






深度学习自然语言处理 分享
整理:pp
 摘要:大语言模型建立在基于transformer的架构之上,用于处理文本输入。LLaMA 在众多开源实现中脱颖而出。同样的transformer能否用于处理二维图像?在本文中,我们将回答这个问题,揭开一个类似于 LLaMA 的视觉transformer的神秘面纱,它有plain和pyramid两种形式,被称为 VisionLLaMA,是专为此目的量身定制的。VisionLLaMA 是一个统一的通用建模框架,可用于解决大多数视觉任务。我们使用典型的预训练范式,对其在图像感知的大部分下游任务,特别是图像生成中的有效性进行了广泛评估。在许多情况下,VisionLLaMA 都比以前最先进的视觉transformer有大幅提升。我们相信,VisionLLaMA 可以作为视觉生成和理解的强大新基准模型。
摘要:大语言模型建立在基于transformer的架构之上,用于处理文本输入。LLaMA 在众多开源实现中脱颖而出。同样的transformer能否用于处理二维图像?在本文中,我们将回答这个问题,揭开一个类似于 LLaMA 的视觉transformer的神秘面纱,它有plain和pyramid两种形式,被称为 VisionLLaMA,是专为此目的量身定制的。VisionLLaMA 是一个统一的通用建模框架,可用于解决大多数视觉任务。我们使用典型的预训练范式,对其在图像感知的大部分下游任务,特别是图像生成中的有效性进行了广泛评估。在许多情况下,VisionLLaMA 都比以前最先进的视觉transformer有大幅提升。我们相信,VisionLLaMA 可以作为视觉生成和理解的强大新基准模型。
https://arxiv.org/abs/2403.00522
Q1: 这篇论文试图解决什么问题?
A:这篇论文试图解决的问题是如何将大语言模型(如LLaMA系列模型)的架构应用于视觉任务,特别是2D图像处理。具体来说,论文提出了以下几个挑战:
文本序列与视觉数据的差异:文本序列通常是一维的,而视觉数据(如图像)需要处理二维或更多维度的信息。
金字塔结构的需求:许多视觉任务依赖于金字塔结构来提高性能,而LLaMA是一个平面(plain)的编码器。
不同分辨率的输入图像和视频处理:需要处理不同分辨率的输入,这在传统的LLaMA模型中并不常见。
为了解决这些问题,论文提出了VisionLLaMA,这是一个类似于LLaMA的视觉transformer架构,旨在减少语言和视觉之间的架构差异。VisionLLaMA旨在作为一个统一和通用的建模框架,用于解决大多数视觉任务,包括图像理解和生成。论文通过在图像感知和生成的下游任务中进行广泛的预训练范式评估,展示了VisionLLaMA的有效性,并在许多代表性任务中显著超越了现有的视觉transformer。
Q2: 有哪些相关研究?
A:论文中提到的相关研究领域包括:
Vision Transformer (ViT):ViT成功地将Transformer架构从自然语言处理领域应用到视觉领域。后续工作如DeiT、Swin、PVT和Twins等,都在ViT的基础上进行了改进。
大型语言/多模态模型:如GPT4等专有模型在大型语言模型(LLM)竞赛中领先,但技术细节未公开。与之相对,社区发布了如BLOOM和LLaMA等开源模型,它们在性能上追赶GPT-3。
扩散模型 (Diffusion Models):扩散模型,如Denoising Diffusion Probabilistic Models (DDPMs)、基于分数的生成模型 (SGMs) 和无分类器扩散引导,已成为图像生成的新范式,超越了之前的GAN方法。
Transformer中的位置编码:Transformer最初使用二维绝对位置嵌入的正弦形式。相对位置编码和旋转位置编码 (RoPE) 被提出以编码位置信息,这些在大型语言模型中被证明是有效的。
遮蔽图像建模 (Masked Image Modeling):如BERT的扩展BEiT,通过预训练Transformer模型来预测离散视觉标记。MAE (Masked Autoencoder) 是一种自监督学习方法,通过遮蔽输入图像的随机块并训练自编码器来重建原始图像。
LLaMA架构的应用:LLaMA架构已被应用于资源受限的多模态场景,如移动电话,并显示出潜在的应用。
这些相关研究为VisionLLaMA的开发提供了技术背景和理论基础,同时也展示了在视觉和语言处理领域中,Transformer架构的广泛应用和潜在的改进空间。
Q3: 论文如何解决这个问题?
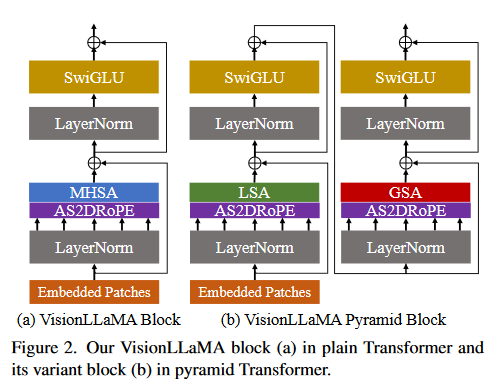
A:论文通过提出VisionLLaMA架构来解决将LLaMA模型应用于视觉任务的问题。具体解决方案包括以下几个关键点:
VisionLLaMA架构:提出了一个类似于LLaMA的视觉transformer架构,该架构旨在减少语言和视觉之间的架构差异。这个架构包括平面(plain)和金字塔(pyramid)两种形式,以适应不同的视觉任务需求。
自适应VisionLLaMA:研究了如何使VisionLLaMA适应常见的视觉任务,包括图像理解和创建。这涉及到在监督和自监督学习场景下评估VisionLLaMA的性能。
AS2DRoPE:引入了自适应缩放的2D旋转位置编码(AS2DRoPE),它扩展了1D旋转位置编码(RoPE)到2D,并使用插值缩放来适应任意分辨率的输入图像。

性能评估:在多个代表性任务(如图像生成、分类、语义分割和目标检测)上,通过广泛的实验表明,VisionLLaMA在许多情况下显著优于现有的视觉transformer,展示了更快的收敛速度和更好的性能。
代码开源:为了促进研究和应用,论文承诺将VisionLLaMA的代码在GitHub上公开。
通过这些方法,论文不仅解决了将LLaMA架构应用于视觉任务的挑战,而且还为视觉生成和理解提供了一个新的强大基线模型。
Q4: 论文做了哪些实验?
A:论文进行了一系列的实验来评估VisionLLaMA在不同视觉任务上的有效性。以下是主要的实验内容:
图像生成:
在DiT框架下,将VisionLLaMA应用于图像生成任务,与原始的DiT模型进行比较。
在SiT框架下,同样替换VisionLLaMA来评估其在图像生成任务中的表现。
ImageNet分类:
在ImageNet-1K数据集上进行有监督训练,比较VisionLLaMA与现有最佳平面视觉transformer(如DeiT3)的性能。
在不同分辨率的输入图像上评估模型的泛化能力。
自监督训练:使用MAE(Masked Autoencoder)框架进行自监督预训练,并在ImageNet验证集上进行线性探测(Linear Probing)评估。
ADE20K语义分割:在ADE20K数据集上进行有监督和自监督训练,评估VisionLLaMA在语义分割任务上的性能。
COCO目标检测:
在COCO数据集上进行有监督训练,使用Mask R-CNN框架评估VisionLLaMA在目标检测任务上的表现。
在ViTDet框架下进行自监督训练,进一步评估VisionLLaMA在目标检测任务中的性能。
消融研究:对VisionLLaMA的不同组件进行消融实验,包括FFN与SwiGLU、归一化策略、位置编码策略等,以理解各个组件对模型性能的影响。
讨论:分析VisionLLaMA快速收敛的原因,并从理论角度探讨其位置编码策略的优势。
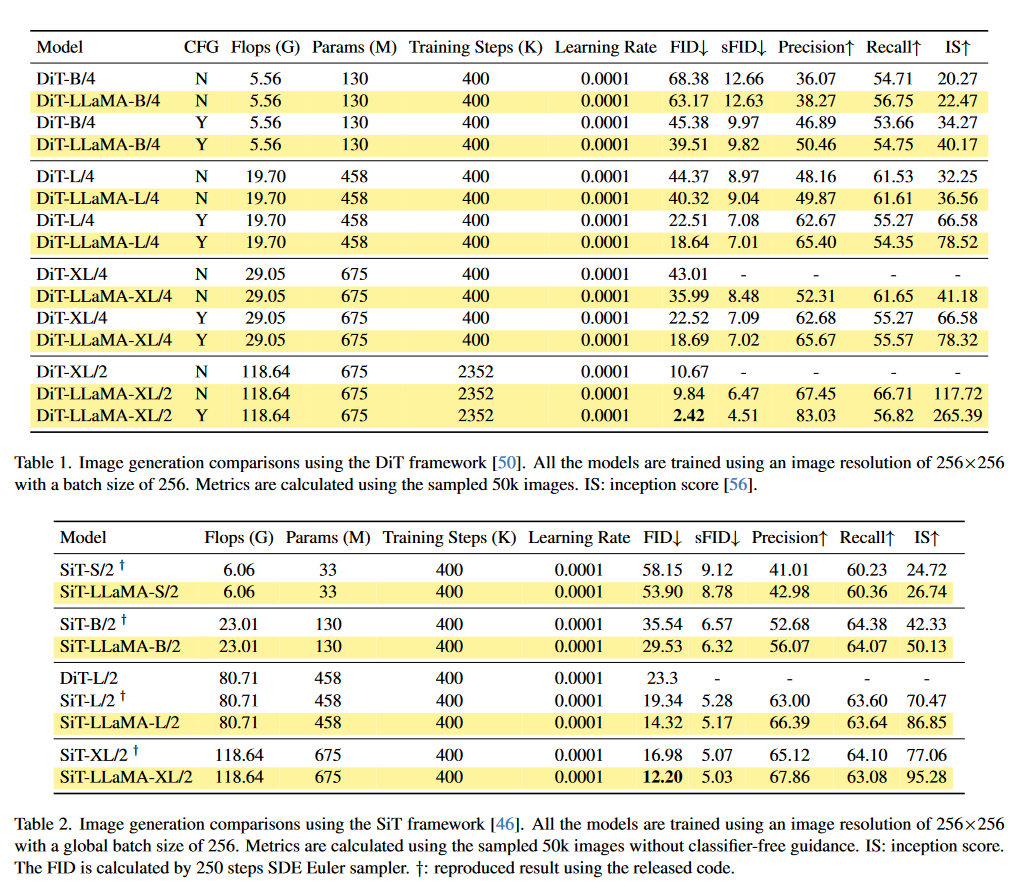
这些实验涵盖了从图像生成到目标检测的多个视觉任务,以及自监督学习场景,全面评估了VisionLLaMA的性能和潜力。通过这些实验,论文展示了VisionLLaMA在各种视觉任务中的有效性和优越性。
Q5: 有什么可以进一步探索的点?
A:尽管论文已经展示了VisionLLaMA在多个视觉任务中的有效性,但仍有一些潜在的研究方向可以进一步探索:
多模态学习:探索VisionLLaMA在结合视觉和语言信息的任务中的应用,例如图像描述、视觉问答(Visual Question Answering, VQA)和图像检索。
模型压缩和优化:研究如何进一步压缩VisionLLaMA模型以适应资源受限的环境,例如移动设备和嵌入式系统。
长序列处理:研究VisionLLaMA在处理长序列图像(如医学图像)或视频数据时的性能和效率。
模型泛化能力:评估VisionLLaMA在不同领域和不同分布的数据集上的泛化能力,以及如何提高其鲁棒性。
自监督学习策略:探索新的自监督学习策略,以提高VisionLLaMA在无标签数据上的学习能力。
模型解释性:研究VisionLLaMA的决策过程,提高模型的可解释性,以便更好地理解和信任其输出。
跨领域适应性:研究VisionLLaMA在跨领域任务中的适应性,例如从自然图像到卫星图像的迁移学习。
实时应用:针对需要实时反馈的应用场景(如自动驾驶、视频监控),优化VisionLLaMA的推理速度和延迟。
模型鲁棒性:研究如何提高VisionLLaMA对抗对抗性攻击(如对抗性扰动)的鲁棒性。
社会影响和伦理考量:评估VisionLLaMA在生成内容(如Deepfake)方面的潜在影响,并探讨相应的伦理和法律问题。
这些研究方向不仅有助于推动VisionLLaMA技术的发展,还能促进对大型视觉模型更深层次理解和更广泛的应用。
Q6: 总结一下论文的主要内容?
A:这篇论文提出了VisionLLaMA,这是一个针对视觉任务设计的统一transformer架构,旨在将LLaMA模型的成功应用于视觉领域。以下是论文的主要内容总结:
问题定义:论文首先定义了将LLaMA架构应用于视觉任务的挑战,包括处理2D图像、适应不同分辨率和金字塔结构的需求。
VisionLLaMA架构:提出了VisionLLaMA,这是一个类似于LLaMA的视觉transformer架构,包括平面和金字塔两种形式,以适应不同的视觉任务。
AS2DRoPE:引入了自适应缩放的2D旋转位置编码(AS2DRoPE),以适应不同分辨率的输入图像。
实验评估:在多个视觉任务上评估VisionLLaMA的性能,包括图像生成、分类、语义分割和目标检测。实验结果表明,VisionLLaMA在多个任务上显著优于现有的视觉transformer。
消融研究:通过消融实验分析了VisionLLaMA中不同组件的作用,如FFN与SwiGLU、归一化策略、位置编码策略等。
理论分析:探讨了VisionLLaMA快速收敛的理论原因,特别是其位置编码策略的优势。
结论:论文得出结论,VisionLLaMA具有强大的潜力,可以作为新的视觉主干模型,促进广泛的下游应用。
总的来说,这篇论文通过提出VisionLLaMA,展示了如何将大型语言模型的成功经验迁移到视觉领域,并在多个视觉任务上取得了显著的性能提升。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









