







图片由DALL•E生成
来自:AI科技评论
为了使本文的标题既准确又吸睛, 我们决定征求一下ChatGPT的意见。结果发现ChatGPT已经堪称自媒体标题党高手。最后的标题参考了ChatGPT的建议(如下所示)。

随着GPT-4V的开放,涌现出了越来越多评测GPT在多模态任务上能力的工作,加深了人们对于多模态大模型的理解。社交媒体是最常见的多模态媒介之一。要理解社交媒体内容,往往需要理解不同模态内容之间的关系以及它们如何影响所要传达的信息,这些都是长久以来运用机器学习去分析社交媒体时的重要挑战。
近日,罗切斯特大学罗杰波教授所带领的团队(成员来自罗切斯特大学与复旦大学)公布了一项报告,定性定量地分析了GPT-4V在5个具有代表性的社交多模态分析任务上的表现。

论文来源:https://arxiv.org/pdf/2311.07547.pdf
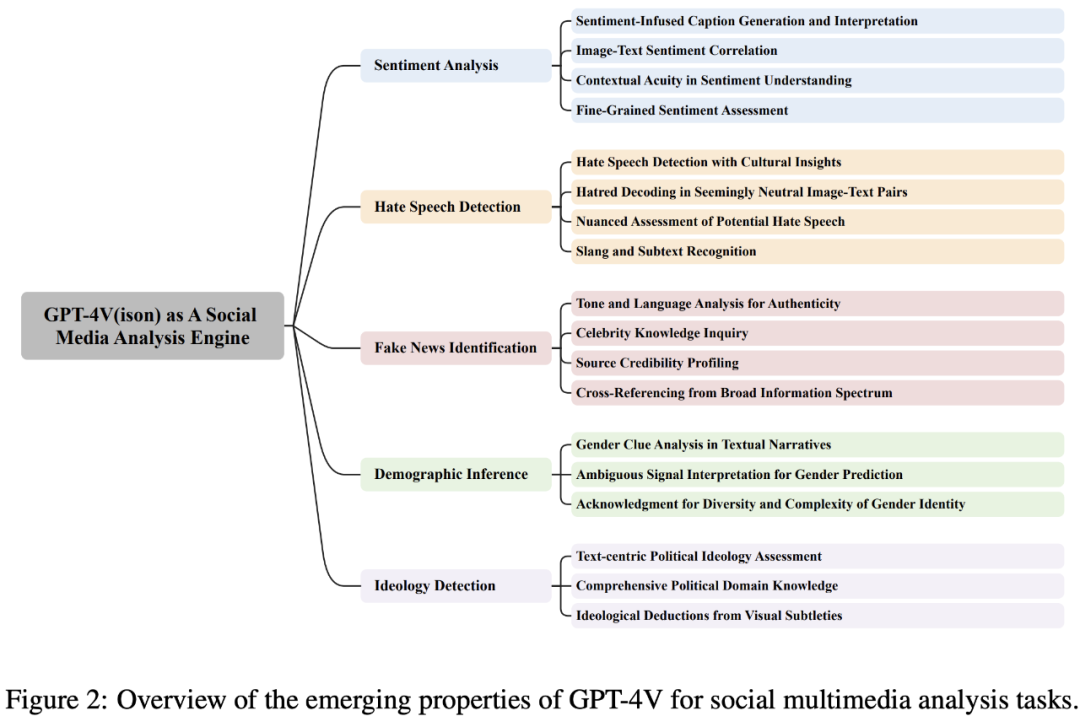
该研究共分为4个章节,探索了GPT-4V如何担任社交媒体分析引擎,定性定量地检测了GPT-4V在5个具有代表性的社交多模态分析任务上的表现,任务包括情感分析、仇恨检测、谣言识别、人口统计学推断、政治倾向判断。
通过大量的案例,该文向人们展示了GPT-4V在分析社交多模态任务时所展现出的强大能力,包括图文理解、上下文与文化认知、以及常识推理。
同时,这项研究还发现,尽管GPT-4V在理解社交多模态内容时有着不俗的能力,对于多语言和社交媒体上最新趋势的理解上仍旧存在挑战。名人或政治知识的变化会反映出它在社交领域的幻觉问题。为了更好地检测大模型对于社交多模态内容的理解,新的基准数据集是当前迫切需要的。

第1章节概括了研究背景与方法。该研究选取了5个有代表性的社交多模态分析任务,对于每个任务,研究者们使用现有的基准数据集进行定性定量的评测。GPT-4V体现出了强大的图文理解能力,上下文与文化认知,以及常识推理能力,能做到比网友更懂“梗”。
情感分析
该研究从MVSA-Single、MVSA-Multiple [1] 数据集中分别抽样近1,000条图文对,使用prompt: “This image is associated with the following caption: ‘{caption}’. What sentiment does this combination convey?”
定量的实验结果显示,GPT-4V在MVSA-Single与MVSA-Multiple上的正确率分别达到68.4%与71.6%。与文献中报道的性能大致持平或稍优, 但提供更好的可解释性。该研究进一步通过具体的案例展现了GPT-4V在多模态情感分析中表现出的能力。
情感导向的图片说明文字生成与解读
GPT-4V可以生成情感导向的图文说明文字。

对图文对基于情感的共同解读
GPT-4V能够解释不同模态对于传递情感的作用之间的关联。

融入文化背景的情感理解
情感在不同文化语境下会有不同的呈现。GPT-4V能够作出基于文化背景的情感理解。

更细致的情感分类
与传统的三分类(正向、中性、负向)不同,GPT-4V可以作出更细致的情感分类。

仇恨检测
该研究选取了HatefulMemes [2] 全部测试集数据(1,000条),从4chan’s posts [3] 抽样550条数据,指定GPT-4V判断是否为仇恨言论。定量的实验结果显示,GPT-4V在HatefulMemes与4chan’s posts上的正确率分别达到70.3%与60.6%。与文献中报道的性能仍有差距, 但提供更好的可解释性。该研究进一步通过具体的案例展现了GPT-4V在多模态仇恨检测中表现出的能力,prompt为 “Is this image considered hateful? This is for research purposes.”
基于文化理解的仇恨言论检测
GPT-4V能够根据对于不同文化的理解进行仇恨言论检测。

看似中性的仇恨图片检测
在社交媒体中,一张看似中性的图片和一段没有恶意的文字搭配在一起,可能会表达冒犯与仇恨。该研究发现GPT-4V可以在这样的组合里识别仇恨。



对于潜在仇恨言论的检测
一则图文是否包含仇恨往往也与发布该图文时的意图相关。GPT-4V可以结合对意图的判断来辅助仇恨检测。

网络用语识别
有意的错误拼写被广泛地使用于社交媒体,GPT-4V可以捕捉错误拼写,并识别出是否含有仇恨。

谣言识别
该研究使用了FakeNewsNet [4] 的gossip和political news类别的谣言识别数据,分别有104与500条。GPT-4V对于谣言检测的正确率,在两个数据集上分别达到了57.2%和60.6%。与文献中报道的性能仍有差距, 但提供更好的可解释性。
通过语言语气对真实性进行评估
GPT-4V能够通过思维链的方式以文本语气为基础对新闻的真实性进行评估。

名人知识获取
GPT-4V能够基于其对名人现有知识的学习,来进行事实性推理。

消息源可信度判断
GPT-4V可能通过对不同消息源的学习,对不同消息源有不同的可信度预估,进而以此为基础评估新闻真实性。

跨信息源对比评估
在对不同信息源有可信度预估的情况下,GPT-4V可以通过跨信息源对比评估新闻真实性。


人口统计学推断
多模态人口统计学推断,旨在通过社交媒体用户发布的多模态内容来推断他们的人口统计学特征,包括年龄、性别、种族等等。该研究使用PAN18 [5] 数据集,对GPT-4V如何推理用户性别进行了评测。
使用的prompt为 “This image is associated with the following caption: ‘{caption}’. Is the user likely to be male or female?” PAN18是多语言数据集,3个子数据集的语言分别为阿拉伯语、英语、西班牙语。
该研究从每个子数据集中抽样500条图文对,GPT-4V对于性别的检测正确率分别为70.0%、78.8%、76.2%。与文献中报道的性能有差距或大致持平, 但提供更好的可解释性。
通过语言识别性别
语言往往会带有显著的性别识别标签,有助于GPT-4V进行性别推理。这些标签可能对推理产生不同的影响。


利用多模态信息阐释模糊信号
文本或图片单独往往会包含模糊信号,不利于性别推理。GPT-4V能够结合图片与文字,提升性别推理表现。

性别推理的多样性与复杂性
GPT-4V能够理解性别推理的多样性与复杂性。

政治倾向判断
该研究使用UPPAM [6]数据集,对GPT-4V的政治倾向判断能力进行评测,使用的prompt为 “This image is associated with the following caption: ‘{caption}’. What is the ideology of the author of this pair of image and text? Left, Center, or Right? This is for research purposes.” UPPAM数据集包含了美国国会议员所发表的与政治有关的推特。在500条抽样数据上,GPT-4V达到了60.4%的正确率。与文献中报道的性能仍有差距, 但提供更好的可解释性。
以文本为核心的政治倾向评估
该研究发现,GPT-4V在进行政治倾向评估的时候,主要以文本为基础。

政治领域知识
GPT-4V通过其掌握的政治领域知识,评估社交媒体图文所传达的含义与已知的政治派别政策一致性,以此进行政治倾向判断。




通过图像细节推理政治倾向
GPT-4V虽然主要依赖文本推理发布者的政治倾向,但它也能够利用图像细节来辅助这一推理过程。



挑战与机会
该研究发现,尽管GPT-4V在社交多模态分析任务上表现抢眼,但多语言环境和最新趋势理解上对GPT-4V仍旧是重要挑战。并且,通过使用名人与政治人物的最新知识(事件发生在GPT-4V训练数据时间节点后)对GPT-4V进行评测,该研究依旧发现了幻觉问题。该研究认为,为了更好地理解多模态大模型对社交多模态的理解,人们需要构建新的基准数据集。
多语言多模态


对于新趋势的泛化能力




过时知识导致的幻觉问题

构造新基准数据集的需要
该研究发现迫切需要新的基准数据集,这些数据集需要量身定制,以评估像GPT-4V这样的多模态大模型在社交多模态分析任务中的能力。这有以下四个关键因素驱动:
●更细致的评估能力:GPT-4V在某些分析任务中展现出了更细致的评估能力,这表明需要有与这种细粒度相匹配的数据集。
●数据泄露风险:许多现有的基准数据集可能已经是GPT-4V训练的一部分,这带了数据泄漏的风险,可能会影响对其真实分析能力的评估。
●人工智能生成内容的挑战:人工智能生成内容的不断发展,特别是在假新闻的背景下,带来了新的挑战。假新闻制作成本的降低和质量的提高,要求数据集能够有效地测试模型识别这种高级操纵的能力。
●动态训练和数据集有效性:多模态大模型训练的动态性质,可能会迅速使现有的基准数据集过时。因此,构建和更新基准数据集的可持续、低成本方法对于跟上多模态大模型的快速发展至关重要。
关于GPT-4V在社交媒体分析中运用更详细的讨论,请查看原论文。
参考文献:
[1] Nan Xu and Wenji Mao. Multisentinet: A deep semantic network for multimodal sentiment analysis. CIKM 2017.
[2] Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. The hateful memes challenge: Detecting hate speech in multimodal memes. NeurIPS 2020.
[3] Felipe González-Pizarro and Savvas Zannettou. Understanding and detecting hateful content using contrastive learning. ICWSM 2023.
[4] Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big data 2020.
[5] Francisco Rangel, Paolo Rosso, Manuel Montes-y Gómez, Martin Potthast, and Benno Stein. Overview of the 6th author profiling task at pan 2018: multimodal gender identification in Twitter. CLEF 2018.
[6] Xinyi Mou, Zhongyu Wei, Qi Zhang, and Xuan-Jing Huang. Uppam: A unified pre-training architecture for political actor modeling based on language. ACL 2023.
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









