






 深度学习自然语言处理 原创
深度学习自然语言处理 原创
作者:cola
随着指令微调模型的发展,开始有人思考既然指令微调可以用来提升语言模型的性能,那么是否也可以用类似的方法来提升文本嵌入模型的性能呢?于是本文作者提出了INSTRUCTOR,这个模型设计了一种通用的Embedder,使得文本嵌入表示能更好地迁移到新的任务和领域,而不需要额外的训练。这个想法也是很有意思的,具体的请看下文吧~
论文:
One Embedder, Any Task: Instruction-Finetuned Text Embeddings地址:
https://arxiv.org/abs/2212.09741
背景介绍
现有的文本嵌入表示方法在应用到新的任务或领域时,通常性能都会受损,甚至应用到相同任务的不同领域也会遇到同样的问题。常见的解决办法是通过针对下游任务和领域的数据集进一步微调文本嵌入,而这个工作通常需要大量的注释数据。
本文提出的INSTRUCOR(Instruction-based Omnifarious Representations)不需要针对特定任务或领域进行微调就可以生成输入文本的嵌入。该模型在70个嵌入评价数据集上表现比SOTA嵌入模型平均要高3.4%。INSTRUCTOR和以往的模型不同,它向量表示不仅包含输入文本还有端任务和领域的指令。并且针对不同的目标,对于同一个输入文本,INSTRUCTOR会将输入表示为不同的嵌入。例如图1中Who sings the song “Love Story”?会根据不同的任务被表示为不同的嵌入。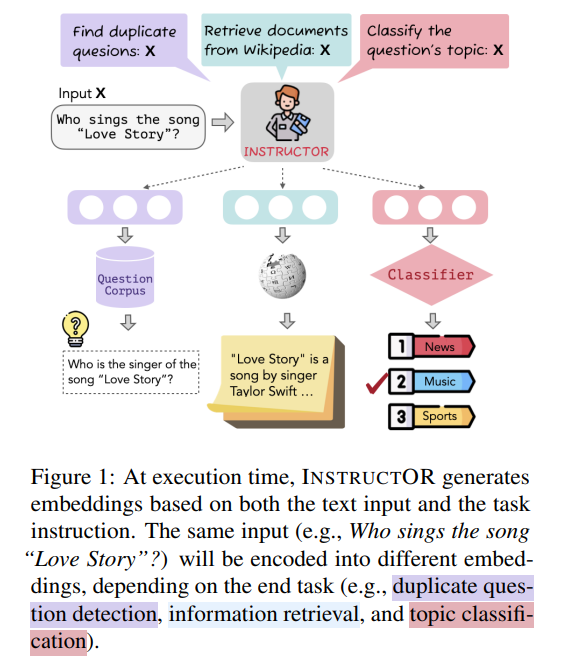 如图2所示,INSTRUCTOR是在MEDI上进行训练的,MEDI是我们的330个文本嵌入数据集的新集合,新标注了人工编写的任务指令。我们在所有数据集上使用对比损失来训练INSTRUCTOR,从而最大化语义相关文本对之间的相似性,同时最小化不相关文本对的相似性。
如图2所示,INSTRUCTOR是在MEDI上进行训练的,MEDI是我们的330个文本嵌入数据集的新集合,新标注了人工编写的任务指令。我们在所有数据集上使用对比损失来训练INSTRUCTOR,从而最大化语义相关文本对之间的相似性,同时最小化不相关文本对的相似性。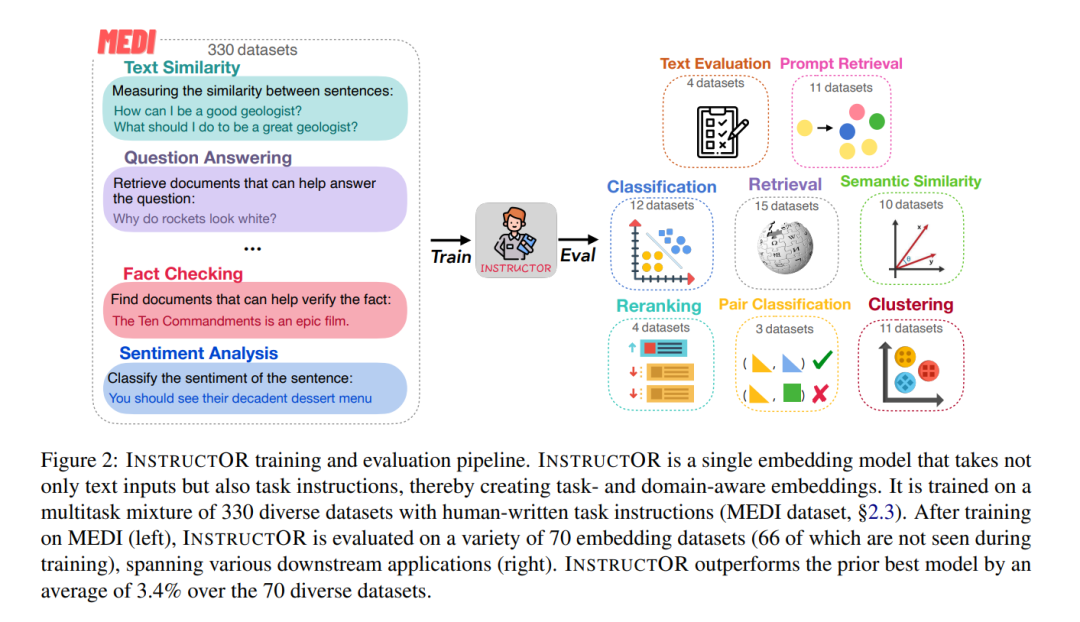
INSTRUCTOR
结构
INSTRUCTOR基于单个Encoder来设计,使用GTR系列模型作为框架(GTR-Base for INSTRUCTOR-Base,GTR-Large for INSTRUCTOR,GTR-XL for INSTRUCTOR-XL)。GTR模型使用T5进行初始化。不同大小的GTR使得我们指令微调嵌入模型的表现也不同。给定一个输入文本以及任务指令,INSTRUCTOR将他们组合成,然后通过对的最后一个隐藏表征进行均值池化来生成固定大小、特定任务的嵌入。
训练目标
通过将各种任务转为文本到文本的方式来训练INSTRUCTOR,给定输入,需要去区分好/坏候选输出,其中训练样本对应于元组,其中和分别是与和相关的指令。例如,在检索任务中,是查询,好/坏是来自某个文档的相关/不相关文档。
输入的候选的好由相似度给出,即它们的INSTRUCTOR嵌入之间的余弦: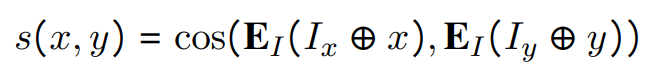 最大化正样本对之间的相似度,并最小化负样本对之间的相似度,其中表示每个正样本对的负样本对的数量,训练目标:
最大化正样本对之间的相似度,并最小化负样本对之间的相似度,其中表示每个正样本对的负样本对的数量,训练目标: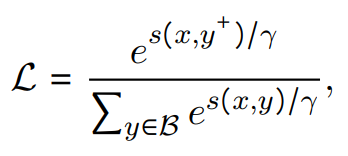 其中是softmax的温度,是和的并集。此外还加入了双向批内采样损失。
其中是softmax的温度,是和的并集。此外还加入了双向批内采样损失。
MEDI: Multitask Embedding Data with Instructions
MEDI(Multitask Embeddings Data with Instructions)是我们由330个数据集构造而成,该数据集包含不同任务和领域的指令。
数据构造:使用来自super-NI的300个数据集,另外30个来自现有的为嵌入训练设计的数据集。super-NI数据集附带自然语言指令,但不提供正负样本对。我们使用Sentence-T5嵌入来构建样本对,用表示。对于分类数据集,我们基于输入文本嵌入计算样本之间的余弦相似度。如果两样本具有相同的类标签,则使用与高度相似的示例创建一个正样本对,如果标签不同,则创建一个负样本对。对于输出标签为文本序列的其余任务,首先计算以下分数: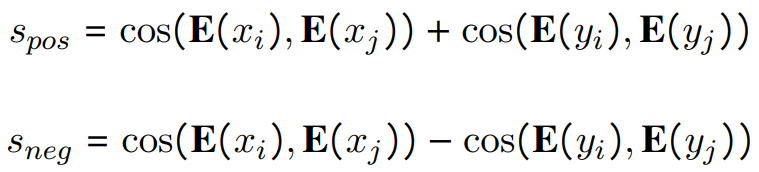 选择最高的样本作为正样本对,并选择具有最高的作为负样本对。其他30个嵌入训练数据集来自Sentence Transformers embedding data、KILT、MedMCQA。这30个数据集已经包含正样本对;其中MSMARCO和Natural Questions也包含负样本对。我们在模型微调过程中使用了4个负样本对。
选择最高的样本作为正样本对,并选择具有最高的作为负样本对。其他30个嵌入训练数据集来自Sentence Transformers embedding data、KILT、MedMCQA。这30个数据集已经包含正样本对;其中MSMARCO和Natural Questions也包含负样本对。我们在模型微调过程中使用了4个负样本对。
指令注释:每一个MEDI的实例都是一个元组。为了引入指令,我们设计了一个统一的指令模板:
文本类型:指定输入文本的类型。例如,对于开放域QA任务,查询的输入类型是问题,而目标的输入类型是文档。
任务目标(可选项):描述输入文本在该任务中如何使用。
领域(可选项):描述任务领域
最终的指令格式:“REPRESENT THE (DOMAIN) TEXT TYPE FOR TASK OBJECTIVE:."
实验
用MEDI数据集对INSTRUCTOR进行训练,并在70个下游任务对其进行评估。使用了MTEB基准,该基准由7个不同任务类别(如分类、重新排序和信息检索)的56个数据集组成。然后,我们进一步将INSTRUCTOR应用于上下文学习和文本生成评估的提示检索。在三种设置中,INSRTUCTOR都达到了最先进的性能。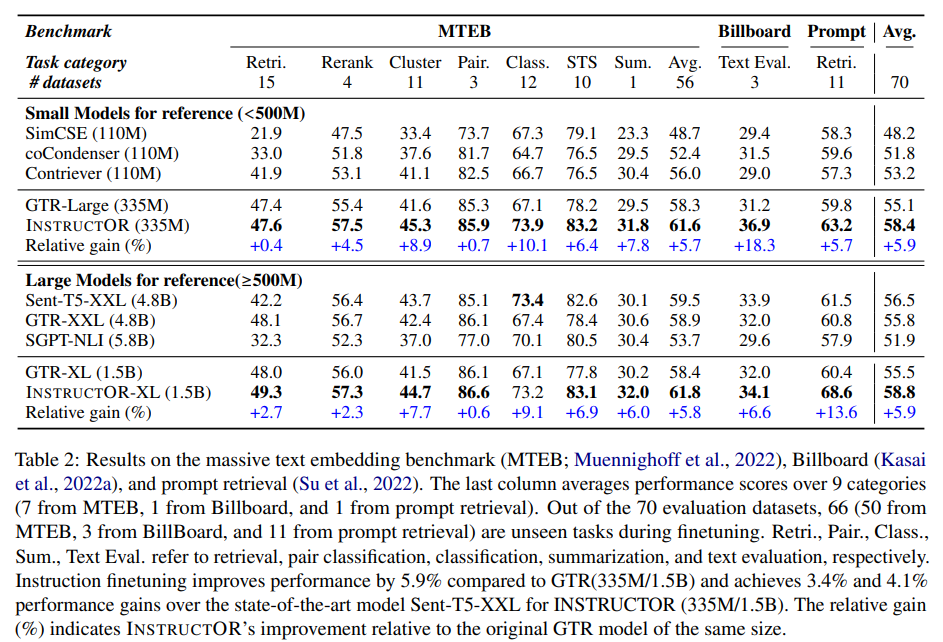 正如预期的那样,基于检索的模型(如GTR-XXL)在检索和重排序方面表现出较强的性能,但在STS和分类方面明显落后。相反,基于相似性的模型(例如,Sent-T5-XXL)在STS、分类和文本评估方面表现良好,但在检索方面表现不佳。这表明,这些基线倾向于生成只擅长某些任务的专门嵌入,而INSTRUCTOR提供了在不同任务类别上表现良好的通用嵌入。
正如预期的那样,基于检索的模型(如GTR-XXL)在检索和重排序方面表现出较强的性能,但在STS和分类方面明显落后。相反,基于相似性的模型(例如,Sent-T5-XXL)在STS、分类和文本评估方面表现良好,但在检索方面表现不佳。这表明,这些基线倾向于生成只擅长某些任务的专门嵌入,而INSTRUCTOR提供了在不同任务类别上表现良好的通用嵌入。
分析以及消融实验
指令的重要性
我们将MEDI划分为对称和非对称组,然后对每个组进行有指令和没有指令的训练。实验结果如图3所示,结果表明如果数据是对称的或非对称的,在没有指令的情况下进行微调的INSTRUCTOR的性能与原始GTR相近或更好。但是,使用指令微调使模型能够从对称和非对称数据的组合中获益。这体现了指令微调的重要性。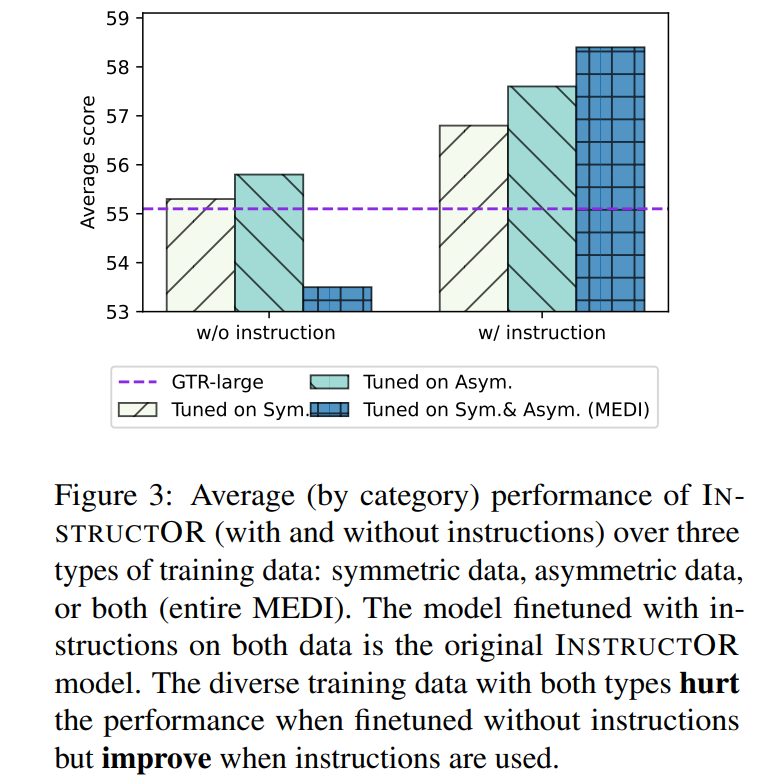
指令的鲁棒性
我们为所有评估数据集编写了五个意译指令,并测量了表现最佳和表现最差的指令之间的INSTRUCTOR的性能差距。图4表明,包含300个super-NI数据集对INSTRUCTOR的鲁棒性至关重要。从训练中删除这些数据集(没有super-NI)大大增加了表现最好和最差的指令之间的性能差距,这表明super-NI的多样化指令有助于模型处理不同的格式和风格。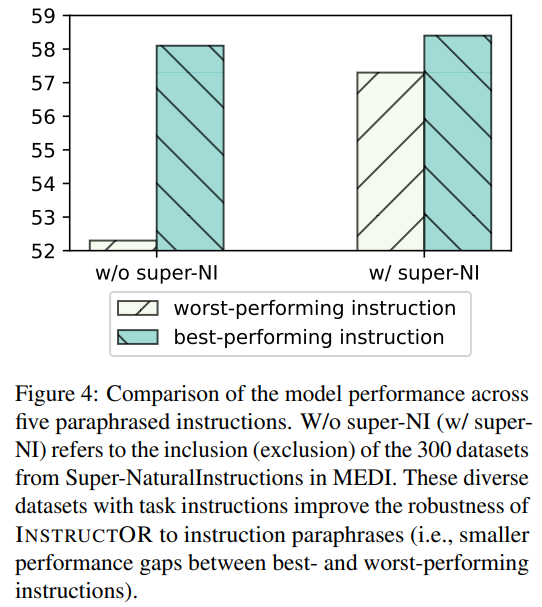
指令的复杂程度
我们考虑了四个层次的指令复杂性:N/A(无指令)、数据集标签、简单指令和详细指令。在数据集标签实验中,每个示例都附有其数据集名称。例如,在Natural Questions数据集上,查询格式为"Natural Questions; Input: who sings the song Love Story").。在简单的指令实验中,我们使用一两个单词来描述域(例如,对于Natural Questions数据集,输入查询是Wikipedia Questions;输入是who sings the song Love Story)。图5表明使用琐碎的数据集标签,INSTRUCTOR也优于原始的GTR模型,说明了指令在不同训练中的有效性。随着提供的信息越来越多,我们观察到持续的改进。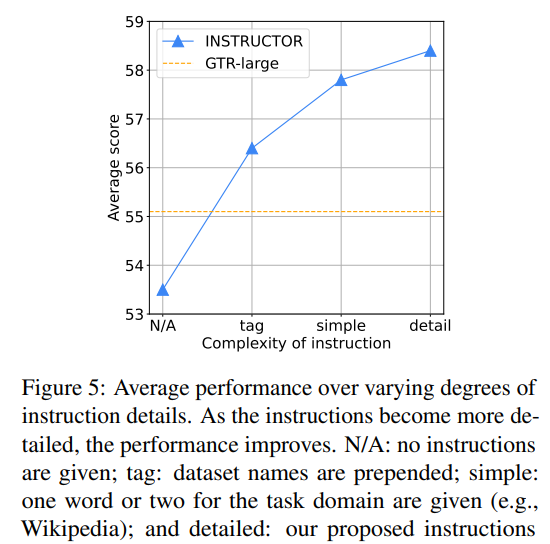
模型大小和指令微调
图6展示了比较不同大小的模型的平均性能。随着编码器transformer模型的扩大,GTR和INSTRUCTOR的性能都在不断提高。尽管如此,INSTRUCTOR的改进更加明显,这可能是因为带有指令的嵌入受益于更大的容量。这意味着大模型在计算各种领域和任务类型中的文本时更加一般化。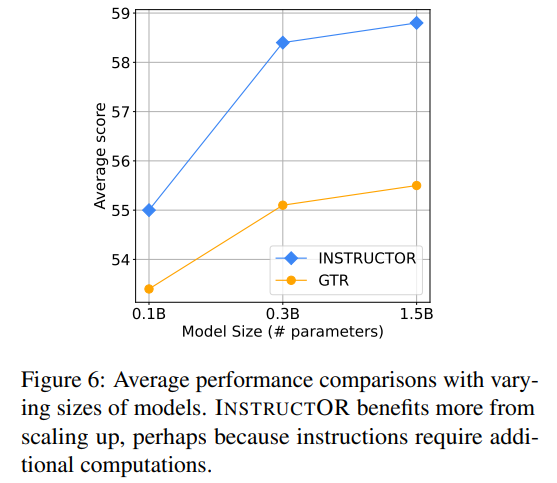
指令的域转移
基于指令微调的一个优点是,它提高了模型泛化到不可见领域和任务的能力。为了证明这种有效性,我们研究了三个unseen的INSTRUCTOR没有受过训练的领域:地理、生物和民间评论。如表3所示,INSTRUCTOR在所有三个领域上极大地提高了GTR-Large的性能(高于平均水平),这表明当将模型应用于不可见或不常见的领域时,指令可以提供更多帮助。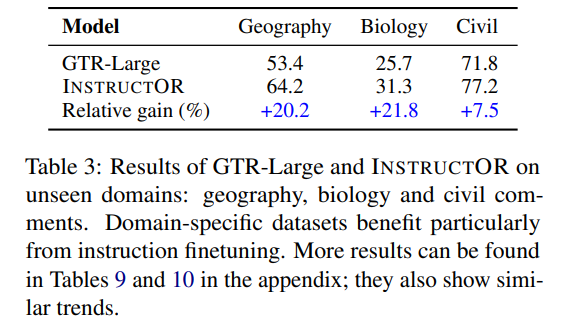
消融实验
我们使用T-SNE来可视化两个有和没有指令的分类示例。如图7所示,情感相同的点对距离更近,而情感不同的点对距离更远。
总结
本文的贡献有两点:
提出了INSTRUCTOR,一个使用自然语言指令创建广泛适用的文本嵌入的单模型。大量实验表明INSTRUCTOR在文本嵌入测试中达到了最先进的性能。
构建了MEDI数据集。
进NLP群—>加入NLP交流群















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









