






每天给你送来NLP技术干货!

来自: 哈工大深圳人类语言技术研究团队
2022年10月6日,EMNLP 2022 (The 2022 Conference on Empirical Methods in Natural Language Processing) 录用结果公布,研究团队共有九篇论文被录用,四篇被主会录用,五篇被Findings of EMNLP录用。EMNLP 2022将于2022年12月7日至11日以混合形式在阿联酋阿布扎比(Abu Dhabi)举行。EMNLP是自然语言处理领域的国际顶级学术会议,在中国计算机学会推荐会议列表为B类会议,由ACL SIGDAT(语言学数据特殊兴趣小组)主办。
被录用论文简介如下:
标题:A Generative Model for End-to-End Argument Mining with Reconstructed Positional Encoding and Constrained Pointer Mechanism.
作者:Jianzhu Bao#, Yuhang He#, Yang Sun, Bin Liang, Jiachen Du, Bing Qin, Min Yang and Ruifeng Xu*
类别:Main Conference.
论辩挖掘(Argument Mining, AM)是一项具有挑战性的任务,因为它的目的是识别复杂的论辩结构,同时涉及多个子任务。为了以端到端的方式解决论辩挖掘的所有子任务,前人的工作通常将其转化为一个依存分析任务。然而,这些方法在很大程度上需要复杂的前处理和后处理来实现任务转换。本文提出一个生成式框架来解决端到端的AM任务,其中任务的输出被设定为一个简单的目标序列。然后,采用预训练语言模型和受限的指针机制来通过目标序列对AM的所有子任务进行建模。此外,还设计了一个重构位置编码策略来缓解自回归生成范式所引起的顺序偏差。实验结果表明,所提出的框架在两个AM数据集上都达到了最优的性能。

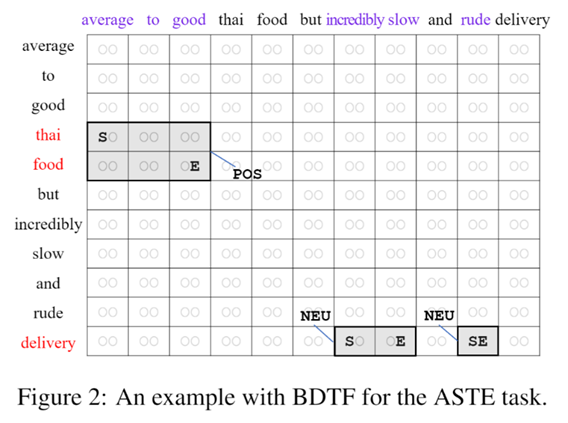
标题:Boundary-Driven Table-Filling for Aspect Sentiment Triplet Extraction
作者:Yice Zhang, Yifan Yang, Yihui Li, Bin Liang , Shiwei Chen, Yixue Dang, Ming Yang, and Ruifeng Xu*
类别: Main Conference.
简介:本文针对以往方面情感三元组抽取方法中存在的情感不一致和边界不敏感的问题,提出了一个边界驱动的表格填充方法。该方法将方面情感三元组转化为二维表中的一个关系区域,进而将方面情感三元组抽取任务转化为关系区域的检测和分类任务。此外,本文设计了一个有效的表格表示学习方法,用来支持所提出的表格填充方法。实验表明,所提出方法优于现有方法,而且显著地减少了以往表格填充方法中存在的边界错误和关系错误。
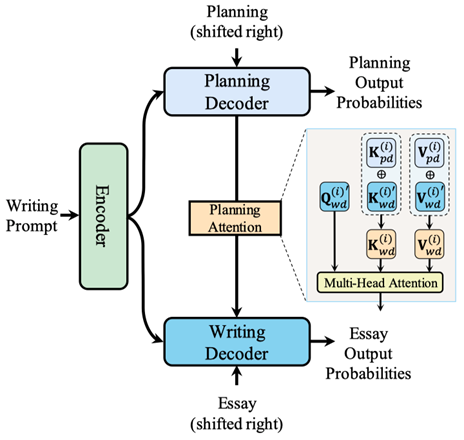
标题:AEG: Argumentative Essay Generation via A Dual-Decoder Model with Content Planning
作者:Jianzhu Bao, Yasheng Wang, Yitong Li, Fei Mi and Ruifeng Xu*
类别:Main Conference.
简介:现有的论辩生成相关研究主要集中在生成单个的、短的论据上,鲜少有研究探索生成长而连贯的议论性文章。本文提出了一个新的任务—议论文生成(Argumentative Essay Generation, AEG)。给定一个写作题目,AEG的目标是自动生成一篇具有强说服力的议论文。我们为这个新任务构建了一个较大的数据集ArgEssay,并建立了一个基于双解码器Transformer架构的基线模型。我们提出的模型包含两个解码器,一个规划解码器(Planning Decoder, PD)和一个写作解码器(Writing Decoder, WD),其中PD用于生成内容规划,WD结合规划信息来写一篇文章。在一个大型的新闻数据集上对这个模型进行预训练,以增强这种先规划-后写作的范式。自动和人工评估结果表明,提出的模型可以生成更连贯、更有说服力的文章,同时具有更高的多样性和更少的重复性。
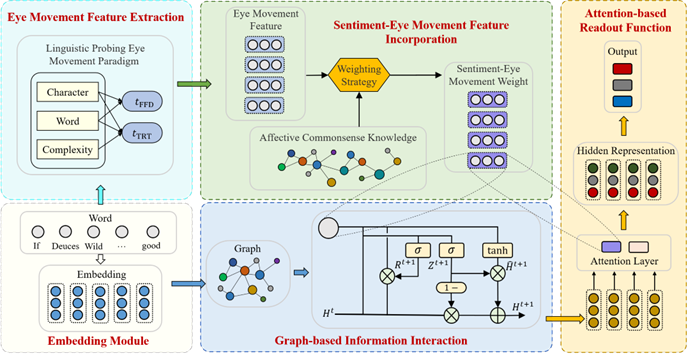
标题:SEMGgraph: Incorporating Sentiment Knowledge and Eye Movement into Graph Model for Sentiment Analysis
作者:Bingbing Wang, Bin Liang, Jiachen Du, Min Yang, Ruifeng Xu*
类别:Main Conference.
简介:本文从一个新的角度研究了情感分析任务,将情感知识和眼动特征融入到图结构中,旨在构建基于眼动特征的情感关系,以更好地学习上下文的情感表达。具体来说,首先基于语言特征与人类早期和晚期阅读过程的密切关系,提出了一个语言探测眼动范式以提取眼动特征。此外,进一步设计了一种新的加权策略,将从情感知识中获得的情感分数与眼动特征结合,得到情感眼动权重。然后,基于情感眼动权重构建sentiment-eye movement guided graph(SEMGgraph)模型,对上下文中复杂的情感关系进行建模。在两个有眼动特征的情感分析数据集和三个没有眼动特征的情感分析数据集上的实验结果表明,本文所提出的SEMGgraph模型可以取得明显的改进,并且具有良好的泛化性。
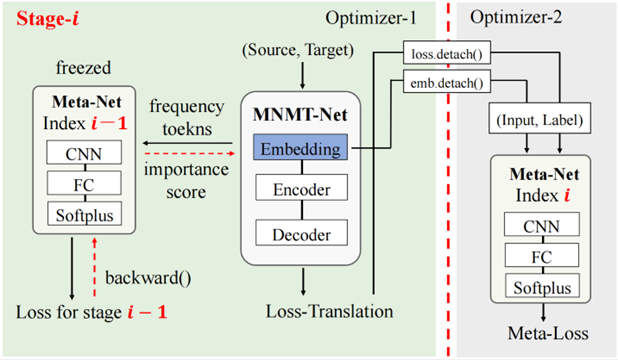
标题:CLLE: A Benchmark for Continual Language Learning Evaluation in Multilingual Machine Translation
作者:Han Zhang, Sheng Zhang, Yang Xiang, Bin Liang, Jinsong Su, Zhongjian Miao, Hui Wang, and Ruifeng Xu*
类别:Findings of EMNLP
简介:该工作提出一种语言可持续学习的机器翻译评估基准CLLE,并定义了两种语言可持续学习的机器翻译任务—近距离语言持续学习(CLCL)与语系持续学习(LFCL)。 通过多语言检索模型的方法对CC-Matrix数据集进行过滤,通过主题对齐得到了以中文和英文为核心的覆盖25种语言的多语翻译数据集CN-25和EN-25。提出了基于元学习与限制优化的语种持续学习框架COMETA。在COMETA框架中元模型可以预测翻译模型的参数重要性权重,以此保护旧语言在持续学习时不被遗忘。
标题:MCPG: A Flexible Multi-Level Controllable Framework for Unsupervised Paraphrase Generation
作者:Yi Chen, Haiyun Jiang, Rui Wang, Lemao Liu, Shuming Shi and Ruifeng Xu*
类别:Findings of EMNLP.
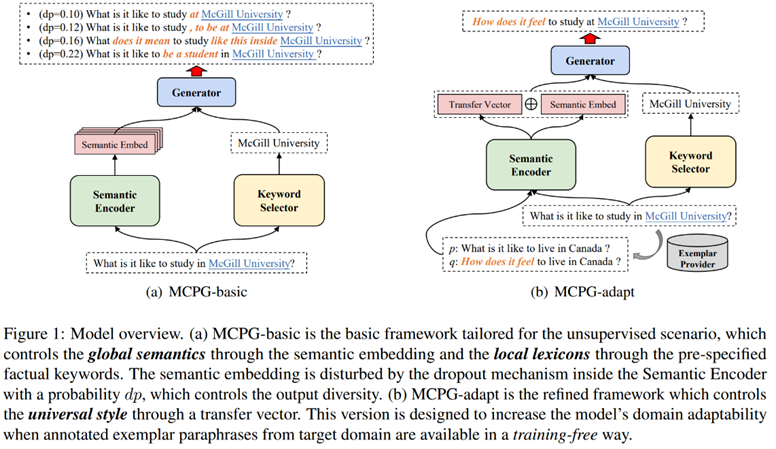
简介:可控复述生成方法是当前的一个研究热点,但以往方法往往受平行语料的限制,难以泛化到不同的目标领域,或只考虑单一维度的控制信号。本文从人类认知角度出发,提出一种在全局语义、局部词汇和总体表达形式上多级可控的无监督复述生成框架。该框架还可在不经过额外训练的情况下,利用少量标注数据泛化到特定的目标领域。在无监督场景下,该方法在三个公开数据集上均取得了SOTA性能。在有平行语料时,该方法可以在无需经过额外的有监督训练的情况下,即可表现出和有监督基线模型相当的性能。
标题:Mask-then-Fill: A Flexible and Effective Data Augmentation Framework for Event Extraction
作者:Jun Gao,Changlong Yu,Wei Wang,Huan Zhao,Ruifeng Xu*
类别:Findings of EMNLP
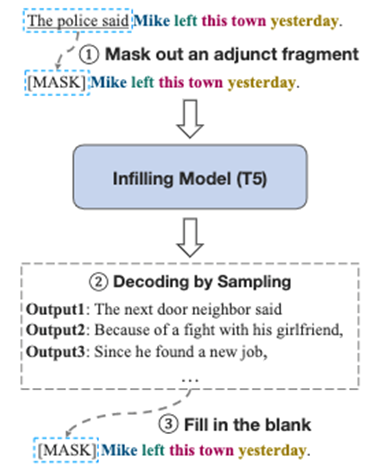
简介:事件抽取模型经常面临着数据缺乏的问题,数据增强是解决这个问题的一个重要方法。现有针对事件抽取的数据增强方法大多基于一些多样性较低的编辑操作如词替换、删除、插入等。本文基于文本填充,提出一种灵活且有效数据增强框架。所提方法相比之前的数据增强方法能够提供对本文进行更加灵活的编辑,从而在提升数据多样性同时,保持事件结构尽可能不被破坏。具体而言,该方法首先针对一个输入样本随机删除一个非事件相关的文本片段,再基于一个文本填充模型(如T5)对其进行填充。该方法的主要优势在于,它可以将样本中任意长度的文本片段替换为另一个长度可变的文本片段,而现有的方法只能替换单个单词或固定长度的片段。在事件的Trigger和Argument提取任务上,本文所提出的框架比Baseline方法更有效,而且在低资源场景下显示出特别强的效果。进一步分析表明,该方法在多样性和数据分布相似性之间实现了良好的平衡。
标题:Probing Structural Knowledge from Pre-trained Language Model for Argumentation Relation Classification
作者:Yang Sun, Bin Liang, Jianzhu Bao, Min Yang, and Ruifeng Xu*
类别:Findings of EMNLP
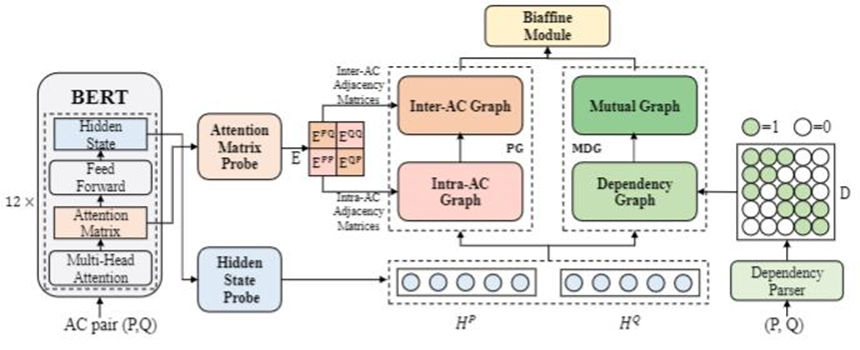
简介:建模论辩部件对之间的细粒度结构信息对于论辩关系分类任务至关重要。然而,以往的研究大多试图利用论辩部件级的相似性或语义相关特征来建立模型,但忽略了论辩部件对之间复杂的交互,不能有效地对论辩关系进行深入推理。本文提出一种对偶先验图神经网络,通过结合来自预训练语言模型的探测知识和句法信息,全面地对论辩部件对之间的关系进行建模。具体地,使用来自预训练模型的探测知识构建探测图,以识别和对齐论辩部件内部和之间的语义关系。此外,为论辩部件对构建一个互依赖图推理细粒度的句法结构信息,其中词与词之间的句法相关性是由论辩部件对内部的依赖信息和用于论辩部件对的互注意力机制获得。通过结合探测图和依赖图中学习到的结构知识,更全面地获取论辩部件对的对齐关系,以提高论辩关系分类的结果。
标题:Masked Language Models Know Which are Popular: A Simple Ranking Strategy for Commonsense Question Answering
作者:Xuan Luo, Chuang Fan, Yice Zhang, Wanguo Jiang, Bing Qin and Ruifeng Xu*
类别:Findings of EMNLP

简介:不同于选择式问答,数据集ProtoQA提出了新的任务。即给定一个典型场景下的常识问题,由模型给出尽可能覆盖不同类别的合理答案,且优先更为典型的答案。对于该多答案的常识问答生成任务,本文研究掩码模型能否帮助模型提升生成答案的典型性。实验结果表明将典型指数直接用于掩码模型的训练,可以大幅度提升其区分典型答案和非典型答案的能力。此外,采用三种不同的策略从WordNet中为每个答案选取负样本,在训练阶段从中随机采样若干负样例,有效加强了掩码模型的判别能力。进一步地,探索通过强化学习直接提升自回归语言模型建模的潜力。该模型优异的性能表现有力证明了掩码语言模型和自回归语言模型的结合在生成式问答任务上的强大优势。
审稿:徐睿峰
校正:王 丹
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~














 4857
4857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









