






每天给你送来NLP技术干货!
论文名称:Text Is No More Enough! A Benchmark for Profile-Based Spoken Language Understanding
论文作者:徐啸,覃立波,陈开济,吴国兴,李林琳,车万翔
原创作者:徐啸
论文链接:https://arxiv.org/abs/2112.11953
出处:哈工大SCIR
1. SLU任务定义
口语语言理解(SLU)任务的目的是获取用户询问语句的语义框架表示信息,进而将这些信息为对话管理模块以及自然语言生成模块所使用。SLU任务通常包含意图识别任务和槽位填充任务。
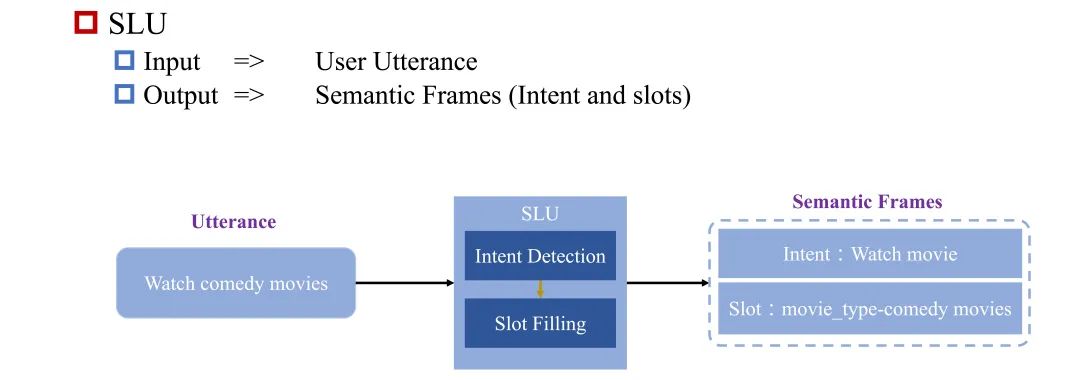
如图1所示,以句子watch comedy movies为例,SLU系统需要分别输出意图 WatchMovie 和槽位名称 movie_type 以及槽值 comedy movies。
2. 背景与动机
口语语言理解(SLU)的研究目前主要局限于传统的基于纯文本的SLU任务,该任务假设,简单的基于纯文本就能够正确识别用户的意图和槽位。但在真实的业务场景中,经常由于用户的口语化输入,而面临具有语义歧义的用户话语。现有的基于纯文本的SLU系统难以应对这一现实场景下的复杂问题。
 图2 现有SLU系统难以解决语义歧义问题
图2 现有SLU系统难以解决语义歧义问题
如图2所示,以 Play Monkey King 为例,Monkey King,也就是孙悟空,是一个具有歧义的名称,可以对应视频、音乐以及有声书三种类型的实体,因此难以基于纯文本确定其意图和槽位。
为了解决这一问题,本文进行了如下探索:
提出了一个重要的新任务——基于Profile的口语语言理解任务(ProSLU),它要求模型不仅要依赖纯文本,而且要充分利用辅助的特征信息来预测正确的意图和槽位。
人工标注了一个用于研究该任务的中文数据集,其中有约五千条的用户话语及其对应的Profile信息(知识图谱(KG),用户配置(UP),环境感知(CA))。
评估了几个最先进的基线模型,并探索了一个多层次的知识适配器,以有效地利用Profile信息。实验结果显示,现有的基于纯文本的SLU模型在语义存在歧义的情况下效果都不佳,而我们提出的多层次的知识适配器可以有效地融合Profile信息,从而在句子级的意图检测和标记级的槽位填充任务中更好的利用Profile信息。
总结了关键的挑战,并为未来的发展方向提供了新的观点,希望能促进这方面的研究。
3. ProSLU任务定义
Profile信息的引入是为了帮助SLU系统,消除用户话语中的歧义。我们定义了以下三种Profile信息,如图3所示,分别是知识图谱信息、用户配置信息和环境感知信息。
 图3 Profile信息的定义
图3 Profile信息的定义
知识图谱信息包括收集到的大量不同类型的实体及其丰富的属性信息,每个实体都会被展平为纯文本序列。
用户配置信息包括用户的个人设置和其他信息,例如用户对音频、视频和有声书这三类APP的使用偏好。
环境感知信息包括用户的当前状态和环境信息,例如移动状态和当前位置

我们将基于Profile的SLU任务简称为ProSLU。下面给出任务的形式化定义,如图4所示,ProSLU要求模型不仅依赖于输入语句,还要利用对应的Profile信息,来预测意图和槽位信息。
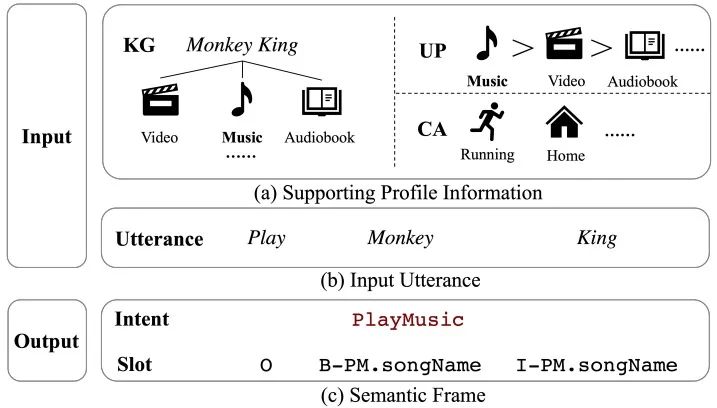 图5 ProSLU任务的具体样例
图5 ProSLU任务的具体样例
如图5所示,KG信息表明Monkey King可能是视频、音乐或有声书实体,UP信息表示当前用户更喜欢听音乐,CA信息表示用户当前正在跑步,结合上述三种Profile信息和用户话语,最终判断出用户的意图为听音乐,槽位为songName。
4. 数据集的构建
我们首先对拟解决的歧义进行定义,如图6所示:
第一种歧义是歧义名称,是由于如Monkey King这类可以表示许多不同类型实体的歧义名称,所带来的词汇歧义,最终导致话语的语义歧义。
第二种歧义是歧义表述,是由于用户的口语化表述所产生的语义歧义,例如我想买一张去上海的票,用户并没有表述清楚想购买的票的类型

接着我们对数据进行设计,基于真实业务数据设计歧义意图组,再收集其对应的槽位标签,完成意图和槽位数据的设计。然后从开源知识图谱中直接收集KG信息,从真实业务中的UP和CA模式中筛选出可以帮助消除用户话语歧义的UP和CA条目。
接着我们从互联网爬取不同槽位的候选槽值集合,但是由于歧义名称难以直接从互联网收集,标注人员也很难直接给出,因此我们通过知识图谱对歧义名称进行收集。知识图谱中存在着大量的歧义名称,每个歧义名称对应着许多实体。这些实体具有不同的实体类型,但是却共享同样的名称。例如歌曲实体Monkey King和中文卡通实体Monkey King就是具有不同实体类型,但却共享同样的名称。
接下来我们开始构建数据:
对于歧义描述的情况,我们首先随机选择一个意图,以及该意图对应的槽位标签集中的部分槽位。然后通过从收集的槽值集合中随机选择槽值来填充对应的槽位。接着从知识图谱中提取槽值的KG信息。最后基于设计好的启发式规则,为相应的意图生成合理的UP和CA信息。
对于歧义名称的情况,我们还需要在选取意图和槽位后,随机选择一个满足已选择意图的歧义名称。
最后,我们雇佣标注者来检查每个数据集样本的生成数据是否合法,然后要求标注者基于给定的意图和槽值对,完成歧义话语的编写。最重要的是,标注者写出的用户话语,必须是合理的、符合逻辑的,但同时是具有语义歧义的。
 图7 数据集的构建流程
图7 数据集的构建流程
数据集的构建流程如图7所示:我们通过开源知识图谱和互联网数据完成了初步的数据收集,又设计了数据构建流程,完成了意图、槽值对以及Profile信息的初步构建,最后由标注者完成用户话语的编写。
5. 实验
本文基于现有SLU模型中的主要组件,构建了通用SLU模型,它由共享的编码器,意图识别解码器和槽位填充解码器构成。接着本文结合层次化注意力融合机制,设计了多层次知识适配器,从而分别在句子级和词级融入Profile信息,并且可以作为插件,轻松集成到现有SLU模型中。
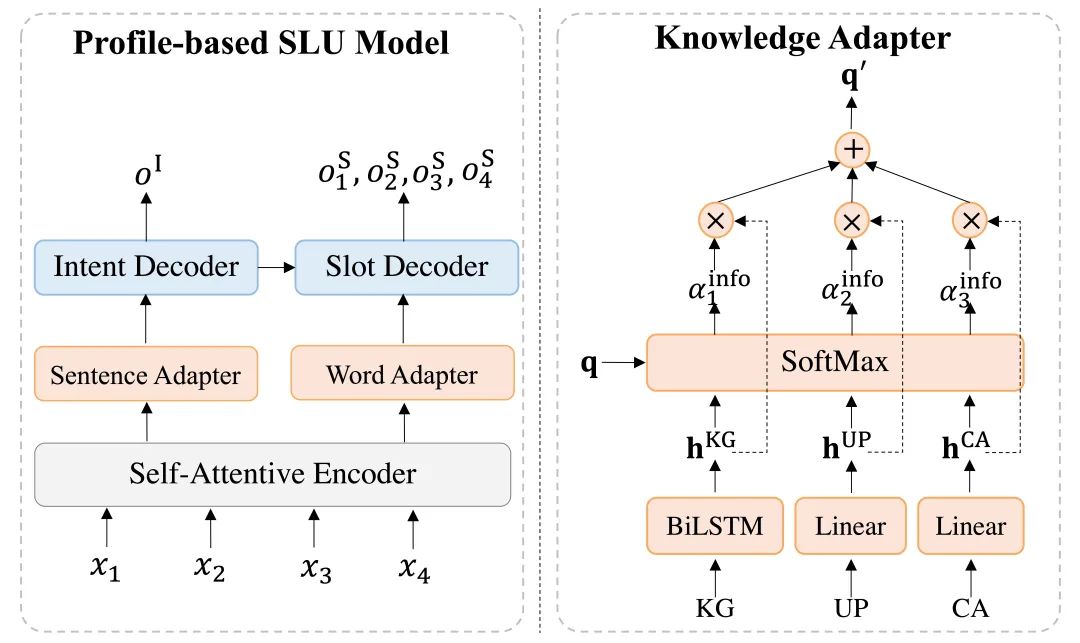 图8 模型架构图
图8 模型架构图
模型架构如图8所示,知识适配器分别在句子级和词级引入Profile信息,从而多层次的引入Profile信息,帮助消除话语中的歧义。
表1 SLU实验结果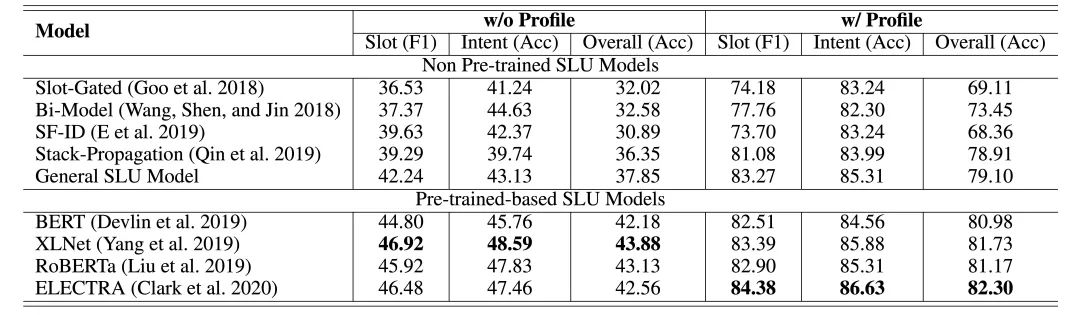
我们对现有的SLU Baseline进行了充分的实验,表中的第二大列和第三大列分别对应基于纯文本的SLU模型和借助我们设计的多层次知识适配器来引入Profile信息的ProSLU模型。在没有Profile信息时,现有的SLU模型都表现的很差;将共享的编码器替换为预训练语言模型后,模型性能得到一定提升,但是其overall acc仍然低于45,表现还是很不好。而在引入了Profile信息后:
所有的SLU Baseline都取得了显著的效果提升,这充分证明了我们提出的ProSLU任务的重要性,以及Profile信息对解决用户话语中的歧义的有效性
所有的预训练SLU模型在引入了Profile信息后,也同样取得了显著的效果提升,这证明Profile信息和预训练语言模型的结合,能够有效提升效果
6.未来挑战
ProSLU任务还存在着许多挑战:
KG信息的表示:知识图谱实体数量庞大,实体属性信息稀疏且复杂
Profile信息的融合:更加高效的信息融合方式,具有可扩展性的Profile信息融合方式
Profile信息的扩展:更多有注意消除语义歧义的Profile信息
未来我们将继续探索如何面对上述挑战。
7. 结论
本文研究基于Profile的口语语言理解任务,它要求模型不仅要依赖于用户话语本身,还要借助辅助Profile信息,更好的完成语义框架表示信息的提取。为此,本文标注了大约五千条数据的大规模中文数据集,以促进本领域进一步的研究,并探索了,使用多层次知识适配器来有效地引入辅助Profile信息,实验表明,通过知识适配器引入Profile信息的方式,能够有效提升SLU模型在ProSLU任务上的表现。
欢迎大家共同推动 Profile-based SLU 领域的研究进展!
本期责任编辑:丁 效
本期编辑:钟蔚弘
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









