






来自:AI算法小喵 公众号
写在前面
好久不见,今天小喵要跟大家分享一篇23年2月的论文《REPLUG: Retrieval-Augmented Black-Box Language Models》[1],这么热乎的文章,建议大家先收藏再看。
23年的这篇论文提出了检索增强的新范式,即REPLUG。它将语言模型当作一个黑盒子,即冻结语言模型的参数不再优化,转而去优化检索组件让检索组件来适配语言模型,以此来消除语言模型的“幻觉”,减少事实性错误的生成。
关键词:检索增强、向量检索、困惑度、幻觉、事实性错误
1. LLM的幻觉
GPT-3等LLM(large language models,大语言模型)能力很强,在各个任务上都有非常不错的表现。但是,在LLM强大的背后,有着很多不能被忽视的缺陷。
首先,LLM对资源的要求高。比如,假设我们微调BLOOM-176B,就需要72张显存为80GB的A100显卡。没钱没资源或者资源有限的我们除流下两行热泪外,也可以退而求其次,去使用一些小模型(附:GPT-1到GPT-3的参数量是越来越大,从5GB到45TB,你仔细品一品这个趋势😂)。
LLM的另一个问题是生成文本中的事实性错误。在闲聊场景下,大家对这种事实性错误的容忍度还比较高,顶多笑一笑,在微信上和自己的朋友嘀咕两句,或者转头跟同事调侃一下“也不过如此”而已;可是在非闲聊场景下,比如医学、金融、军事等,事实性错误就是不可容忍的。在这些场景下落地,要求通常都是非常苛刻的,否则后果难以承受。针对这个问题,我们则要想办法去消除大模型中的事实错误。
LLM的事实性错误有一个更通用的术语叫“幻觉”(Hallucination)。“幻觉”一词最早用于图像合成等领域,后来在图像检测中用于描述检测到的虚假或错误目标等。在自然语言生成 (NLG) 任务中,“幻觉“是用来指代我们所说的"事实性错误"。
2. 检索增强范式的转变
2.1 “白盒”式检索增强
语言模型生成的文本自然流畅、语法正确,就像人说出来的一样。但实际上,可能毫无意义并且包含虚假信息。这样的文本以假乱真,就像人产生的幻觉一样。针对这个问题,学术界也有相应的解决办法,即检索增强。
其实,检索方法的重度使用区是开放域问答,近几年关于开放域问答的研究多采用“信息检索+机器阅读理解”二阶段范式:
检索器从已有知识库(如维基百科等网页)中找到相关知识;
利用机器阅读理解算法从相关知识中找到问题的答案。
同样地,在文本生成领域,检索增强语言模型的范式通常也包含两个步骤:
检索器根据用户query(用户输入)从已有知识库获得相关知识;
生成器根据用户query和检索到的辅助知识进行最终预测。
在以往的检索增强范式下,语言模型通常都被当作“白盒”,简单地说就是我们要么优化它们的参数(比如Atlas联合优化了检索器和语言模型),要么获得其表征。考虑到大语言模型对资源的要求,这条路线的代价是比较大的。
除此以外,还有一点让“白盒”的“白”不可行:很多大语言模型并没有开源。比如,我们目前只能通过网页或者OpenAI提供的API去访问ChatGPT,这种未开放的大模型自然是无法微调的。在这种情形下,语言模型倒更像一个“黑盒”,我们只能喂给它们输入,然后从它们那里获得结果。
总的来说就是,越来越大的语言模型规模和语言模型的黑盒特性使得白盒这种检索增强范式不可行。
2.2 “黑盒”式检索增强
今天我们要分享的这篇工作所提出的 REPLUG 模型可以说是“黑盒”式检索增强的代表。在这种新范式下,语言模型是一个黑盒子(它的参数被冻结了,不会被更新优化),检索组件才是可微调的部分。
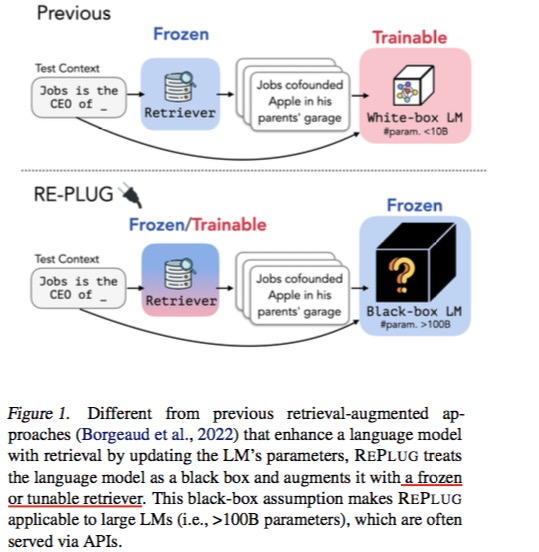
如上图所示,简单地理解就是在“白盒”范式下,假设检索组件不优化,也就是我们确信检索组件检索到的相关文本是足够准确的,即喂给语言模型的输入文本所含的信息丰富且准确,并且对每一个用户query(用户输入)来说,检索出来的文本确定的,我们需要优化语言模型让它产生的输出更正确,也就是调节语言模型来适配检索组件;
当然“白盒”模式下,检索组件也可以一并优化,但是这个相应地会更复杂。因为检索组件一旦被训练,检索出的文本和用户query的表示就会改变,那么被选出来的文本也就变了。什么时候重新编码一遍所有文本又是一个待考量的问题。
“黑盒”范式下,语言模型的参数不会被优化,我们要优化的是检索组件从而确保检索出的知识更好,也就是给到语言模型的输入更好,这样语言模型产生的输出才更正确,也就是调节检索组件来适配语言模型。
3. REPLUG & REPLUG LSR
RERLUG(Retrieve and Plug) 其实就是在语言模型上额外加了一个检索组件,利用检索组件获得一些相关信息,与原始输入一起作为语言模型的新输入,检索组件和语言模型都不需要训练。(个人认为某种程度上检索出来的加到原始输入即用户query上的这些文本有点像prompt)。
RERLUG LST(RERLUG with LM-Supervised Retrieval)可以看作是 RERLUG 的升级版,它利用语言模型产生监督信号,从而去优化检索组件,让检索组件倾向于挑选出能够降低语言模型所生成文本的困惑度。
3.1 REPLUG
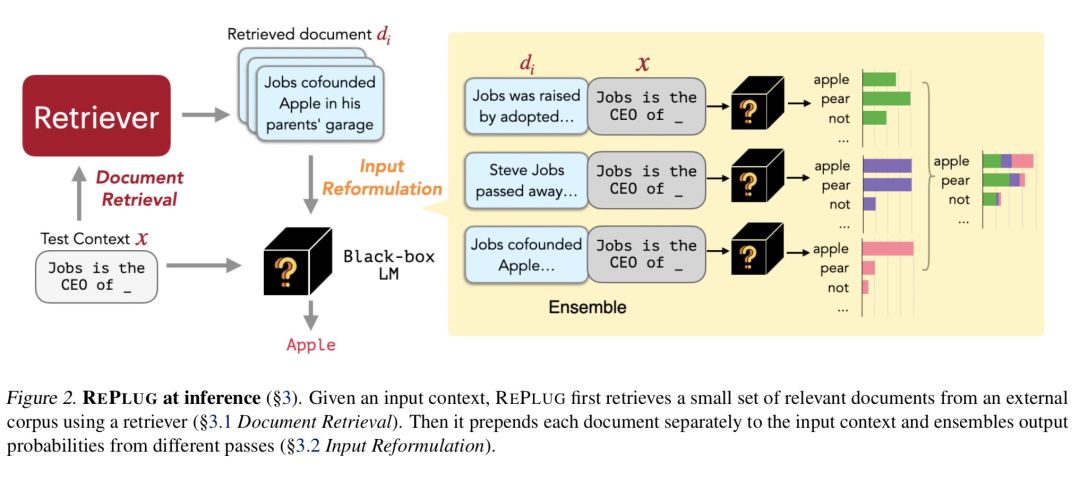
如上图所示,RERLUG主要包含两个步骤:
利用检索器从外部语料库中检索出与用户query相关的文档集
接着,分别将每个文档内容与用户query拼接然后送入语言模型(并行),最后再集成预测的概率。
下面,我们来分别介绍这两个核心部分。
3.1.1 检索器
REPLUG 使用 双塔结构的向量检索器(原文:a dense retriever based on the dual encoder architecture)。
所谓双塔/双编码器网络其实就是将用户query和检索文档 分别编码,然后再利用 cosine 等距离函数计算二者的相似度。具体又可分为SDE(Simese dual encoder)和 ADE(Asymmetric dual encoder):
SDE:虽说是双塔,但实际上用户query和检索文档共用一套参数,;
ADE:编码用户query和检索文档的编码器共享部分参数或者完全不共享参数,是两套独立的参数网络。
不同于BERT等典型的交互式网络,SDE 和 ADE 的共同点是都不会进行深层交互。双塔结构一个最典型的应用是召回or粗排,也就是适用于对计算速度要求严格的场景。
根据论文的描述,可以知道 REPLUG 采用的是SDE,即文档 和 用户query 都使用同一编码器进行向量化。具体地,在最后一层隐藏表示上利用平均池化获得文档 的编码 ;同理,获得输入 的编码 ,然后利用 cosine 计算二者相似度:
最后根据 选出 k 个最相关的文档。
显然,我们需要把用户query 和所有文档 比较; 是一个相当大的规模的数据,这个速度比较慢,所以 RERLUG 使用了FAISS(可快速寻找k个最相似向量的系统,需要预先将所有文档编码)来加速。
3.1.2 重构输入,加权集成概率
前面我们说过 REPLUG 是分别将每个文档内容与用户query拼接,然后送入语言模型(并行),最后再集成预测的概率。那为什么要这么做呢?
语言模型本身对输入是有限制的,输入的长度由语言模型的上下文窗口大小决定,比如GPT-3系列模型中,text-davinci-003最多可接受的输入是4000个token, text-curie-001则是2048token。所以我们不可能一股脑把检索出来的最相关的 个文档都一次性喂给语言模型。
针对这个问题,REPLUG 设计了一个集成策略。具体地,将每个文档 都添加到 的前面,再将拼接后的文本分别给到语言模型,最后将所有 个的输出概率集成起来(这里利用了相关度加权)。这里 表示的就是最相关的 个文档,集成策略的公式如下:
其中, 表示向量拼接, 是经过归一化的文档-用户query对的相似度:
3.2 REPLUG LSR
前文我们说,可以将 RERLUG LST 看作是 RERLUG 的升级版,它主要利用语言模型产生监督信号,从而去优化检索组件,让检索组件适配语言模型。这里面,可能大家最感兴趣的就是这个监督信号,它到底是什么,怎么来的,怎么计算的?
在 REPLUG LSR 中,这个监督信号其实是通过“匹配检索文档的概率与语言模型输出序列的困惑度(perplexity)”而来。更直白地说,REPLUG LSR 希望检索器能够找到使得语言模型生成文本困惑度较低的文档。(这里原文使用的是likelihood,即似然。结合具体公式来看,个人认为叫概率更合适,所以下文我们都统一称为概率。)
3.2.1 语言模型的困惑度
这里我们简单解释下困惑度。
首先语言模型不仅可以用来生成文本,本质上它提供了一种很自然的方式来估计句子的概率。越好的语言模型对于我们人类给出的一句通顺流畅的话,会给出越高的概率,这样的语言模型困惑度也就越小。简单地概括就是句子概率越大,语言模型越好,困惑度越小。
那么"检索器要找到使得语言模型生成文本困惑度得分较低的文档"就可以这么理解:检索器检索出来的文档 可以提高语言模型生成答案 的概率,并且文档的检索概率越高,语言模型生成的 的概率也越高。
也就是说,REPLUG LSR 的监督信号中涉及两个概率计算。
3.2.1 概率计算
首先是检索文档的概率,这个部分和前面的 比较像,只不过多了一个缩放因子:
注意到,这里归一化也是在 上做的,所以这个归一化是近似归一化。
然后是语言模型输出序列的困惑度概率。假设 计算的是在给定用户query 和检索文档 的条件下,语言模型生成标准答案 的概率;那么在文档集 中,文档 对应的语言模型输出序列的困惑度概率如下:
这里也是一个近似归一化,缩放因子为 。
但是这里小喵有两个疑问:
(1) 如果语言模型是一个黑盒,那我们又该如何计算呢?
(2) 还有这里的并不是一个token,而是一个token序列,针对token序列前面的集成概率具体又是怎么计算的呢?
3.2.2 损失函数
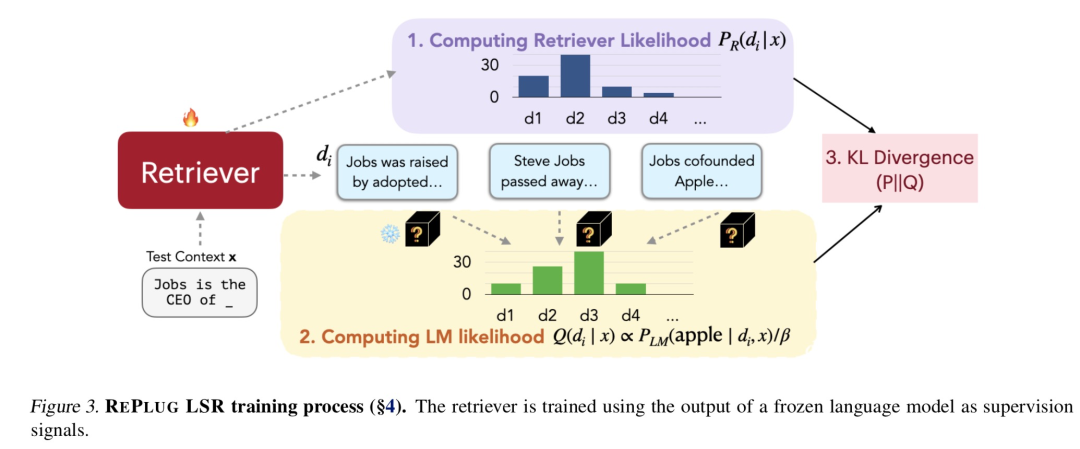
我们前面说过文档的检索概率越高,语言模型生成的 的概率也越高,也就是说我们希望这两个概率一致。而度量两个概率分布的距离可以通常选用的是KL散度,所以在 REPLUG LSR中,损失函数如下:
这里 代表用户输入的集合。这个损失函数非常容易理解,并且某种程度上只有这样才能将语言模型的输出与检索器关联起来,从而去优化检索器。
REPLUG LSR 通过优化检索器的参数降低损失函数的值从而让检索器适配到语言模型。这里,需要注意的是前面我们提过检索组件一旦被训练,检索出的文本和用户query的表示就会改变,那么被选出来的文本也就变了。所以在训练过程中, REPLUG LSR 每隔 个 training step 就会重新编码一遍所有文本。
4. 总结
今天我们分享了一篇23年的新工作,它提出了检索增强语言模型的新范式。在这个范式下,利用语言模型产生监督信号,从而去优化检索组件,让检索组件适配语言模从而消除或减少幻觉即事实性错误的生成。
在今天这篇文章中,小喵主要集中在论文方法和思想的分享,感兴趣的读者朋友可以下载原文详细阅读实验部分。对于小喵的疑问,有知道的朋友可以后台私信小喵,咱们一起交流一下。
参考资料
[1]
《REPLUG: Retrieval-Augmented Black-Box Language Models》: https://arxiv.org/pdf/2301.12652.pdf
最后给大家推荐一下最近小编从最新的斯坦福NLP的公开课都放到了bilibili上了,都已做了中英翻译,大部分已经更新完毕了,给需要的小伙伴~
是最新的呦~
目录
词向量
神经分类器
反向传播和神经网络
句法结构
RNN
LSTM
机器翻译、Seq2Seq和注意力机制
自注意力和Transformer
Transformers和预训练
问答
自然语言生成
指代消解
T5和大型预训练模型
待更...
点击阅读原文直达b站~
进NLP群—>加入NLP交流群















 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









