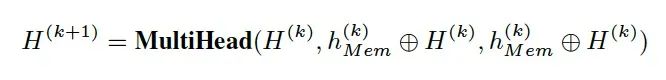
memory vector 相当于在解码时加入一个虚拟 token 参与 main stream self-attention 的计算,而 predicting stream 通过与 main stream 交互隐式地受到 memory vector 的影响。这样隐变量就可以通过 memory vector 引导解码器每一步的生成。
与变分自动编码器 (VAE) 类似,我们在响应生成的目标变成了最大化边际对数似然函数的证据下限目标 (ELBO),这相当于同时优化重建损失 :
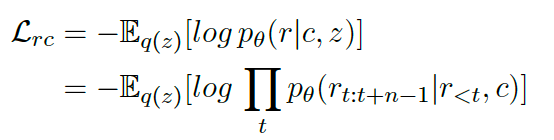
和 KL 正则项 :
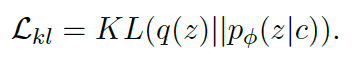
减少 KL 散度消失
由于 DialogVED 允许编码器和解码器之间的交互(即encoder-decoder attention),因此直接训练会导致解码器忽略隐变量,KL 损失将迅速下降到 0,此时隐空间失去了表达能力,这被称为后验坍塌。我们采取了 VAEs 中常用的两种方法:Free Bits 和 Bag-of-words Predicting。
在 Free Bits 中,为了能让更多的信息被编码到隐变量里,我们让 KL 项的每一维都 “保留一点空间”。具体来说,如果这一维的 KL 值太小,我们就不去优化它,等到它增大超过一个阈值再优化。
在 Bag-of-words Predicting 中,我们让隐变量以非自回归方式预测响应中的单词,即鼓励隐变量中可以尽可能包含响应的词汇信息。这个方法可以看做是增大了重建损失的权重,让模型更多去关注优化重建损失项。
位置编码
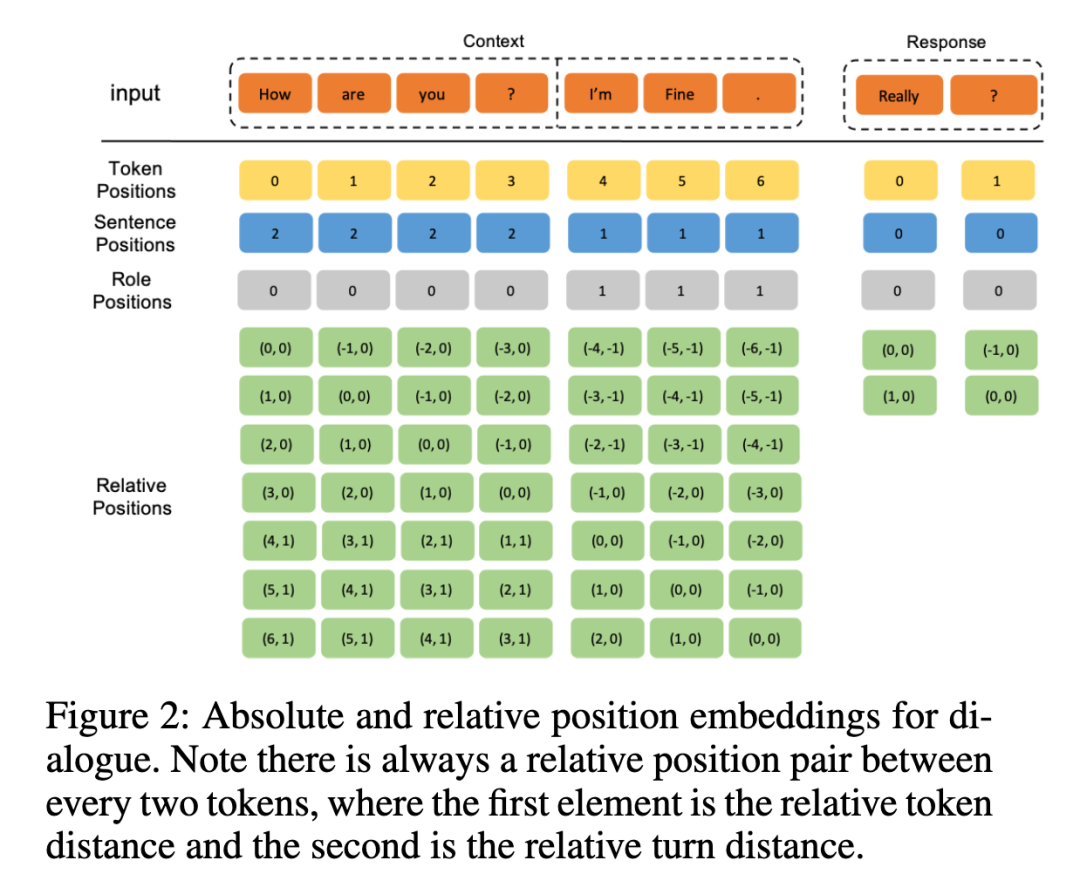
除了原始 Transformer 中使用的 token-level 的位置编码外,我们还考虑了 对话轮次 和 说话人 级别的绝对位置编码。每个 token 的最终 embedding 是对应的 turn、role 和 token embedding 的总和,如下图所示。
除了绝对位置编码之外,我们还考虑了相对位置编码,它考虑了自我注意机制中的“key”和“query”之间的偏移量对应的不同的可学习编码。在对话场景中,即使两个 token 的相对距离相同,由于 token 所在轮次的相对距离不同,也可能有不同的注意力机制。我们将 T5 中原始相对距离矩阵的元素扩展为二元组。在映射函数中,我们同时考虑 token 之间的相对距离 和 轮次之间的相对距离,其中这些元组通过桶函数映射,然后在预定义的嵌入层中被查询。
预训练目标
综上所述,我们的损失函数由 4 项构成:1)编码器端的遮盖语言损失;2)基于未来预测的 n-ngram 响应生成损失;3)隐变量先验分布和后验分布的 K-L 散度损失;4)词袋预测损失。

实验

数据集
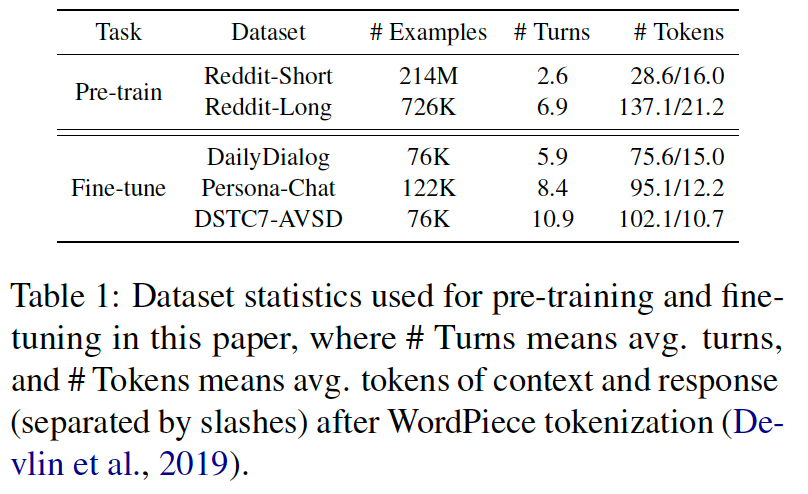
我们使用 DialoGPT 提供的脚本来获取最新的 Reddit 评论数据,我们一共得到了 2.15 亿个训练样本(总共 42GB)用于预训练,为了更高效的训练,我们还将 Reddit 拆分成了 Reddit-Short 和 Reddit-Long。在一个 epoch 中,我们首先使用较大的 batch size 对 Reddit-Short 进行预训练,然后使用较小的 batch size 对 Reddit-Long 进行预训练。
我们选择三个数据集作为我们的下游基准任务:1)DailyDialog,一个聊天数据集,其中包含有关日常生活的高质量人类对话;2)Persona-Chat,基于知识的对话数据集。它提供手动注释的对话和相应的角色配置文件(背景知识),两个参与者可以自然地聊天并尝试相互了解;3)DSTC7-AVSD,一个对话式问答数据集,系统需要在给定对话上下文和背景知识的情况下生成答案。
预训练数据和下游任务数据的统计数据如下表所示。
评价指标
和 PLATO 类似,我们使用了 BLEU-1/2 来衡量生成的响应和参考响应之间的的相关性,以及 Distinct-1/2 来衡量生成的响应的多样性。
实验结果
在下表中,我们将几个 DialogVED 变体与基线模型进行了比较。其中 DialogVED 表示使用 beam search 进行解码的 DialogVED。与 DialogVED 相比,DialogVED w/o latent 表示没有加入隐变量,即损失函数不包括词袋损失和 KL 损失。DialogVED Greedy 表示使用 greedy search DialogVED。对于 DialogVED Sampling,我们在每个解码步骤从具有最高输出概率的 top-K 分布中采样。
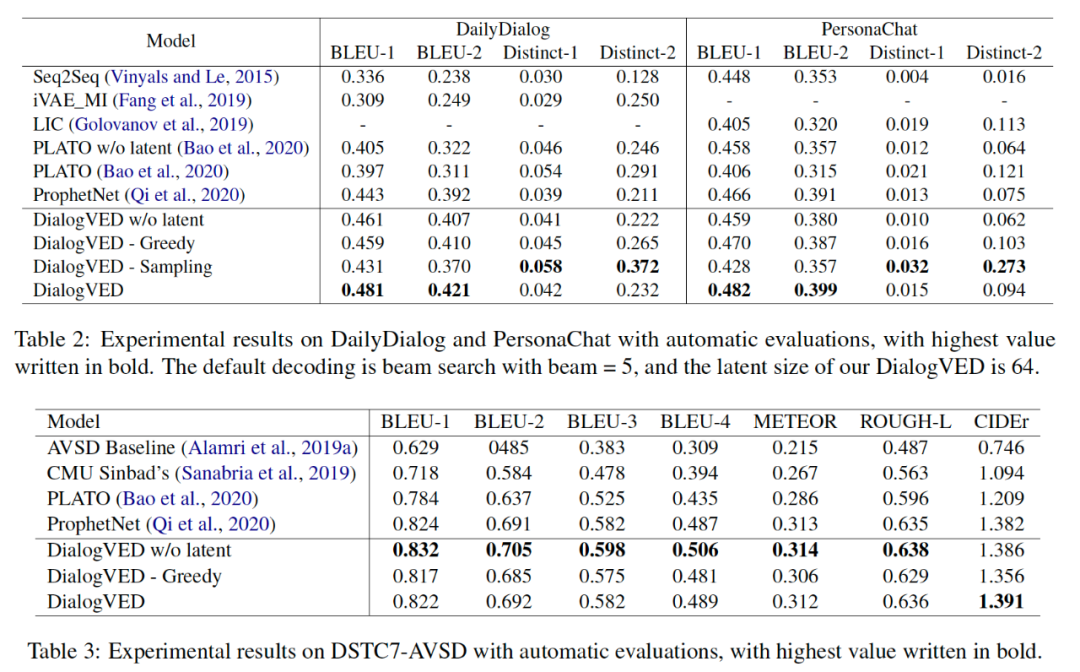
如表所示,我们的模型 DialogVED 与 PLATO 和其他模型相比具有相当的竞争力。特别是,DialogVED Sampling 在 DailyDialog 和 PersonaChat 数据集上的 BLEU-1/2 和 Distinct-1/2 都击败了 PLATO。在 DSTC7-AVSD 上,我们观察到 DialogVED w/o latent 在整体指标中表现最好。然而,DialogVED 的其他变体仍可以超过 PLATO。
有两个基本组件对我们模型的成功做出了巨大贡献:首先,我们采用新开发的预训练语言模型作为初始化,并进一步在我们的对话数据集 (Reddit) 上继续其预训练,因此我们拥有一个非常强大的编码器-解码器。DialogVED w/o latent 在所有三个数据集的所有指标上都击败了 PLATO w/o latent 这一事实证明了这一点。其次,我们模型的特殊结构结合了 seq2seq 模型和 VAE 模型的优点。与一般的 VAE 相比,DialogVED 在解码中允许编码器-解码器交互,避免了低维潜在变量的表示不足。同时,与 seq2seq 模型相比,预测词袋会推动潜在变量,从而为解码器提供额外的指导。事实证明,与 DialogVED w/o latent 相比,我们观察到 DialogVED 在相关性和多样性方面的额外收益。总体而言,DialogVED 在对话响应生成的所有三个下游任务中都取得了先进的结果。
准确性和多样性平衡
我们随后探索了隐变量维度和 Sampling decoding 参数 K 对模型性能的影响。较小的隐变量(P=32) 在基于 n-gram 的指标 (BLEU-1/2) 中更占优势,而较大的隐变量会生成更多样的文本。从 top-K sampling 的结果中,可以看到两个评价指标(即 BLEU-1/2 和 Distinct-1/2)具有负相关的关系。我们可以根据具体场景灵活选择解码策略。
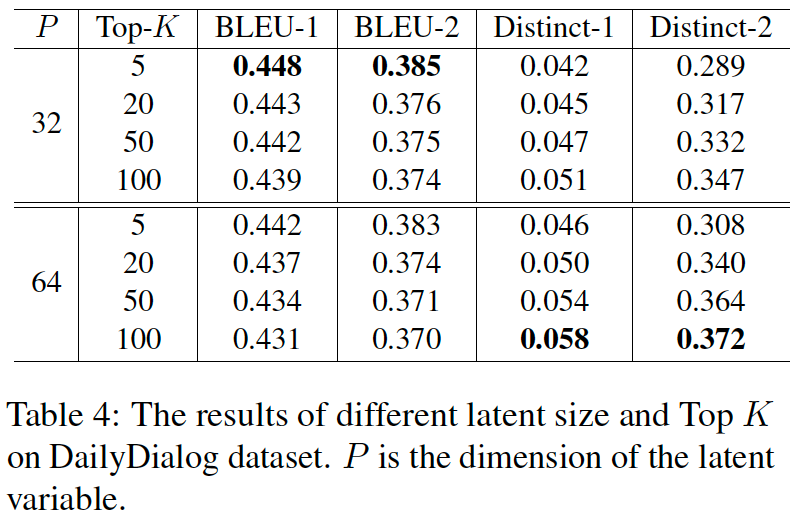
位置编码的影响
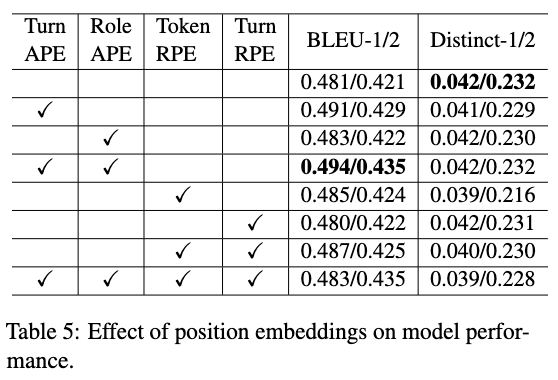
我们探索了绝对位置编码和相对位置编码对模型性能的影响,如下表所示。其中 APE 和 RPE 分别代表绝对和相对位置编码。可以看出 TurnAPE 和 RoleAPE 的组合达到了最好的 BLEU-1/2,绝对和相对位置编码都可以提高模型性能,但是,同时包含它们可能是有害的。
人工评价
我们随机选择 100 个对话上下文并使用以下方法生成响应:PLATO、DialogVED 和 DialogVED-Sampling,并要求注释者从四个方面比较生成的响应质量:流畅性、连贯性、信息量和整体性,可以选择赢、平或输。
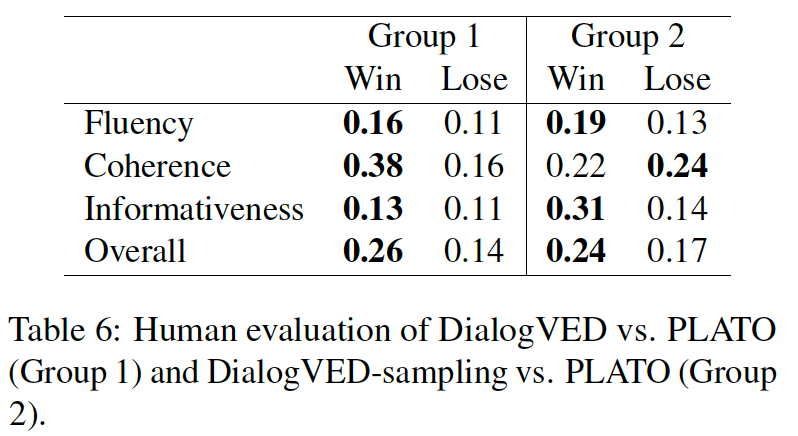
可以看出,大部分都是注释者选择了平手,因为三个模型有时会产生完全相同的响应,这主要是因为它们都在 reddit 上进行预训练。对于 DialogVED,它在连贯性上显著比 PLATO 更胜一筹,而 DialogVED-sampling 在信息量 上明显优于 PLATO。
案例分析
我们还展示了我们的模型以及其他基线模型产生的响应对比。可以看出,尽管我们没有明确地对知识进行建模,但我们的模型准确地输出了上下文中包含的知识信息。同时,与 beam-search 或 greedy-search 相比,top-K sampling 不仅产生更大胆、更多样化的响应,而且可以保持良好的相关性。




总结

本文的主要贡献可以总结如下:1)我们提出了一个预训练对话模型,它将连续的隐变量纳入增强的编码器-解码器预训练框架;2)我们探索了隐变量大小、不同解码策略、轮次和角色的位置编码对模型性能的影响;3)大量实验表明,所提出的模型在多个下游任务中实现了较好的性能,我们的模型在响应生成方面具有更好的相关性和多样性。
供稿丨陈 伟 编辑丨马若雪 责编丨张霁雯供稿人:陈伟 丨博士生 4 年级丨研究方向:对话系统 丨邮箱:chenwei18@fudan.edu.cn
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









