







作者:杰瑞和他的猫 (已获作者授权)
链接:https://zhuanlan.zhihu.com/p/595178668
排版:深度学习自然语言处理 公众号
近年来 NLP 学术领域发展真是突飞猛进,刚火完对比学习(contrastive learning),又有更火的提示学习 prompt learning。众所周知,数据标注数据很大程度上决定了AI算法上限,并且成本非常高,无论是对比学习还是提示学习都着重解决少样本学习而提出,甚至在没有标注数据的情况下,也能让模型表现比较好的效果。本文主要介绍 prompt learning 思想和目前常用的方法。
点击这里进群—>加入NLP交流群
目录
一. NLP的训练范式有哪些
二. 为什么需要提示学习
三. 提示学习是什么
四. 常见的提示学习方法
五. 总结
一. NLP的训练范式有哪些
目前学术界一般将NLP任务的发展分为四个阶段即NLP四范式:
第一范式:基于「传统机器学习模型」的范式,如 tf-idf 特征+朴素贝叶斯等机器算法;
第二范式:基于「深度学习模型」的范式,如 word2vec 特征 + LSTM 等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;
第三范式:基于「预训练模型 + finetuning」的范式,如 BERT + finetuning 的NLP任务,相比于第二范式,模型准确度显著提高,但是模型也随之变得更大,但小数据集就可训练出好模型;
第四范式:基于「预训练模型 + Prompt + 预测」的范式,如 BERT + Prompt 的范式相比于第三范式,模型训练所需的训练数据显著减少。
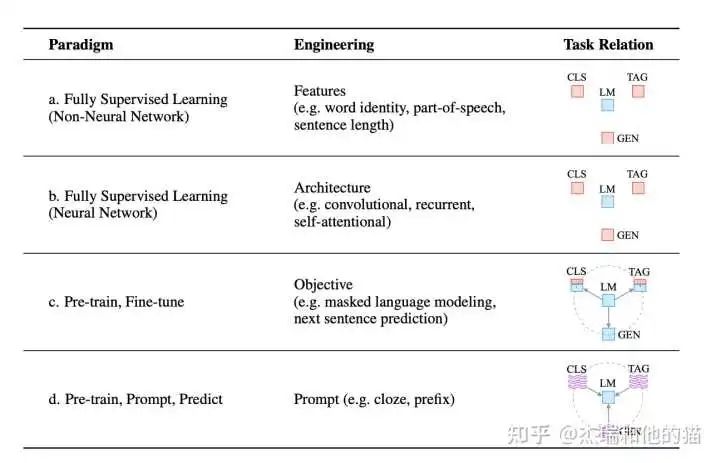
在整个NLP领域,你会发现整个发展是朝着精度更高、少监督,甚至无监督的方向发展的,而 Prompt Learning 是目前学术界向这个方向进军最新也是最火的研究成果。
二. 为什么需要提示学习为什么呢?
要提出一个好的方式那必然是用来「解决另一种方式存在的缺陷或不足」,那我们就先从它的上一个范式来说起,就是预训练模型 PLM + finetuning范式 常用的是 BERT+ finetuning:
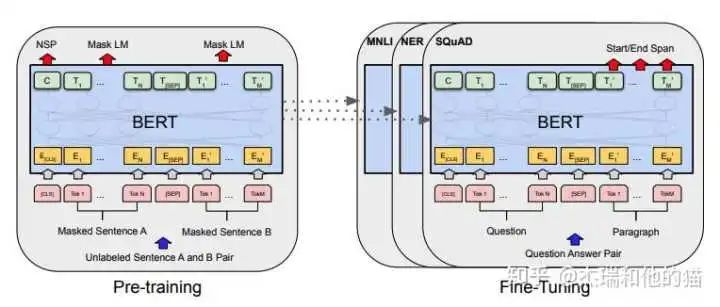
这种范式是想要预训练模型更好的应用在下游任务,需要利用下游数据对模型参数微调;首先,模型在「预训练的时候,采用的训练形式:自回归、自编码,这与下游任务形式存在极大的 gap」,不能完全发挥预训练模型本身的能力
必然导致:较多的数据来适应新的任务形式——>少样本学习能力差、容易过拟合
 上下游任务形式存在gap
上下游任务形式存在gap
其次,现在的预训练模型参数量越来越大,为了一个特定的任务去 finetuning 一个模型,然后部署于线上业务,也会造成部署资源的极大浪费。
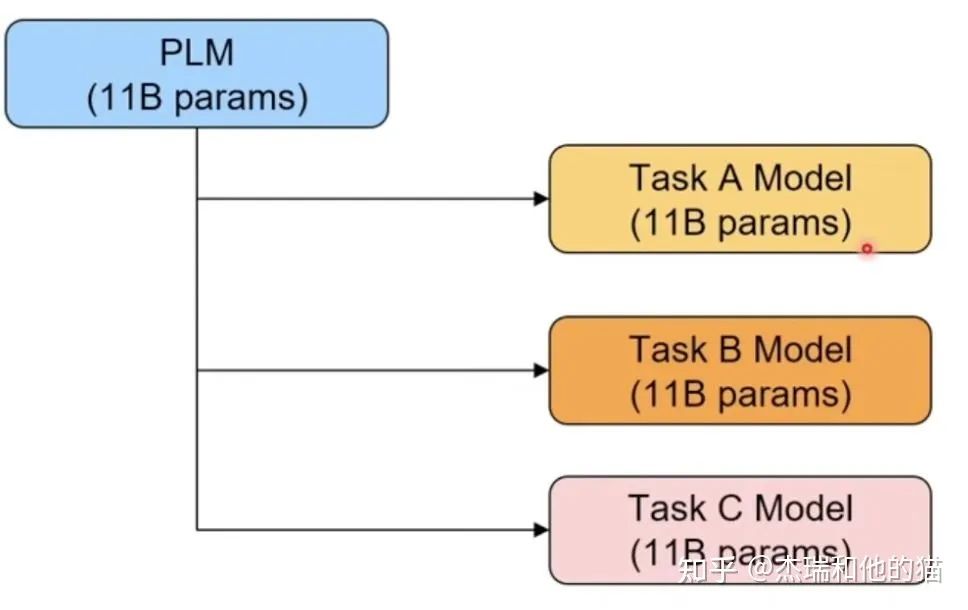 模型专用性特定任务微调导致部署成本过高
模型专用性特定任务微调导致部署成本过高
三. 提示学习是什么
首先我们应该有的「共识」是:预训练模型中存在大量知识;预训练模型本身具有少样本学习能力。
GPT-3 提出的 In-Context Learning,也有效证明了在 Zero-shot、Few-shot场景下,模型不需要任何参数,就能达到不错的效果,特别是近期很火的GPT3.5系列中的 ChatGPT。

Prompt Learning 的本质
将所有下游任务统一成预训练任务;「以特定的模板,将下游任务的数据转成自然语言形式」,充分挖掘预训练模型本身的能力。
本质上就是设计一个比较契合上游预训练任务的模板,通过模板的设计就是「挖掘出上游预训练模型的潜力」,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务,关键包括3个步骤:
设计预训练语言模型的任务
设计输入模板样式(Prompt Engineering)
设计label 样式 及模型的输出映射到label 的方式(Answer Engineering)
Prompt Learning 的形式
以电影评论情感分类任务为例,模型需根据输入句子做二分类:
原始输入:特效非常酷炫,我很喜欢。
Prompt 输入:「提示模板1」: 特效非常酷炫,我很喜欢。这是一部[MASK]电影 ;「提示模板2」: 特效非常酷炫,我很喜欢。这部电影很[MASK]
提示模板的作用就在于:将训练数据转成自然语言的形式,并在合适的位置 MASK,以激发预训练模型的能力。
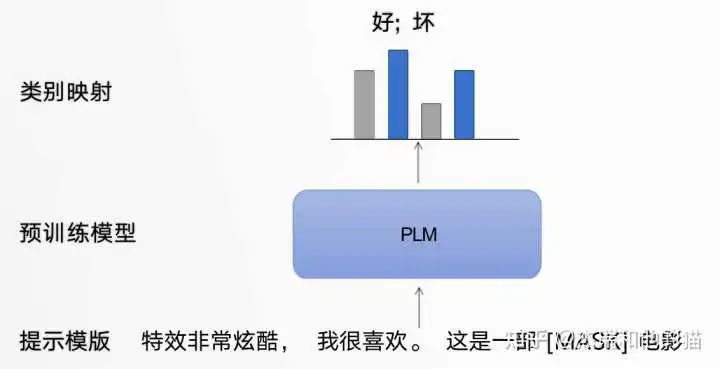
提示学习模板框架
类别映射/Verbalizer:选择合适的预测词,并将这些词对应到不同的类别。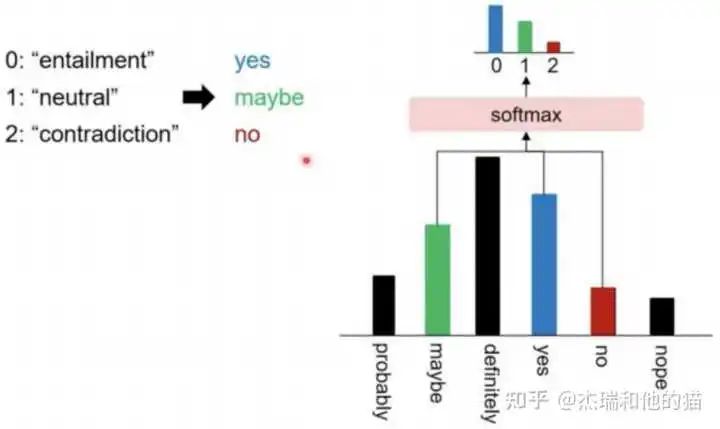 类别映射
类别映射
通过构建提示学习样本,只需要少量数据的 Prompt Tuning,就可以实现很好的效果,具有较强的零样本/少样本学习能力。
四. 常见的提示学习方法
1. 硬模板方法
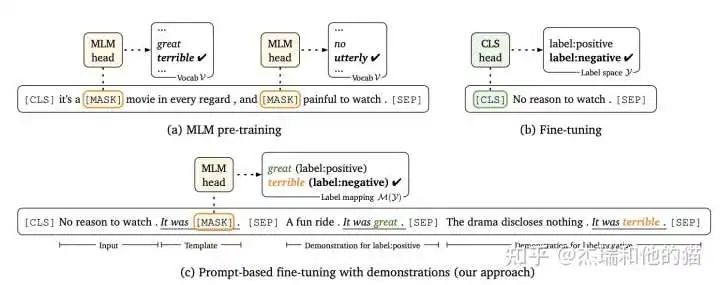
1.1 硬模板-PET(Pattern Exploiting Training)
PET 是一种较为经典的提示学习方法,和之前的举例一样,将问题建模成一个完形填空问题,然后优化最终的输出词。虽然 PET 也是在「优化整个模型的参数」,但是相比于传统的 Finetuning 方法,对「数据量需求更少」。
建模方式:
以往模型只要对P(l|x)建模就好了(l是label),但现在加入了Prompt P以及标签映射(作者叫verbalizer),所以这个问题就可以更新为:
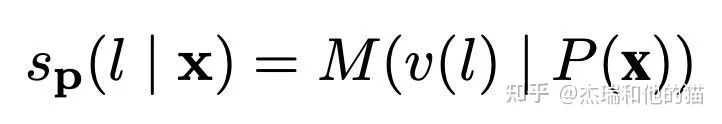
其中M表示模型,s相当于某个prompt下生成对应word的logits。再通过softmax,就可以得到概率:
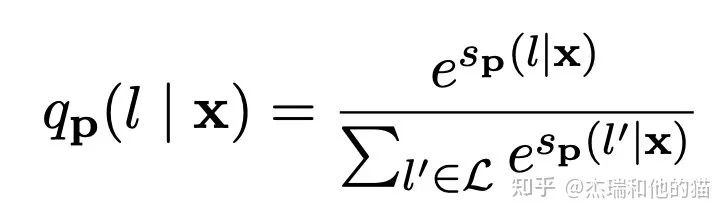
作者在训练时又加上了「MLM loss」,进行联合训练。
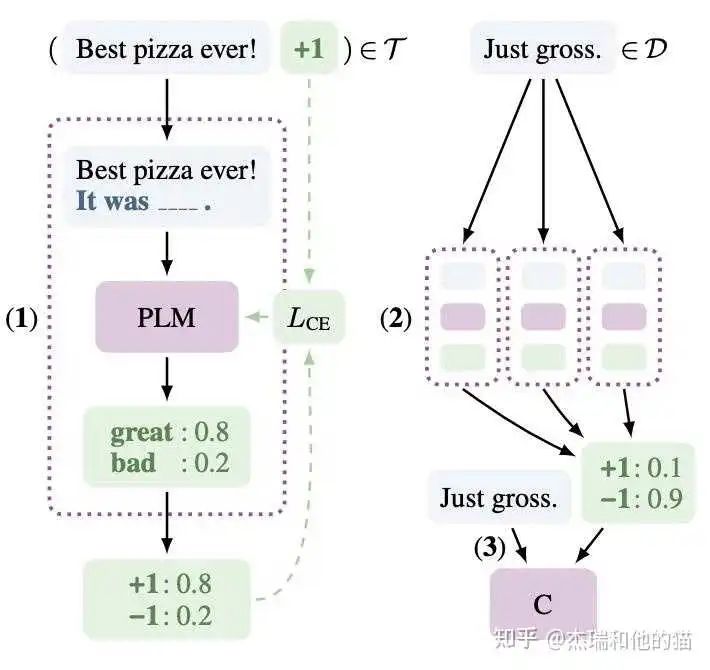
具体的做法:
在少量监督数据上,给每个 Prompt 训练一个模型;
对于无监督数据,将同一个样本的多个 prompt 预测结果进行集成,采用平均或加权(根据acc分配权重)的方式,再归一化得到概率分布,作为无监督数据的 soft label ;
在得到的soft label上 finetune 一个最终模型。
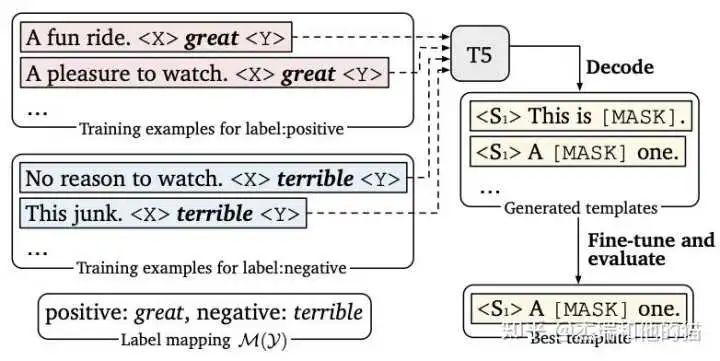
1.2 硬模板- LM-BFF
LM-BFF 是陈天琦团队的工作,在 Prompt Tuning 基础上,提出了Prompt Tuning with demonstration & Auto Prompt Generation。
「硬模板方法的缺陷」:
硬模板产生依赖两种方式:根据经验的人工设计 & 自动化搜索。但是,人工设计的不一定比自动搜索的好,自动搜索的可读性和可解释性也不强。

上图实验结果可以看出硬模板 对于prompt,改变prompt中的单个单词 会给实验结果带来巨大的差异, 所以也为后续优化提供了方向,如索性直接放弃硬模板,去优化 prompt token embedding。
2. 软模板方法
2.1 软模板- P tuning
不再设计/搜索硬模板,而是在输入端直接插入若干可被优化的 Pseudo Prompt Tokens,「自动化地寻找连续空间」中的知识模板:
不依赖人工设计
要优化的参数极少,避免了过拟合(也可全量微调,退化成传统 finetuning)
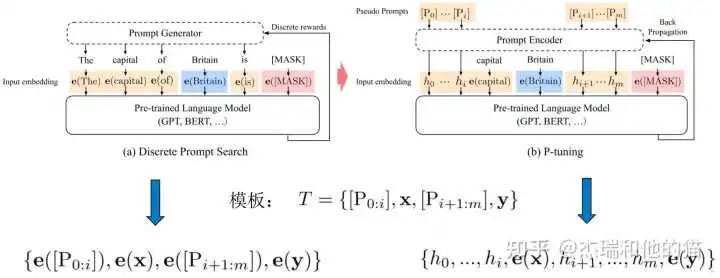
传统离散prompt 直接将模板 T 的每个 token 映射为对应的embedding,而 P-Tuning 将模板 T 中的Pi(Pseudo Prompt)映射为一个「可训练的参数 hi」 。
「优化关键点」在于,自然语言的hard prompt,替换为可训练的soft prompt;使用双向LSTM 对模板 T 中的 pseudo token 序列进行表征;引入少量自然语言提示的锚字符(Anchor)提升效率,如上图的“capital” ,可见 p-tuning是hard+soft的形式,并不是完全的soft形式。
具体的做法:
初始化一个模板:The capital of [X] is [mask]
替换输入:[X] 处替换为输入 “Britian”,即预测 Britain 的首都
挑选模板中的一个或多个 token 作为 soft prompt
将所有 soft prompt 送入 LSTM,获得每个 soft prompt 的「隐状态向量 h」
将初始模板送入 BERT 的 Embedding Layer,「所有 soft prompt 的 token embedding用 h 代替」,然后预测mask。
核心结论:基于全量数据,大模型:仅微调 prompt 相关的参数,媲美 fine-tuning 的表现。
代码:https://github.com/THUDM/
2.2 软模板- Prefix tuning
P-tuning 更新 prompt token embedding 的方法,能够优化的参数较少。Prefix tuning 希望能够优化更多的参数,提升效果,但是又不带来过大的负担。虽然prefix tuning是在生成任务上被提出来的,但是它对soft prompt后续发展有着启发性的影响。
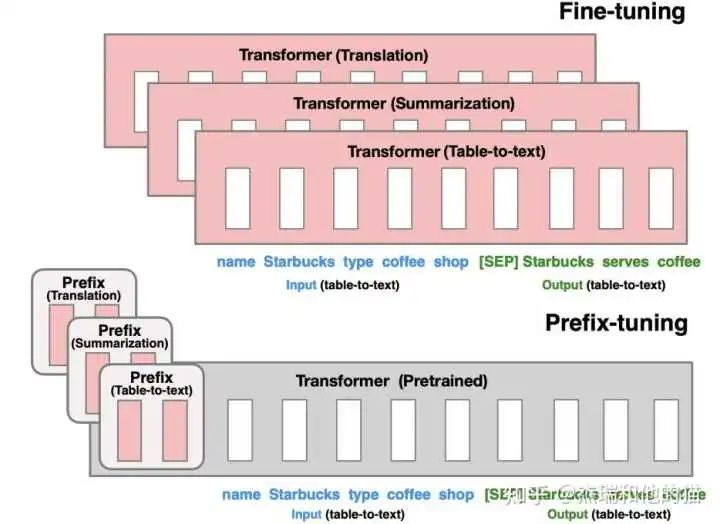
优化每一层的 Prompt token embedding,而不仅仅是输入层
由上图可见,模型上在每层 transformer 之前加入 prefix。特点是 prefix 不是真实的 token,而是「连续向量」(soft prompt),Prefix-tuning 训练期间冻结 transformer 的参数,只更新 Prefix 的参数。
只需要存储大型 transformer 的一个副本和学习到的特定于任务的前缀即可,为每个附加任务产生非常小的开销。

自回归模型
以图上自回归模型为例的做法:
输入表示为 Z = [ prefix ; x ; y ]
Prefix-tuning 初始化一个训练的 矩阵 P,用于存储 prefix parameters
前缀部分 token,参数选择设计的训练矩阵,而其他部分的token,参数则固定 且为预训练语言模型的参数
核心结论:Prefix-tuning 在生成任务上,全量数据、大模型:仅微调 prompt 相关的参数,媲美 fine-tuning 的表现。
代码:https://github.com/XiangLi1999/PrefixTuning
2.3 软模板- Soft Prompt Tuning
Soft Prompt Tuning 系统后验证了软模板方法的有效性,并提出:固定基础模型,有效利用任务特定的 Soft Prompt Token,可以大幅减少资源占用,达到大模型的通用性。
对 Prefix-tuning 的简化,固定预训练模型,只对下游任务的输入「添加额外的 k个可学习的 token」。这种方式在大规模预训练模型的前提下,能够媲美传统的 fine-tuning 表现。
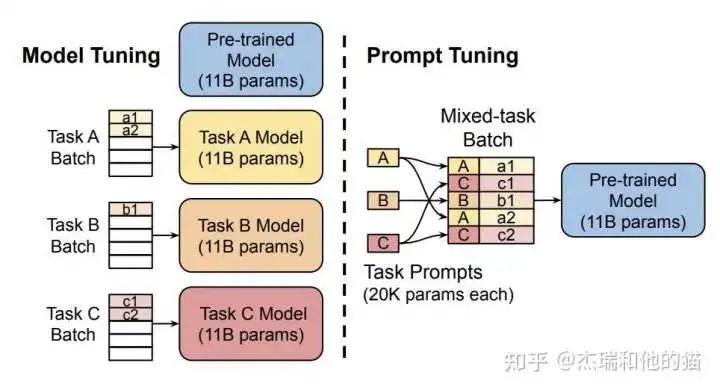
代码:https://github.com/kipgparker/soft-prompt-tuning
五. 总结
「Prompt Learning 的组成部分」
提示模板:根据使用预训练模型,构建 完形填空 or 基于前缀生成 两种类型的模板
类别映射/Verbalizer:根据经验选择合适的类别映射词、3. 预训练语言模型
「典型的 Prompt Learning 方法总结」
硬模板方法:人工设计/自动构建基于离散 token 的模板
1)PET 2)LM-BFF软模板方法:不再追求模板的直观可解释性,而是直接优化 Prompt Token Embedding,是向量/可学习的参数
1)P-tuning 2)Prefix Tuning
后续会在分类、信息抽取任务中尝试 Prompt Learning,持续更新中...
最近文章
深入理解Pytorch中的分布式训练
点击这里进群—>加入NLP交流群














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









