







这篇文章的标题是《Unified Active Retrieval for Retrieval Augmented Generation》,作者是Qinyuan Cheng等人,来自复旦大学和上海人工智能实验室。文章主要研究了在检索增强型生成(Retrieval-Augmented Generation, RAG)中,如何智能地决定何时使用检索来增强大型语言模型(LLMs)的输出。
文章指出,在RAG中,并非所有情况下检索都是有益的,对每个指令都应用检索是次优的。因此,确定是否进行检索对于RAG来说至关重要,这通常被称为主动检索(Active Retrieval)。现有的主动检索方法面临两个挑战:
它们通常依赖单一标准,难以处理各种类型的指令;
它们依赖于专业化和高度差异化的程序,这使得将它们结合到RAG系统中更加复杂,并导致响应延迟增加。
为了解决这些挑战,文章提出了一种名为统一主动检索(Unified Active Retrieval, UAR)的新框架。UAR包含四个正交标准,并将它们转化为即插即用的分类任务,以最小的额外推理成本实现多方面的检索时机判断。文章还引入了统一主动检索标准(UAR-Criteria),旨在通过标准化程序处理多种主动检索场景。
通过在四种代表性用户指令类型的实验中,UAR在检索时机判断和下游任务性能上显著优于现有工作,证明了UAR的有效性及其对下游任务的帮助。文章的贡献包括提出了UAR这一主动检索框架,创建了评估检索时机准确性的Active Retrieval Benchmark(AR-Bench),并在AR-Bench和下游任务上进行了全面的实验,展示了UAR的显著性能提升。此外,作者还发布了代码、数据、模型和相关资源,以促进未来的研究。
这篇论文试图解决什么问题?
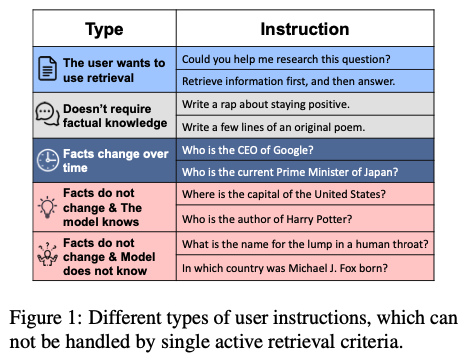
这篇论文试图解决的主要问题是在检索增强型生成(Retrieval-Augmented Generation, RAG)系统中,如何有效地决定何时应该使用检索来辅助大型语言模型(LLMs)生成更准确和有用的响应。具体来说,论文针对以下两个关键问题提出了解决方案:
单一标准的限制:现有的主动检索方法通常依赖于单一的标准或准则来判断是否需要进行检索,这在面对多样化的用户指令时显得不够灵活,难以适应不同场景的需求。
系统复杂性和延迟:依赖于专业化和高度差异化的程序使得RAG系统变得更加复杂,并且增加了响应的延迟,这对于实时应用来说是不利的。
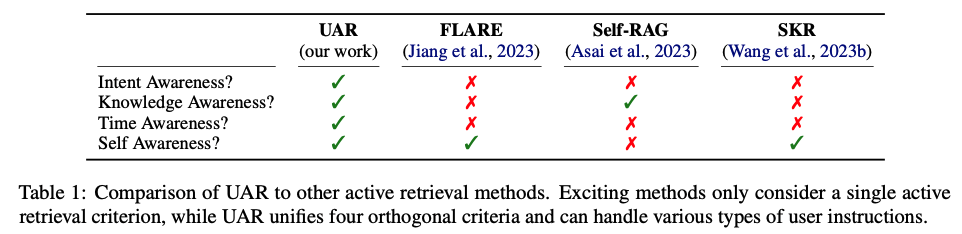
为了克服这些问题,论文提出了统一主动检索(Unified Active Retrieval, UAR),这是一个综合框架,通过以下方式改进主动检索的决策过程:
多标准集成:UAR结合了四个正交的检索时机判断标准(意图意识、知识意识、时效性意识和自我意识),以更全面地评估是否需要进行检索。
即插即用分类任务:通过将这些标准转化为轻量级的分类任务,UAR能够在几乎不增加额外推理成本的情况下,实现对检索时机的多方面判断。
标准化处理流程:引入UAR-Criteria,为不同的主动检索场景提供了一个统一的处理流程,简化了系统集成,并提高了效率。
总的来说,这篇论文旨在通过更智能的检索决策机制,提高RAG系统在现实世界应用中的有效性和响应速度。
有哪些相关研究?
文章中提到了与主动检索(Active Retrieval)相关的一些研究工作,以下是一些主要的相关研究:
Self-RAG (Asai et al., 2023): 这是一种基于LLM自我意识的方法,只有在模型认为它不知道答案时才触发检索。
FLARE (Jiang et al., 2023): 这种方法基于模型对其生成响应的不确定性来决定是否需要外部检索。
SKR (Wang et al., 2023b): 首先确定模型是否知道问题的答案,如果不知道,则使用检索增强。
RA-ISF (Liu et al., 2024): 与SKR类似,首先评估模型是否知道问题的答案,然后决定是否进行检索。
Self-DC (Wang et al., 2024): 这种方法探讨了何时应该检索和何时应该生成答案,采用自划分和征服的方法处理组合未知问题。
文章还提到了其他一些与大型语言模型的时间意识(Time-awareness)和自我意识(Self-awareness)相关的研究,例如:
TimeQA (Chen et al., 2021): 用于评估模型处理时效性问题的能力。
MULAN (Fierro et al., 2024): 用于评估语言模型预测可变事实的能力。
关于自我意识的研究 (Kadavath et al., 2022; Lin et al., 2022a; Yin et al., 2023; Zhang et al., 2023; Cheng et al., 2024): 这些研究探讨了如何增强语言模型对自己知识范围的认识和表达。
这些相关研究为UAR提供了背景和对比,展示了在主动检索领域中不同方法的优缺点,以及UAR如何通过综合多个标准来改进检索时机的判断。
论文如何解决这个问题?

论文通过提出统一主动检索(Unified Active Retrieval, UAR)框架来解决检索增强型生成(RAG)系统中的检索时机判断问题。以下是UAR框架解决这个问题的关键步骤和方法:
多标准集成:UAR不依赖单一标准,而是将四个正交的检索时机判断标准集成到一个框架中。这些标准包括意图意识(Intent-aware)、知识意识(Knowledge-aware)、时效性意识(Time-aware)和自我意识(Self-aware)。
轻量级分类器:对于每个检索标准,UAR使用轻量级的二分类器(例如单层多层感知机,MLP),这些分类器基于固定大型语言模型(LLM)的最后一层隐藏状态来训练。这种方法避免了对整个LLM进行昂贵的微调,并减少了推理成本。
统一的检索判断流程:UAR引入了统一主动检索标准(UAR-Criteria),这是一个决策树,它根据多个检索标准设定的优先级顺序,统一地判断何时需要进行检索。
即插即用(Plug-and-play):UAR作为一个即插即用的框架,不需要改变LLM的参数,可以轻松地集成到现有的RAG系统中。
标准化处理流程:UAR-Criteria通过标准化的流程处理各种用户指令,确保在不同场景下都能做出一致的检索决策。
实验验证:论文通过在四种代表性的用户指令类型上进行实验,验证了UAR在检索时机判断准确性和下游任务性能上的显著优势。
资源发布:为了促进未来的研究,作者还发布了UAR的代码、数据、模型和相关资源。
通过这些方法,UAR框架能够有效地解决何时应该使用检索来辅助LLM生成响应的问题,同时避免了不必要的检索,提高了系统效率和响应速度。
论文做了哪些实验?
论文中进行了以下几类实验来验证所提出的统一主动检索(UAR)框架的有效性:
检索时机判断准确性评估:作者创建了一个名为Active Retrieval Benchmark (AR-Bench)的评估基准,它包括四个子任务:意图意识(intent-aware)、知识意识(knowledge-aware)、时效性意识(time-aware)和自我意识(self-aware)。这些任务都是二元分类任务,用于分别评估单一主动检索标准。AR-Bench包含了8000个样本,正例和负例的比例为1:1,并且这些样本不与UAR的训练数据重叠。
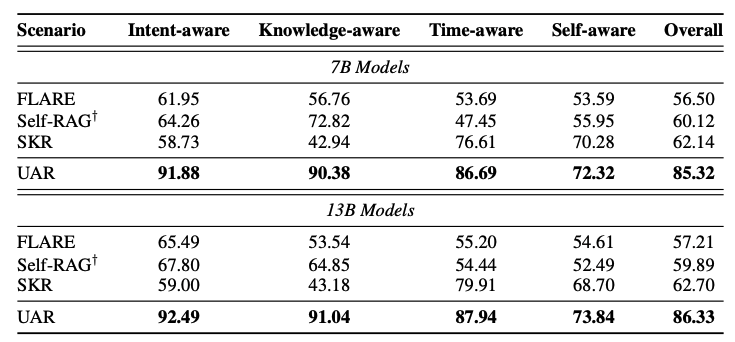
下游任务性能测试:为了测试UAR在真实下游任务中的性能和适应性,作者选择了六个数据集,覆盖了知识意识、时效性意识和自我意识三种场景。这些数据集包括:

DROP和GSM8K:用于评估知识意识场景。
TAQA和FreshQA:用于评估时效性意识场景。
TriviaQA和WebQuestions (WQ):用于评估自我意识场景。
与现有方法的比较:作者将UAR与几种现有的主动检索方法进行了比较,包括FLARE、Self-RAG和SKR。这些比较在AR-Bench和下游任务上进行,以评估不同方法在检索时机判断准确性和下游任务性能上的表现。
不同模型大小的比较:实验还包括了对7B(7亿参数)和13B(130亿参数)大小的模型进行比较,以评估模型大小对UAR性能的影响。
检索调用比例分析:在下游任务的评估中,作者还报告了检索被调用的样本比例,以展示UAR在避免不必要的检索方面的效果。
对模型性能的影响分析:作者分析了单个分类器与UAR整体性能的比较,以及使用整个LLM作为分类器与仅使用值头(value head)的比较。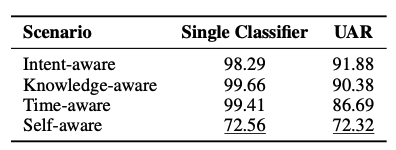
参考文档数量对模型性能的影响:作者评估了在TriviaQA和WebQuestions数据集上,改变参考文档数量(从1到10)对模型性能的影响。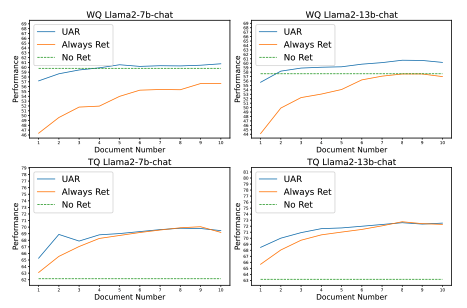
通过这些实验,论文展示了UAR在不同方面显著优于现有主动检索方法,证明了其在检索时机判断和下游任务性能上的有效性。
有什么可以进一步探索的点?
论文在最后提到了几个潜在的研究方向和局限性,可以作为未来研究进一步探索的点:
多检索调用的实现:论文的实验主要集中在生成短文本和单个检索调用的场景。未来的研究可以探索如何在更长的文本响应中实现多个主动检索调用。
检索标准的扩展:UAR的主动检索标准主要基于实际应用中的经验,可能忽略了一些检索场景。未来的工作可以考虑更广泛的应用场景,以识别和包含更多的检索标准。
使用更深层次的网络:论文中使用的分类器是基于单层多层感知机(MLP)网络。研究者可以探索使用更深层次的网络结构,以进一步提高性能。
检索时机的更精细控制:虽然UAR提供了一个统一的框架,但检索时机的更精细控制和优化仍然是一个值得探索的领域。
跨领域和多语言的支持:UAR当前的研究可能主要集中在特定领域或语言。扩展UAR以支持跨领域和多语言的检索增强生成任务是一个挑战。
提高模型的可解释性:提高UAR中检索决策过程的可解释性,帮助用户和开发者更好地理解模型的行为。
优化模型的效率和速度:尽管UAR是一个轻量级的框架,但仍有进一步优化模型效率和推理速度的空间,特别是在资源受限的环境中。
增强模型的鲁棒性:研究如何使UAR更加鲁棒,能够更好地处理错误或误导性的信息,提高在面对复杂和不确定环境时的稳定性。
用户意图的更准确识别:在主动检索中,准确识别用户的检索意图是一个关键问题。研究如何利用更先进的技术来更好地理解和预测用户意图。
集成用户反馈:考虑用户的反馈来动态调整检索策略,使系统能够根据用户的满意度来优化其性能。
这些点提供了未来研究的潜在方向,可以帮助改进和扩展UAR框架,以及检索增强型生成系统的应用范围和效能。
总结一下论文的主要内容
这篇论文的主要内容可以概括为以下几个要点:
问题识别:论文指出在检索增强型生成(RAG)中,决定何时使用检索来辅助大型语言模型(LLMs)生成响应是一个关键问题。现有的主动检索方法依赖单一标准,难以应对多样化的指令,且增加了系统的复杂性和响应延迟。
UAR框架提出:为了解决这些问题,论文提出了统一主动检索(Unified Active Retrieval, UAR)框架。UAR通过集成四个正交的检索时机判断标准(意图意识、知识意识、时效性意识、自我意识),将它们转化为轻量级的分类任务。
UAR-Criteria:引入了统一主动检索标准(UAR-Criteria),一个标准化的多面决策树,用于统一处理不同场景下的检索需求。
实验验证:通过在四种类型的用户指令上进行实验,论文验证了UAR在检索时机判断准确性和下游任务性能上显著优于现有工作。
资源发布:作者发布了UAR的代码、数据、模型和相关资源,以促进未来的研究。
贡献总结:论文的贡献包括提出了UAR这一新的主动检索框架,创建了评估检索时机准确性的AR-Bench基准,并在AR-Bench和下游任务上进行了全面的实验。
局限性讨论:论文讨论了其局限性,包括实验主要集中在短文本生成、单一检索调用,以及UAR的主动检索标准可能忽略某些场景等。
未来研究方向:论文提出了未来研究的方向,包括实现多检索调用、扩展检索标准、使用更深层次网络结构等。
总的来说,这篇论文通过提出UAR框架,为提高RAG系统中检索调用的效率和准确性提供了一种新的解决方案,并通过实验验证了其有效性。
本文由kimi+人工共同完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









