






每天给你送来NLP技术干货!
来自:NLP日志
提纲
1 简介
2 DualTrain+SharedProj
3 DistilBERT
4 LSTM
5 PKD
6 TinyBert
7 MOBILEBERT
8 总结
参考文献
1 简介
预训练模型BERT以及相关的变体自从问世以后基本占据了各大语言评测任务榜单,不断刷新记录,但是,BERT庞大的参数量所带来的空间跟时间开销限制了其在下游任务的广泛应用。基于此,人们希望能通过Bert得到一个更小规模的模型,同时基本具备Bert的能力,从而为下游任务的大规模应用提供可能性。目前许多跟Bert相关的蒸馏方法被提出来,本章节就来分析下这若干蒸馏方法之间的细节以及差异。
知识蒸馏由两个模型组成,teacher模型跟student模型,一般teacher模型规模跟参数量都比较庞大,所以能力更强,而student模型规模比较小,如果直接训练的话效果比较有限,所以是先训练teacher模型,让它学到充足的知识,然后用student模型去学习teacher模型的行为,从而实现将知识从teacher模型转移到student模型,使得student模型能在较小的参数量的同时具备接近大模型的能力。在蒸馏过程中,最常见的student模型部分的loss,就是对于同一个数据,将teacher模型的预测的soft概率作为ground truth,让teacher模型去学习从而预测得到相同的结果,这部分teacher模型跟student模型预测的概率之间距离就是蒸馏最常见的loss(通常是交叉熵)。蒸馏学习希望student模型学到teacher模型的能力,从而预测的结果跟teacher模型预测的soft概率足够接近,也就是希望这部分的loss尽可能的小。
2 DualTrain+SharedProj
以往的知识蒸馏虽然可以有效的压缩模型尺寸,但很难将teacher模型的能力蒸馏到一个更小词表的student模型中,而DualTrain+SharedProj解决了这个难题。它主要针对Bert的词表大小跟嵌入纬度做了缩简,其余部分,包括模型结构跟层数保持跟teacher模型(Bert Base)一致,从而实现将知识从teacher模型迁移到student模型中。
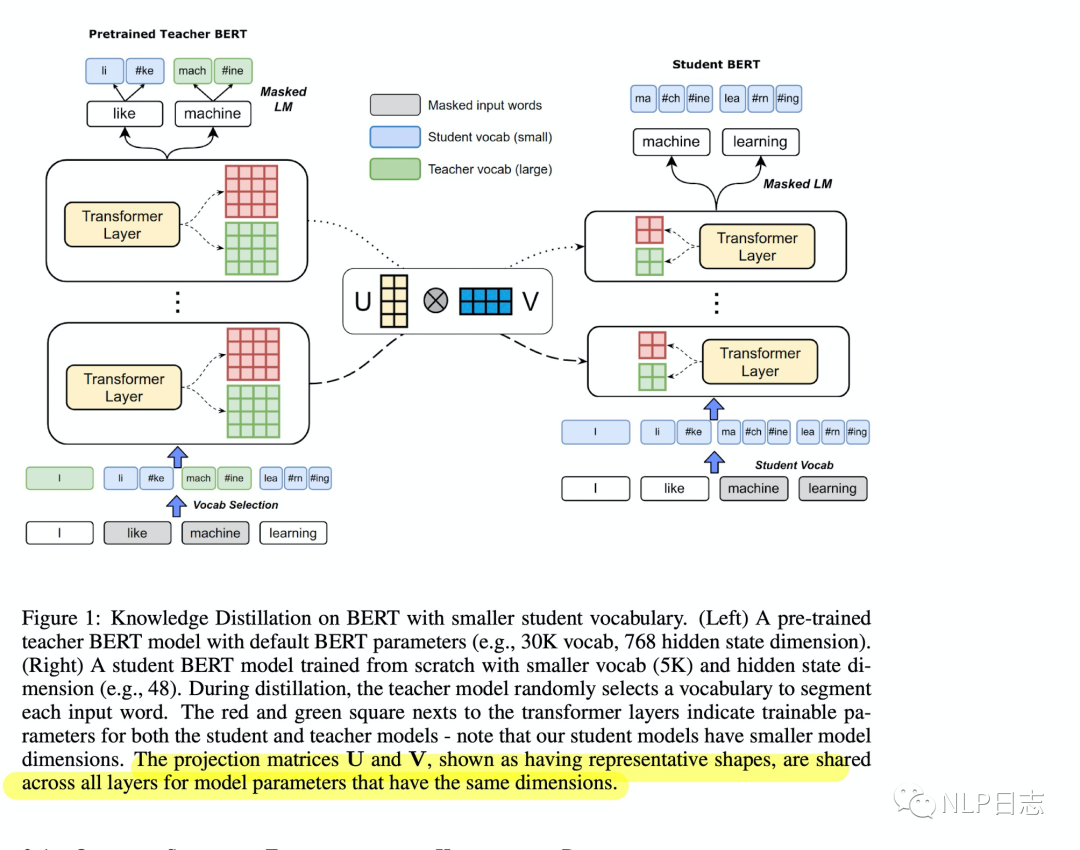
图1: DualTrain+SharedProj框架
区别于其他蒸馏方法,DualTrain+SharedProj有两个特别的地方,一个是Dual Training, 另一个是Shared Projection。Dual Training主要是为了解决teacher模型跟student模型不共用词表的问题,在蒸馏过程中,对于teacher模型,会随机选择teacher模型或者student模型的词表去进行分词,可以理解就是混合了teacher模型跟student模型的词表,这种方式可以对齐两个规模不同的的词表。例如图中左边部分,I和machine用的是teacher模型的分词结果而其余token用的是student模型的分词结果。第二部分是Shared Projection,这部分很好理解,因为student模型嵌入层纬度缩小了,导致每个transformer层的纬度都缩小了,但是我们希望student模型跟teacher模型的transformer层的参数足够接近,所以这里需要一个可训练的矩阵将两个不同维度的transformer层参数缩放到同一个维度才能进行比较。如果是对teacher模型的参数进行缩放,就叫做down projection,如果是对student模型参数进行的缩放,就叫做up projection。同时,12层的transformer参数共用同一个缩放矩阵,所以叫做shared projection。例如下图,下标t,s分别代表teacher模型跟student模型。

图2: up projection损失

图3: DualTrain+SharedProj的损失函数
在蒸馏过程中,会将teacher模型跟student模型都在监督数据上进行训练,将两个模型预测结果的损失加上两个模型之间transformer层的参数之间的距离的损失作为最终损失,去更新student模型的参数。最终实验效果可也表明,随着student模型的隐藏层纬度缩减得越厉害,模型的效果也会逐渐变差。
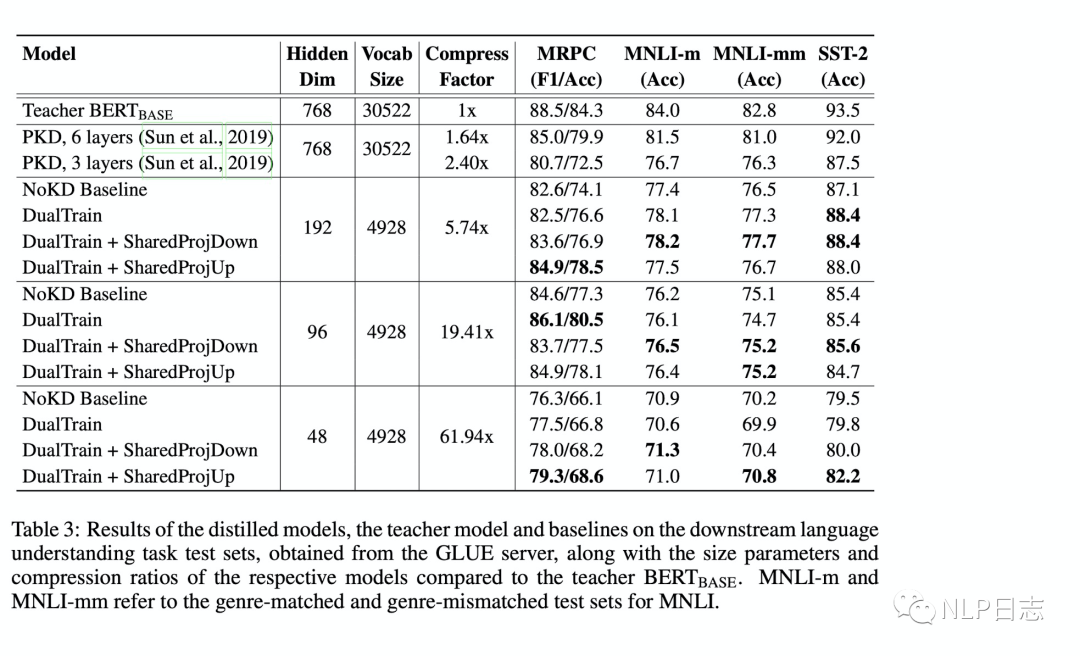
图4: DualTrain+SharedProj的实验效果
DualTrain+SharedProj是很少见的student模型跟teacher模型不共享词表的一种蒸馏方式,通过缩小词表跟缩减嵌入层纬度,可以很大程度的减少模型的尺寸。同时也要注意,尺寸缩小得厉害,student模型的效果也下降地越厉害。另外有一点我不太理解,只通过一个dual training过程就可以对齐两个词表了吗?是不是要蒸馏开始之前先对teacher模型,混合两个词表的分词结果做下预训练会更加合理?
3 DistillBERT
DistilBERT是通过一种比较常规的蒸馏方法得到的,它的teacher模型依旧是Bert Base, DistilBERT沿用了Bert的结构,但是transfromer层数只有6层(Bert Base有12层),同时还将嵌入层token-type embedding跟最后的pooling层移除。为了让DistilBERT有一个更加合理的初始化,DistilBERT的transformer参数来源于Bert Base,每隔两层transformer取其中一层的参数来作为DistilBERT的参数初始化。
在蒸馏过程中,除了常规的蒸馏部分的loss,还加入了一个自监督训练的loss(MLM任务的loss),除此之外,实验还发现加入一个词嵌入的loss有利于对齐teacher模型跟student模型的隐藏层表征。
DistilBERT是一种常见的通过蒸馏得到的方法,基本上是通过减少transformer的层数来减少模型尺寸,同时加速模型推理的。
4 LSTM
蒸馏学习并不要求teacher模型跟student模型要隶属于同一种模型架构,于是就有人脑洞大开,想用BiLSTM作为student模型来承载Bert Base庞大的能力。这里的teacher模型依旧是Bert Base,student模型分为三个部分,第一部分是词嵌入层,第二部分是双向LSTM+pooling,这里会将BiLSTM得到的隐藏层状态通过max pooling生成句子的表征,第三部分是全连接层,直接输出各个类别的概率。
在蒸馏开始之前,需要先在特定任务的监督数据集上对teacher模型进行微调,因为是分类任务,所以Bert Base跟后面的全连接层会一起更新参数,从而让teacher模型适配下游任务。在蒸馏过程中,student模型的损失分为三部分,第一部分依旧是常规的根据teacher模型预测的soft概率跟student模型预测的概率之间的交叉熵损失。第二部分是在监督数据下student模型预测的结果跟真实标签结果之间的交叉熵损失。第三部分是teacher模型跟student模型生成表征之间的KL距离,也就是BiLSTM+pooling跟Bert base最后一层状态输出之间的距离,但是由于这两者可能维度不一样,所以这里也需要引入一个全连接层来缩放。
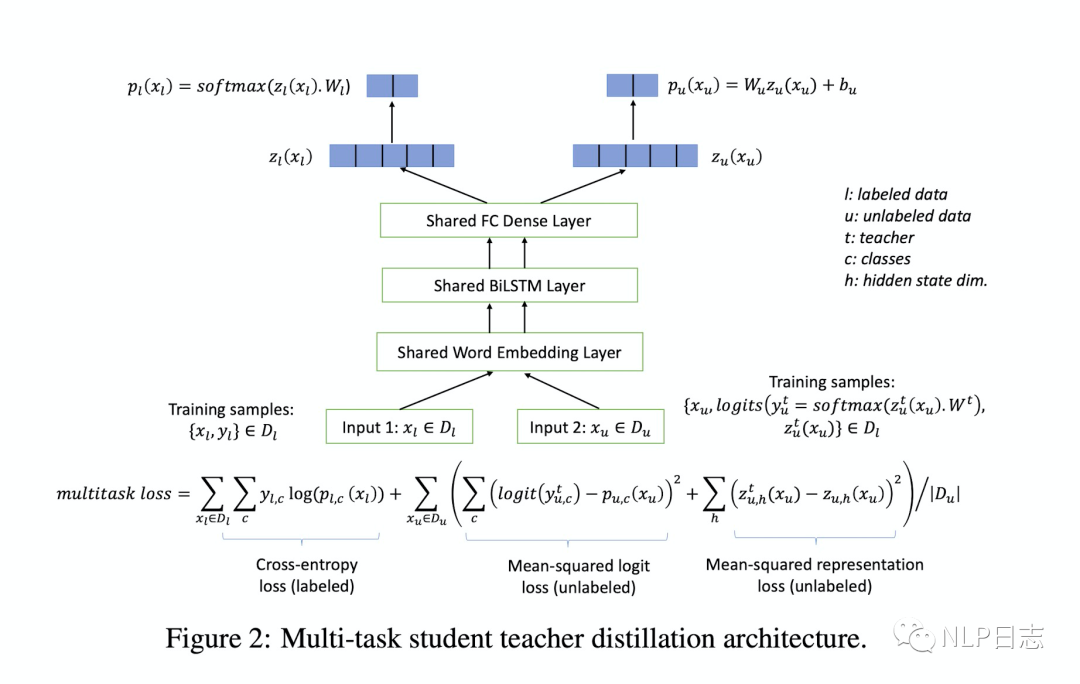
图5: BiLSTM的蒸馏过程

图6: BiLSTM蒸馏的效果对比
可以看得到通过蒸馏得到的BiLSTM明显优于直接finetune的,这里证明了蒸馏学习的有效性。除此之外,BiLSTM本身的准确率就很高了,说明任务比较简单(要不然蒸馏过后的BiLSTM准确率比teacher模型Bert Base还高不是很诡异嘛?),所以并不能说明把Bert Base蒸馏到BiLSTM是个合适的选择。LSTM本身结构的局限性导致了很难完全学习到transformer的知识跟能力,笔者以前也在一些比较难的数据集上尝试过类似的做法,但是最终作为student模型的LSTM的效果跟teacher模型的之间的差距还是比较大,并且泛化能力比较差。
5 PDK
PKD想通过蒸馏学习将Bert Base的transformer层数进行压缩,但是常规的方式只学习teacher模型最后一层的结果,虽然能在训练集上取得可以媲美teacher模型的效果,但是在测试集的表现很快就收敛了。这种现象看起来像是在训练集上过拟合了,从而影响了student模型的泛化能力。基于此,PKD在原本的基础上加上了新的约束项,驱使student模型去学习模仿teacher模型的中间过程。具体的有两种可能方式,第一种就是让student模型去学习teacher模型transformer每隔几层的结果,第二种是让student模型去学习teacher模型最后几层transformer的结果。
蒸馏过程的损失函数包括三个部分,第一部分还是常规的teacher模型预测的soft概率和student模型预测结果之间的交叉熵损失,第二部分是student模型预测概率跟真实标签之间的交叉熵损失,第三部分就是teacher模型跟student模型之间中间状态的距离,这里用的[CLS]位置的表征。
6 TinyBert
TinyBert的特别之处在于它的蒸馏过程分为两个阶段。第一阶段是通用蒸馏,teacher model是预训练好的Bert, 可以帮助TinyBert学习到丰富的知识,具备强大的通用能力,第二阶段是特定任务蒸馏,teacher moder是经过finetune的Bert, 使得TinyBert学习到特定任务下的知识。两个蒸馏环节的设计,能保证TinyBert强大的通用能力跟特定任务下的提升。
在每个蒸馏环节下,student模型的蒸馏分为三个部分,Embedding-layer Distillation,Transformer-layer Distillation, Prediction-layer Distillation。Embedding-layer Distillation是词嵌入层的蒸馏,使得TinyBert更小维度的embedding输出结果尽可能的接近Bert的embedding输出结果。Transformer-layer Distillation是其中transformer层的蒸馏,这里的蒸馏采用的是隔k层蒸馏的方式。也就是,假如teacher model的Bert的transformer有12层,如果TinyBert的transformer设计有4层,那么就是就是每隔3层蒸馏,TinyBert的第1,2,3,4层transformer分别学习的是Bert的第3,6,9,12层transformer层的输出。Prediction-layer Distillation主要是对齐TinyBert跟Bert在预测层的输出,这里学习的是预测层的logit,也就是概率值。前面两部分的损失都是MSE计算,因为teacher模型跟student模型在嵌入层跟隐藏层的维度不一致,所以这里需要相应的线性映射将student模型的中间输出映射到跟teacher 模型一样的维度,最后一部分的损失是通过交叉熵损失计算的。通过这三部分的学习,能保证TinyBert在中间层跟最后预测层都学习到Bert相应的结果,进而保证准确率。
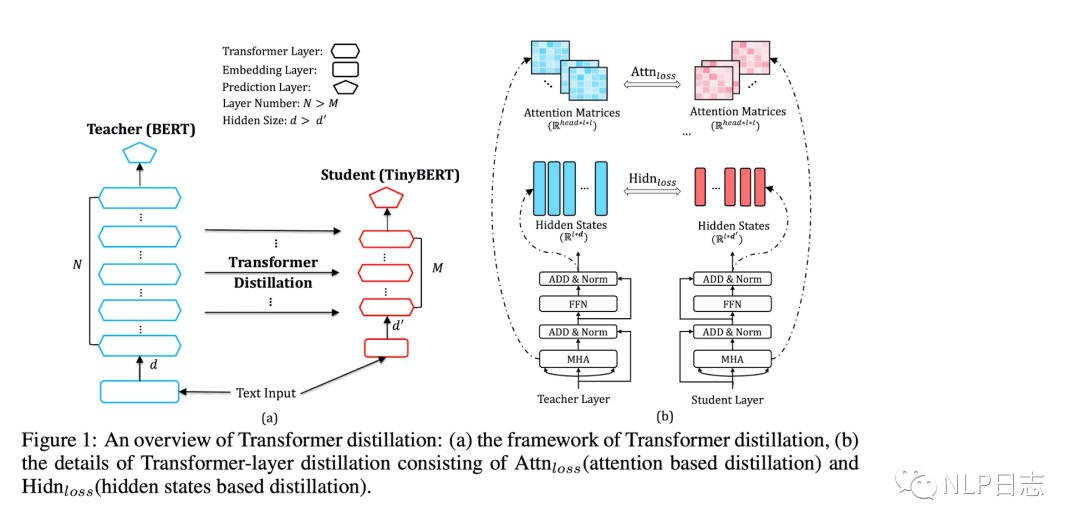
图7: TinyBert框架
TinyBert的两阶段蒸馏过程能驱使student模型能学到teacher模型的通用知识和特定领域知识,保证student模型在下游任务的表现,是很值得借鉴的一种训练技巧。
7 MOBILEBERT
MOBILEBERT可能是目前性价比最高的一种蒸馏方式了(可能是笔者眼界有限),无论是从学习的目标,还是整个训练的方式,考虑都很周全。MOBILEBERT的student模型跟teacher模型的网络层数保持一致,相关的模型结构有所变化,首先是student模型跟teacher模型都新增了bottleneck,用于缩放内部表示尺寸,在后面loss部分会展开介绍,其次是student模型里将FFN改成堆叠的FFN,最后是移除了layer normalization跟将激活函数由gelu换成relu.
在蒸馏过程中,student模型的损失包括两个部分。第一个部分是student模型和teacher模型之间的feature map的距离,这里的feature map指的是每一层transformer输出的结果。在这里,为了能让student模型的隐藏层维度比teacher模型的隐藏层维度更小从而实现模型压缩,这里的student模型跟teacher模型的transformer结构都加入了bottleneck,也就是图中绿色梯形的部分,通过这些bottleneck可以对文本表征尺寸进行缩放,从而实现teacher模型跟student模型各自在每一个transformer内部表示尺寸不同,但是输入和输出尺寸一致,所以就可能用内部表示尺寸小的student模型去学习内部表示尺寸大的teacher模型的能力跟知识。第二部分是两个模型每一层transformer中attention的距离,这部分loss是为了利用self attention从teacher模型中学习到相关内容从而更好得学习到第一部分的feature map。
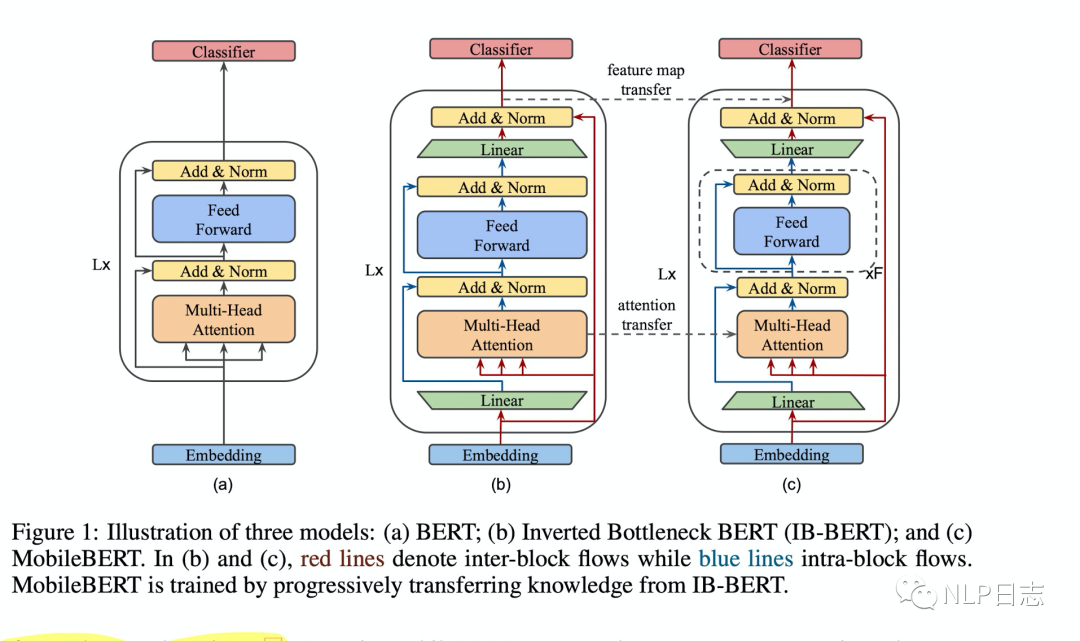
图8: MOBILEBERT相关的网络结构
MOBILEBERT的蒸馏过程是渐近式的,在蒸馏学习第L层的参数时会固定L层以下的参数,一层一层的学习teacher模型的,直到学完全部层数。

图9: MOBILEBERT的渐近式知识迁移过程
在完成蒸馏学习后,MOBILEBERT还会在做进一步的预训练,预训练有三部分的loss,第一部分跟第二部分是BERT预训练的MLM跟NSP任务的loss,第三部分是teacher模型跟student模型在[MASK]位置的预测概率之间的交叉熵损失。
8 总结
为了直观的对比上面提及的蒸馏方法的压缩效率和模型效果,我们汇总了若干种模型的具体信息以及在MRPC数据集上的表现。总体来说,有以下一些相关结论。
a) 压缩效率越高往往会伴随着模型效果的持续下降。
b) Student模型的上限就是teacher模型。对于同一个student模型,并不是teacher模型越大student模型效果就会越好。因为越大的teacher模型,意味着更大的压缩效率,也意味着更严重的性能下降。
c) 只学习teacher模型最后的预测的soft概率是远远不够的,需要对teacher模型中间的表征或者参数也进行学习,才能进一步保证student模型的效果。
d) 缩减transformer层数或者缩减隐藏层状态纬度都可以压缩模型,对于缩减隐藏层状态维度,用MOBILEBERT那种bottleneck的方式优于常规的通过一个额外的映射来对齐模型尺寸的方式。缩减隐藏层状态维度的方式的模型压缩效率的上限更高。
e) 渐进性学习方式是有效的。也就是固定下层的参数,只更新当前层的参数,依次迭代直至更新完student模型全部层。
f) 分阶段蒸馏是有效的。先学习通用的teacher模型,然后再学习特定任务下finetune的teacher模型。
g) 跨模型结构的蒸馏是有效的。用BiLSTM来学习Bert Base的能力比直接finetune BiLSTM的效果要好。
Model | type | Compress Factor | MRPC(f1) |
Bert Base | 1 | 88.9 | |
DualTrain+SharedProjUp | 192 96 48 | 5.74 19.41 61.94 | 84.9 84.9 79.3 |
DistilBERT | 1.67 | 87.5 | |
PKD | 6 3 | 1.64 2.40 | 85.0 80.7 |
TinyBert | 4 | 7.50 | 86.4 |
MOBILEBERT | 4.30 | 88.8 |
参考文献
1. (2020) EXTREME LANGUAGE MODEL COMPRESSION WITH OPTIMAL SUBWORDS AND SHARED PROJECTIONS
https://openreview.net/pdf?id=S1x6ueSKPr
2. (2020) DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
https://arxiv.org/abs/1910.01108
3. (2020) DISTILLING BERT INTO SIMPLE NEURAL NETWORKS WITH UNLABELED TRANSFER DATA
https://arxiv.org/pdf/1910.01769.pdf
4. (2019) Patient Knowledge Distillation for BERT Model Compression
https://arxiv.org/pdf/1908.09355.pdf
5. (2020) TINYBERT: DISTILLING BERT FOR NATURAL LAN- GUAGE UNDERSTANDING
https://openreview.net/attachment?id=rJx0Q6EFPB&name=original_pdf
6. (2020) MOBILEBERT: TASK-AGNOSTIC COMPRESSION OF BERT BY PROGRESSIVE KNOWLEDGE TRANSFER
https://openreview.net/pdf?id=SJxjVaNKwB
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】整理不易,还望给个在看!














 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









