






每天给你送来NLP技术干货!
来自:SimpleAI
💡GENIUS: 一个能根据草稿进行文本生成的“小天才”模型,也是一个“开袋即食”的通用文本数据增强工具

点击这里进群—>加入NLP交流群和求职群
标题:GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation
链接:https://arxiv.org/abs/2211.10330v1
Github⭐:https://github.com/beyondguo/genius
Demo:https://huggingface.co/spaces/beyond/genius
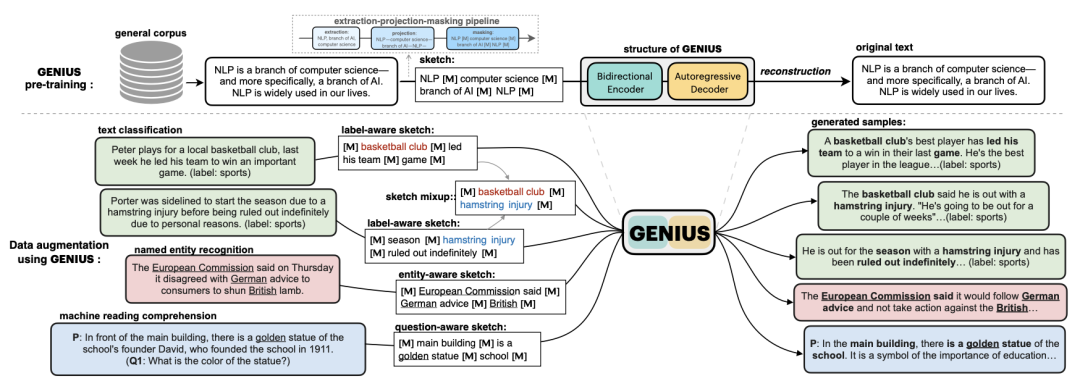
论文有两个主要贡献:
GENIUS模型,是一个conditional text generation (CLM) 预训练模型,能根据你给定的一个sketch(草稿,包含你要表达的关键信息,可以是词、短语、短句),来生成一段完整流畅的文本。目前我们开源了英文版和中文版模型供大家测试研究。
GeniusAug,是一个基于GENIUS的通用文本数据增强方法,同时兼顾样本质量和多样性,可用于分类、NER、MRC、summarization等多种NLP任务。
效果展示
先给一个英文例子:
草稿(sketch):
__ machine learning __ my research interest __ data science __GENIUS生成:
I am a Ph.D. student in machine learning, and my research interest is in data science. I am interested in understanding how humans and machines interact and how we can improve the quality of life for people around the world.
再举一个中文例子:
草稿(sketch):
自然语言处理__谷歌__通用人工智能__GENIUS生成:
自然语言处理是谷歌在通用人工智能领域的一个重要研究方向,其目的是为了促进人类智能的发展。
(注:上面例子中使用的__是为了好看,实际上我们应该填上<mask>(英文模型)或者[MASK](中文模型))
我在🤗Huggingface上搭建了一个Demo Space,大家可以亲自体验一下:https://huggingface.co/spaces/beyond/genius(这里也非常感谢Huggingface团队对GENIUS模型提供的硬件加速!)
下面简要地介绍一下论文的方法和实验。一些具体细节请参见论文或直接跟我联系。
GENIUS是如何预训练的
GENIUS模型使用一种“由草稿到全文的重构”(reconstruction from sketch)的任务进行预训练,其中采用了一种 extreme and selective masking 的策略。
如何构造草稿sketch呢,对于一个文本,我们会抽取其关键信息(大约占比全文的20%),然后对剩余部分全部丢弃,对每一段连续丢弃的部分,使用一个mask token进行填补。具体步骤分为三步,extraction-projection-masking:
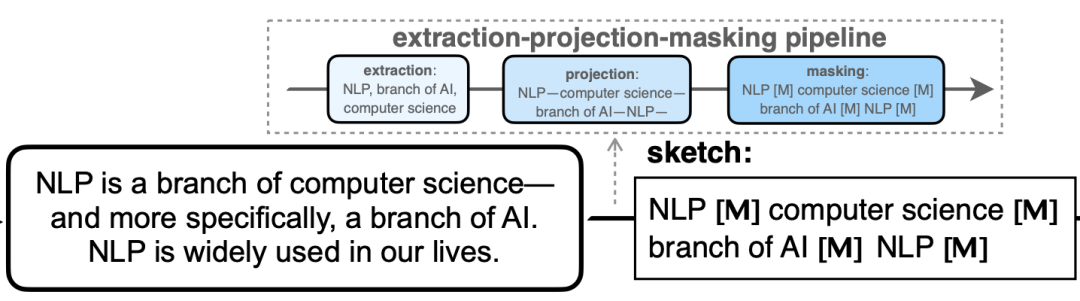 其中,extraction步骤,我们使用无监督抽取工具YAKE来抽取最大为3-gram的关键短语,在projection步骤中,我们会允许一个词出现多次,并按照原始的顺序,最后在masking步骤中,使用mask token进行填补。
其中,extraction步骤,我们使用无监督抽取工具YAKE来抽取最大为3-gram的关键短语,在projection步骤中,我们会允许一个词出现多次,并按照原始的顺序,最后在masking步骤中,使用mask token进行填补。
构造好sketch之后,我们会让模型“吃掉”这个sketch,然后“吐出”原始的文本,即根据草稿对原文进行重构。我们采用T5模型使用的C4数据集,抽取了超过2700万的样本进行GENIUS的预训练。
GENIUS的预训练,其实跟BERT、BART等通过reconstruction from corrupted text任务相似,但是由两个重要不同:
在哪里mask:GENIUS采用的是一种selective masking的方式,只对不重要的部分进行mask,而BERT、BART、T5等一系列方法,均采用random masking的方式;
多大幅度的mask:GENIUS的mask比例可以高达80%,堪称extreme masking,而BERT系列方法只使用15%的mask比例,BART更大一点,但也只有30%.
这两点不同,使得GENIUS可以在仅仅根据几个关键词,或者短语,就重构出大段的文本,这是BERT、BART等模型所不具备的能力。
背后花絮:其实,这种sketch的设计,并不是一开始就这样的。。。虽然我介绍的时候顺理成章,但我一开始,实际上是直接把抽取工具给出的关键短语进行拼接,作为sketch,这也是一些相关工作的常见做法。后面实验效果不佳,再不断反思,才设计出这种方式。所以我后来设计了几种不同的模板,做了一个预训练效果的对比:
 实验发现,抽取关键词/短语还是随机词/短语,是否保留原始顺序,是否允许多次出现,是否使用mask token,都对预训练有着重要影响。GENIUS是在BART的权重上继续进行预训练的,这些设置,缓解了继续预训练中的灾难性遗忘,缓解了机端mask情况下的重构难度,从而使得GENIUS能训练出较好的效果。
实验发现,抽取关键词/短语还是随机词/短语,是否保留原始顺序,是否允许多次出现,是否使用mask token,都对预训练有着重要影响。GENIUS是在BART的权重上继续进行预训练的,这些设置,缓解了继续预训练中的灾难性遗忘,缓解了机端mask情况下的重构难度,从而使得GENIUS能训练出较好的效果。
效果对比:我们在sketch-based text generation任务上,跟一些经典模型进行了对比,结果表明GENIUS模型能够生成更加流畅、多样的文本,对关键信息的保留度和相关度也十分出色:

GeniusAug——开袋即食的data augmentation tool
GENIUS模型有什么应用场景呢?对于一个文本生成模型来说,我个人总感觉做什么“故事生成”、“写作辅助”都是噱头大实用性小。虽然GENIUS这些都可以做,比如给定一个故事线,让GENIUS去生成完整的故事;或者你写作时想根据一个关键词造句,GENIUS可以用来给你一些提示。但是这些场景说实话,我并不是很感兴趣。我有一个更感兴趣且自认为更有实用价值的场景——NLP任务的数据增强。
回顾一下现有的文本数据增强方法,包括EDA、C-BERT、Back-Translation、LAMBADA等等,要么太过于保守(对原始样本做很小的改动),要么太过于激进(企图让模型生成全新的样本)。前者受限于很低的多样性,后者则有较大的产生不良样本的风险。
基于这样的考虑,我们提出了GeniusAug:一种sketch-based data augmentation方法,介于保守和激进中间。先抽取出一个跟任务相关的sketch,然后交给GENIUS来生成新的上下文。由于sketch被保留了,所以不用担心样本的核心语义被损坏,而重新生成上下文,则带来了训练样本的多样性,因此兼顾了质量和多样性。
基于GENIUS的大规模预训练,GeniusAug是一种开袋即食的数据增强工具,即不需要像很多之前的方法需要在下游数据集上进行微调,就可以直接拿来用。当然,进一步微调一下,也可以让效果更好。另外,这种基于sketch来生成的方式十分灵活,因此可以适用于多种NLP任务的数据增强。下图示意了对不同NLP任务的增强方式:
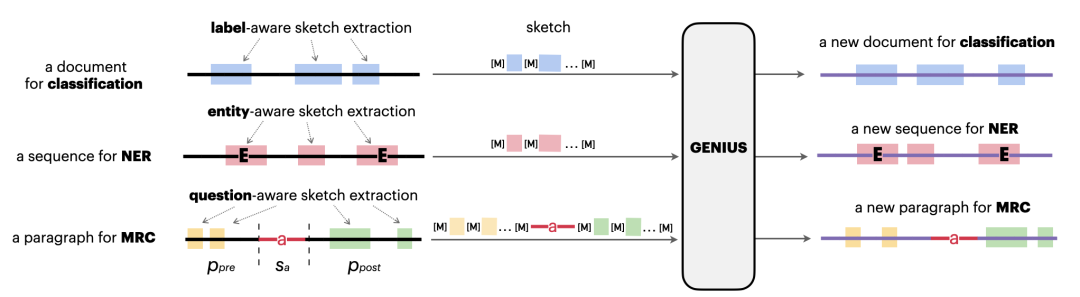
这里需要注意的是,我们采用了一种Target-aware sketch extraction的方式来抽取sketch,这跟GENIUS预训练中抽取sketch是有一点不同的。具体来说,我们会通过一个encoder,来得到原始样本和一个任务特定信息的fusing embedding,然后通过这个fusing embedding跟原文中的n-gram的相似度来挑选任务相关的关键信息。这里所谓的任务特定信息,在分类任务中,就是label,在NER中就是entities,在MRC中就是question。
我们还发现了GENIUS拥有一定程度的“属性控制”能力,这也对保障数据增强的质量有很大帮助,看下面的例子,如果在原有sketch的基础上,再加一个属性prompt,就可以进一步控制生成的文本:

因此,GeniusAug在进行数据增强时,比方对于文本分类任务,就可以使用这里的属性控制能力,来使生成的样本有更好的质量。
下面列举一下GeniusAug在文本分类、NER、MRC任务上的数据增强效果:
文本分类: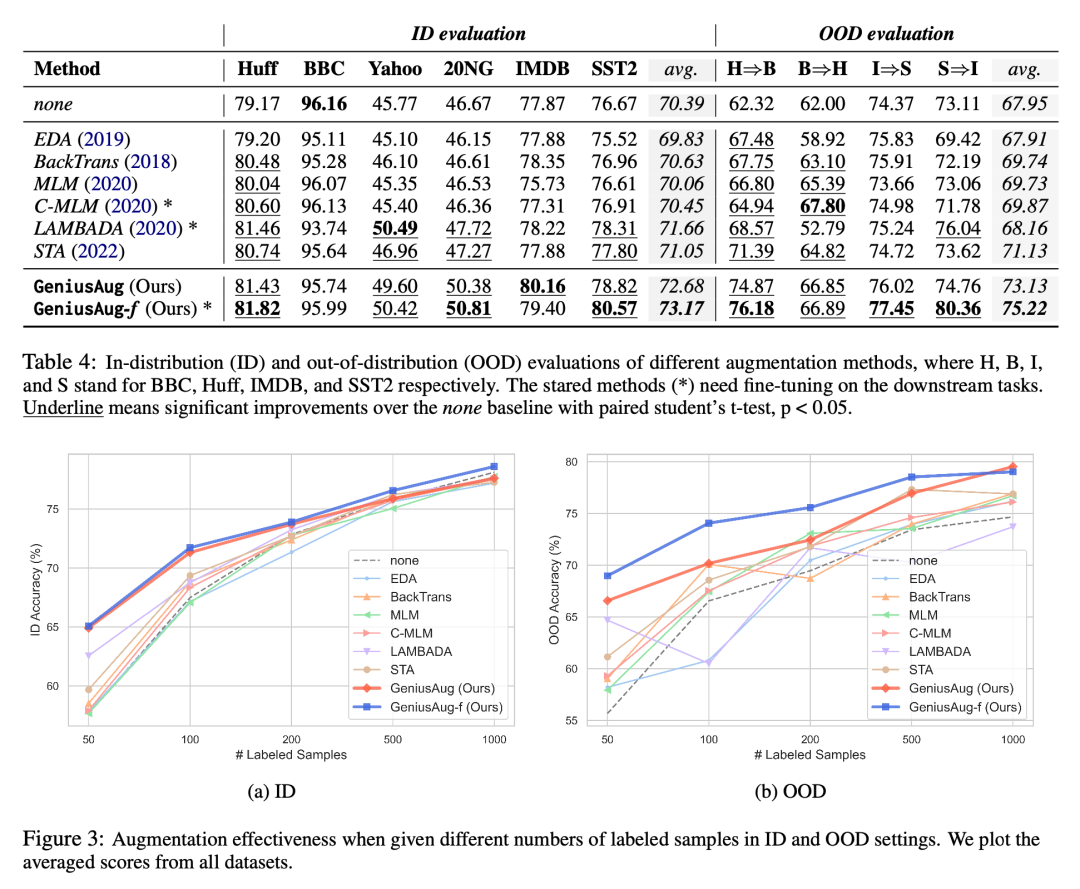
这里想重点说一下OOD evaluation。这是一个比普通的拿来一个数据集,划分训练测试集然后进行evaluation更加有挑战性的任务,目的是为了测模型在换了一个全新的样本分布之后,是否依然可以正常预测。这里设置的H->B,B->H等等,都是拥有相同的任务定义,但是样本分布不同,所以更加考验数据增强的能力。如果产生的样本噪音过大,可能会急剧损害OOD的性能,如果产生的样本同质化很严重,那么模型会在原始分布上overfit,也会对OOD泛化不利。
而GeniusAug,使用sketch来保留核心语义,去掉了噪声,借助“属性控制”能力,生成的样本也跟任务十分相关,噪音很小;同时,新生成的样本又跟原始样本有较大的差别,避免了同质化。因此,GeniusAug在OOD setting下表现得尤为出色,在不同的资源水平下,均明显超越baseline。
在分类任务上,下图展示了GENIUS还能玩出什么“花活儿”,除了上面介绍的典型用法,我们还可以把不同样本的sketch进行一个mixup,这样又大大增加的多样性。这里的方式,可以当做是抛砖引玉,我们还可以探索出更多更有意思的玩法来进一步发掘GENIUS模型的潜力。
NER与MRC:论文在数据增强上主要的实验集中于文本分类,在NER和MRC任务上,做了简单的测试,对比了一些常见的baseline,印证了GeniusAug的通用性和有效性。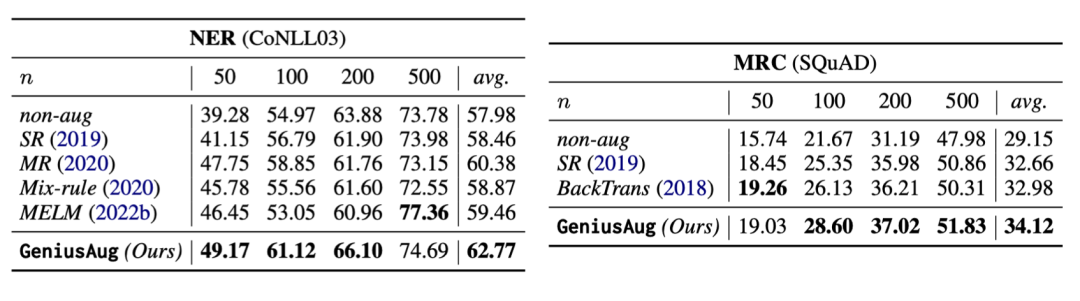
以上就是GENIUS这个工作的主要内容了,其实这个工作还有很多可以完善的地方,具体我在论文中花了一章节详细讨论limitations,这里不再赘述。我也并不追求GENIUS或者GeniusAug成为某个SOTA,毕竟baseline和任务千千万,我们的资源也有限,没法使用超大语料库训练一个超大模型。本文最大的希望就是能给pre-training,亦或text generation,亦或data augmentation等领域提供一些新的思路,这样就足以:)
之后一段时间,我也会继续完善这个工作,探索一些新的应用场景。
欢迎大家阅读我们的论文,给予批评意见;预训练和数据增强的代码已开源,也欢迎调戏我们的Demo,反馈一些你觉得非常好和非常差的cases🤣。
链接:https://arxiv.org/abs/2211.10330v1
Github:https://github.com/beyondguo/genius
Demo:https://huggingface.co/spaces/beyond/genius

📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务
点击这里进群—>加入NLP交流群和求职群















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









