






© 作者|刘子康
机构|中国人民大学
研究方向|多模态大语言模型
来自:RUC AI Box
视觉指令微调是构建多模态大语言模型(MLLM)的核心步骤。现有的视觉指令构造方法主要有两类:基于大语言模型自动化构造,或是基于已有的多模态数据集构造。当前表现最好的多模态大语言模型往往将这些指令混合进行微调。尽管如此,对这些来自不同任务域的指令进行简单的混合可能会引入较大的冗余,导致更高的训练成本以及潜在的性能损失。为此,我们首先对当前混合指令集合中不同类型指令的有效性进行了实证性研究,并提出了一个新颖的指令筛选方法TIVE,从任务层面上和实例层面上对数据的价值进行了估计。最后,我们基于这些数据价值进行指令筛选,并达到数据高效的视觉指令微调。

论文题目:Less is More: Data Value Estimation for Visual Instruction Tuning
论文链接:https://arxiv.org/pdf/2403.09559.pdf
引言
视觉指令微调是构建多模态大语言模型(Multimodal Large Language Model, MLLM)的核心步骤。通过在精心设计的视觉指令上进行训练,大语言模型优秀的推理能力可以被很好的迁移到视觉场景上。因此,视觉指令集的构建对于多模态大语言模型的性能是至关重要的。一般而言,一条视觉指令包含了一张图片,一个文本指令以及预期的文本输出。现有的视觉指令构造方法主要有两类:基于大语言模型自动化构造,或是基于已有的多模态数据集构造。当前表现最好的多模态大语言模型往往将这些指令混合起来,在多模态问答任务以及多模态对话等任务上取得了很好的效果。
尽管如此,对这些来自不同任务域的指令进行简单的混合可能会引入较大的冗余,导致更高的训练成本以及潜在的性能损失。为了研究视觉指令集合中的冗余,我们首先对当前混合指令集合中不同类型指令的有效性进行了实证性研究。我们发现:(1) 混合指令中存在明显的冗余,筛选出一小部分指令进行微调就可以达到原有模型的性能,(2)不同类型的指令之间的冗余程度是不同的,预示着不同的任务指令对于提升模型性能的有效性有很大差异。
基于以上发现,我们提出了一个新颖的指令筛选方法TIVE。具体而言,TIVE从任务层面上和实例层面上对数据的价值进行了估计。在任务层面,我们基于某类任务中所有指令实例梯度模的平均值来估计这类任务对模型训练的重要性。在实例层面,我们基于某个实例的梯度向量与当前任务的平均梯度向量的相似度来估计单个实例在该类任务中的代表性。最后,我们基于这些数据价值进行指令筛选,并达到数据高效的视觉指令微调。
视觉指令数据的冗余性分析
1. 实验设置
给定一个视觉指令集,这个指令集中包含了大量不同任务域中的指令。我们通过逐步削减其中某一类任务指令的数量来观察它对模型训练的有效性,我们采用了LLaVA-1.5的视觉指令集作为目标指令。我们的目标模型同样采用了LLaVA-1.5。为了保证不同任务间的一致性,我们筛选了LLaVA-1.5指令集中的一个子集作为原始指令池,其中包含以下任务:
开放式视觉问答(OE-VQA):基于给定图像回答问题,答案可以是任意形式的。
多选视觉问答(MC-VQA):基于给定图像回答问题,答案被限制在若干选项中。
视觉指代理解(REC):对给定的位置信息生成正确的描述。
视觉对话(VC):基于图像进行对话。
图像描述(IC):基于给定图像生成正确描述。
文本对话(TC):在纯文本场景下生成对话。所有的任务指令均基于MSCOCO数据集,因此具有相似的数据分布。在实验中,我们逐步减少某类任务的指令数量,保持其他指令不变,以此来观察该任务指令对模型最终性能的影响。
2. 结果分析
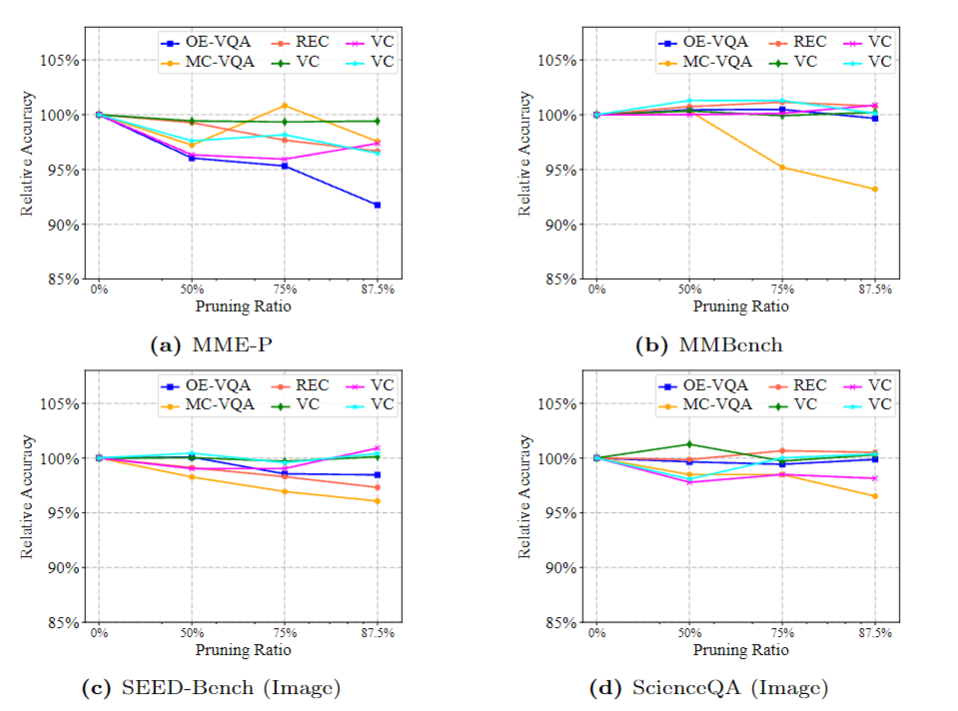
评测结果如上图所示。可以看到:(1)当前的视觉指令集中存在明显冗余,对某些任务指令的缩减几乎对模型性能没有任何影响。(2)不同任务指令冗余程度是不同的。对MC-VQA与OE-VQA的数量进行削减对模型性能造成了明显影响,而对VC的数量削减的影响则相当微小。总的来说,现有的视觉指令集合确实存在明显冗余,为了消减这些冗余,我们希望能够从任务层面与实例层面估计数据的价值,构造出一个更小的,但是能保留足够任务知识的指令子集来高效的微调大语言模型。
方法
为了消除视觉指令集中的冗余,我们提出了TIVE(Task-level and Instance-level Value Estimation),即任务层面与实例层面的数据价值度量。基于这两种度量方式,我们提出了一个数据筛选的范式,可以从原始指令集中筛选出一个有效的数据子集对大语言模型进行视觉指令微调。模型图如下所示:
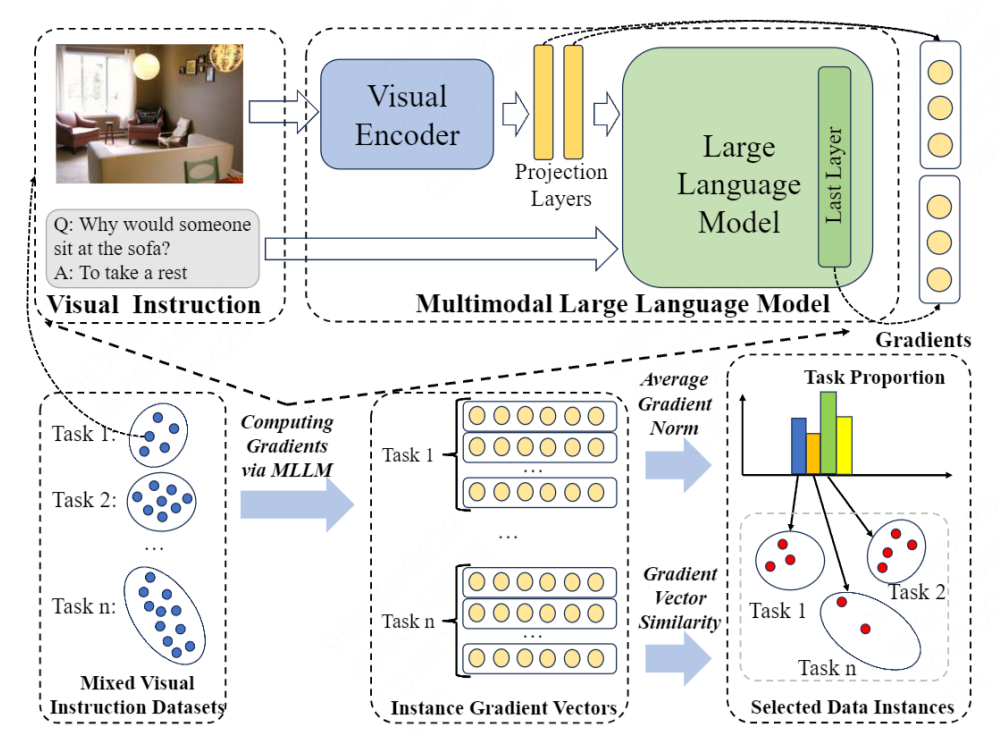
1. 问题定义
数据集的冗余削减致力于从原始数据集中筛选出一个有效的,有代表性的子集。在我们的工作中,我们聚焦在视觉指令集的冗余消除上。一个视觉指令集合包含了多个高度差异化的任务指令集。每个任务指令集都包含了若干个指令样例,用来表示。我们的目标是筛选出一个指令子集用于视觉指令微调。我们用来表示筛选出来的子集的大小。
特别的,我们基于一个简单预训练过了参考模型来进行子集筛选。首先,我们基于每个任务对模型训练的重要程度来估计每个任务的价值,这个价值会用于判断每个任务在最终筛选集合中的所占比例。接着,我们估计单个任务指令集内部不同样例的价值,用于筛选出对该任务具有代表性的任务样例。
2. 任务层面的价值估计
在这个部分,我们的目标是分辨出对模型训练影响较大的任务,并对它们设置更高的价值。由于多模态大语言模型需要对任务样例进行微调,具备更高梯度的任务样例会对模型的参数有更大的更新量,因而对模型的最终性能有更大的潜在影响。因此,我们考虑基于梯度的范数来估计每个任务的价值。
然而,对模型的所有参数进行计算是昂贵的。为了降低开销,我们仅仅计算了模型的部分重要参数的梯度矩阵,包含了视觉编码器与大语言模型的连接部分与大语言模型的输出层。这些参数矩阵对模型进行视觉-文本对齐以及最终的文本输出起了重要作用,因此它们的梯度是具有代表性的。对某个实例,它的梯度范数可以计算如下:
其中, 代表着上述提到的梯度矩阵,而代表着参数对应的梯度部分。我们通过这个公式计算了单个任务样例的梯度,然而,某个任务集中可能存在噪声数据或是错误数据,可能带来不正常的高梯度。为了减少这些数据噪声的影响,我们对所有任务样例的梯度范数取均值作为最终的任务价值,如下所示:
3. 实例层面的价值估计
除了上述的任务价值之外,我们还需要对每个任务样例的价值进行估计。为了估计每个任务样例的代表性,我们计算了它与该任务平均梯度向量的相似度。如果单个样例的梯度向量与这个任务的平均梯度向量是相似的,那么基于这个样例进行微调可能与基于所有任务样例进行微调对模型的更新也是相似的,因此具有更高的代表性。形式化来讲,任务指令集中的样例的数据价值可以计算如下:
其中,代表着任务样例梯度向量,而表示了两个梯度向量的余弦相似度。
4. 数据子集筛选
在这一节,我们将介绍如何基于上述提出的数据价值进行数据筛选。
参考模型训练
为了高效的对梯度进行计算,我们采样了一小部分数据来对参考模型进行训练。粗略的来讲,我们从所有任务中采样了大约2%的数据作为参考模型的训练数据。这样,参考模型可以学到基础了指令遵循能力,但不会过拟合到若干特殊的数据点。这样,基于参考模型计算的梯度可以更好的反应样例对模型训练的影响以及其代表性。
基于数据价值进行数据采样
在数据价值的计算后,我们可以对总指令集进行采样。首先,我们通过任务价值来确定数据子集中每个任务集所占比例。目标数据子集包含了与原指令集相同的任务数量,但改变了指令总数以及每个任务所占比例。对于每个任务子集,我们对该任务在目标指令子集的比例计算如下:
基于计算好的数据分布,我们可以通过每个任务所占比例乘以目标指令子集的总数量,确定目标子集中每个任务的指令所占数量。然后,我们基于实例价值来从原始指令集进行指令筛选。在这里,我们对实例价值与任务价值进行相乘,我们这样做是为了保证我们的方法对更高价值的任务筛选出了更加具有代表性的样例,而对相对较低价值的任务筛选更加多样化的样例。接着,我们通过sigmoid函数来对这些实例价值进行规范化,得到一个采样权重:
其中, 是用于控制分数分布的超参数。在对每个任务指令集进行筛选后,我们对所有筛选出的指令进行合并得到最终的任务子集。
实验
1. 实验设置
指令池:我们遵循了在第二节中的设定,使用LLaVA-1.5的指令作为原始视觉指令池。我们的指令包含了四种任务类型:OE-VQA,MC-VQA,REC与VC。这些任务包含了LLaVA-1.5指令中的绝大多数任务。我们没有使用IC与TC指令是由于这两种指令分别在文本指令微调与一阶段对齐中使用过,且对模型性能没有明显影响。
基线:我们将我们的方法与以下数据筛选的基线方法进行了比较:(1)Random:随机的采样数据;(2)Instruction Length:基于指令长度选择数据;(3)Perplexity:基于指令样例的困惑度选择数据;(4)GraNd:基于单个样例的梯度范数来选择数据;(5)EL2N:基于单个样例的差异向量的范数选择数据。
评测基准:我们采取了与LLaVA-1.5相同的评测基准,包含了MME,SEED-Bench,MMBench,ScienceQA,POPE等多个指标综合评价了多模态大语言模型的能力。
2. 实验结果
我们的主实验结果如下所示。
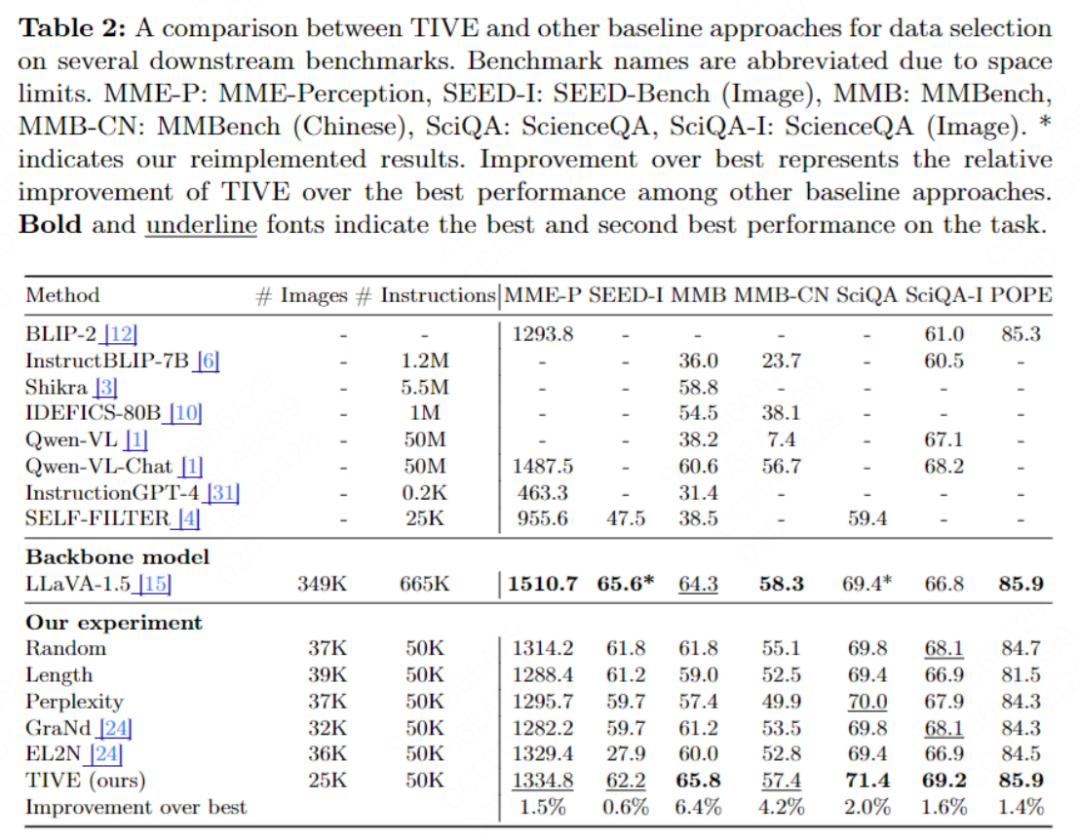
基于以下结果,我们有以下发现:
传统的数据选择方法(GraNd与EL2N)在视觉指令的筛选上表现不佳。一个潜在的原因是这些选择出的样例都倾向于选择梯度较高的数据,这类数据可能包含明显的噪声,对模型性能有负面影响。
对文本指令微调中常用的数据筛选方法(Length与Perplexity),模型的性能仍然不令人满意。这些数据往往倾向于选择出能提升多模态文本生成能力的样本,而忽略了模型的视觉理解能力。同时,这类方法选择出来的任务指令往往是不平衡的,也导致了性能的下降。
我们将我们的方法与所有的方法进行了对比,仅用了50K的视觉指令数据,TIVE在部分任务上表现出了与原始的完整665K微调的LLaVA-1.5模型相似的性能。与LLaVA-1.5相比,我们可以仅仅使用7.5%的总数据,达到至少88%的性能,甚至在4个下游基准上超过了LLaVA-1.5。这些结果表明了TIVE有效的消除了LLaVA-1.5指令集中的数据冗余。
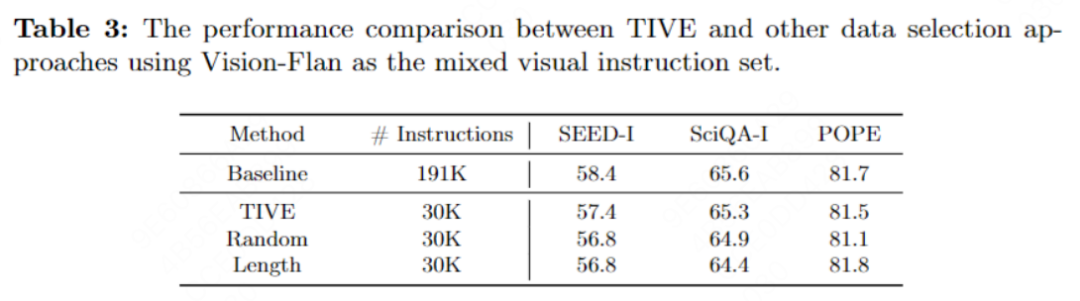
我们同时在Vision-Flan上进行了实验。Vision-Flan包含了191个任务,每个任务包含了1000的样本。我们将Vision-Flan的所有任务归类到7个大的任务集合,并应用了TIVE做数据筛选。筛选后,我们可以通过16.7%的数据,在下游任务上达到95%的性能,表明TIVE在不同指令集上也是可以迁移的。
3. 消融实验
数据价值的有效性:为了验证任务层面与实例层面数据价值估计的有效性,我们进行了一系列的消融实验,包括不采用数据价值筛选,仅采用任务层面的数据价值与仅采用实例层面的数据价值,我们的结果如下所示:
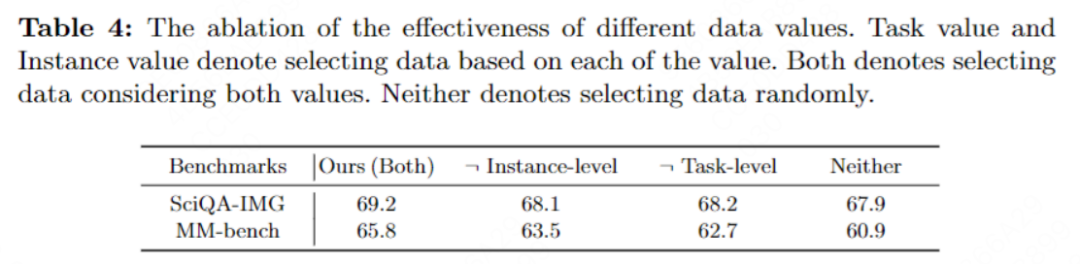
可以看到,两种数据价值均可以提升模型的性能,而同时基于两种数据价值进行筛选则达到了最好的表现,验证了两种数据价值同时都是有效的。
不同数据量下的模型表现:为了探索模型性能随数据规模的改变趋势,我们进行了一系列的实验,通过改变不同的目标指令集大小来探索这一趋势。我们在所有实验中保证了数据筛选方法的一致性,实验结果如Fig.3a所示:

可以看到,模型的性能随着数据规模的增大持续提升,但提升的趋势在不同评测基准上是不同的。模型在MME-P上的性能持续提升,而在MM-Bench与SciQA-IMG上,模型的性能一开始有明显提升,然后稳定下来。一个可能的原因是MME-P基准倾向于评测模型在不同类别的图像上的识别能力,而另外两种基准则主要评测模型的推理能力。我们同时发现了即使是很小的数据规模下,模型依然能够有不错的能力,暗示着模型的基础能力在训练的很早期就已经达到。
不同超参 对数据筛选的影响:为了保证数据有效性与多样性的平衡,我们在计算采样权重时引入了超参数 。我们研究了不同的超参数对采样数据集的影响,实验结果如Fig.3b所示。
可以看到,模型在MME-P上的表现随着的增加而略微减少,而在MM-Bench与ScienceQA-Image上的表现先增加,后降低。这些结论与此前的结论是一致的,表明MME-P对指令的多样性非常敏感。另一方面,MM-Bench与ScienceQA-Image的表现先随着的增加而增加,当增加到0.1时开始下降,也验证了的确是一个理想的超参数设置。
结论
在这篇工作中,我们主要聚焦在当前的混合视觉指令集中的冗余问题。通过我们的实验性分析,我们发现当前的视觉指令集确实存在明显冗余,且这些冗余在不同任务指令间是不同的。为了消除这些冗余,我们提出了一个新颖的数据筛选方法,TIVE,来估计任务层面与实例层面的数据价值,确定目标指令集中新的任务占比,并在每个任务中筛选出具有代表性的任务样例。实验结果表明,基于我们的数据筛选方法,只采用7.5%的视觉指令,就可以达到与全指令微调模型相近的结果,甚至在若干个基准上还能有更优的表现。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









