






来自:YeungNLP
此前,我们更多专注于大模型训练方面的技术分享和介绍,然而在完成模型训练之后,上线推理也是一项非常重要的工作。后续,我们将陆续撰写更多关于大模型推理优化的技术文章,包括但不限于KV Cache、PageAttention、FlashAttention、MQA、GQA等。
在本文中,我们将详细介绍KV Cache,这是一种大模型推理加速的方法。正如其名称所示,该方法通过缓存Attention中的K和V来实现推理优化。
01
大模型推理的冗余计算
我们先简单观察一下基于Decoder架构的大模型的生成过程。假设模型只是一层Self Attention,用户输入“中国的首都”,模型续写得到的输出为“是北京”,模型的生成过程如下:
将“中国的首都”输入模型,得到每个token的注意力表示(绿色部分)。使用“首都”的注意力表示,预测得到下一个token为“是”(实际还需要将该注意力表示映射成概率分布logits,为了方便叙述,我们忽略该步骤)。
将“是”拼接到原来的输入,得到“中国的首都是”,将其输入模型,得到注意力表示,使用“是”的注意力表示,预测得到下一个token为“北”。
将“北”拼接到原来的输入,依此类推,预测得到“京”,最终得到“中国的首都是北京”

在每一步生成中,仅使用输入序列中的最后一个token的注意力表示,即可预测出下一个token。但模型还是并行计算了所有token的注意力表示,其中产生了大量冗余的计算(包含qkv映射,attention计算等),并且输入的长度越长,产生的冗余计算量越大。例如:
在第一步中,我们仅需使用“首都”的注意力表示,即可预测得到“是”,但模型仍然会并行计算出“中国”,“的”这两个token的注意力表示。
在第二步中,我们仅需使用“是”的注意力表示,即可预测得到“北”,但模型仍然会并行计算“中国”,“的”,“首都”这三个token的注意力表示。
02
Self Attention
KV Cache正是通过某种缓存机制,避免上述的冗余计算,从而提升推理速度。在介绍KV Cache之前,我们有必要简单回顾self attention的计算机制,假设输入序列长度为 ,第 个token对于整个输入序列的注意力表示如下公式: 第 个token对于整个输入序列的注意力表示的计算步骤大致如下:
向量映射:将输入序列中的每个token的词向量分别映射为 三个向量。
注意力计算:使用 分别与每个 进行点乘,得到第 个token对每个token的注意力分数。
注意力分数归一化:对注意力分数进行softmax,得到注意力权重。
加权求和:注意力权重与对应的向量 加权求和,最终得到第 个token的注意力表示。
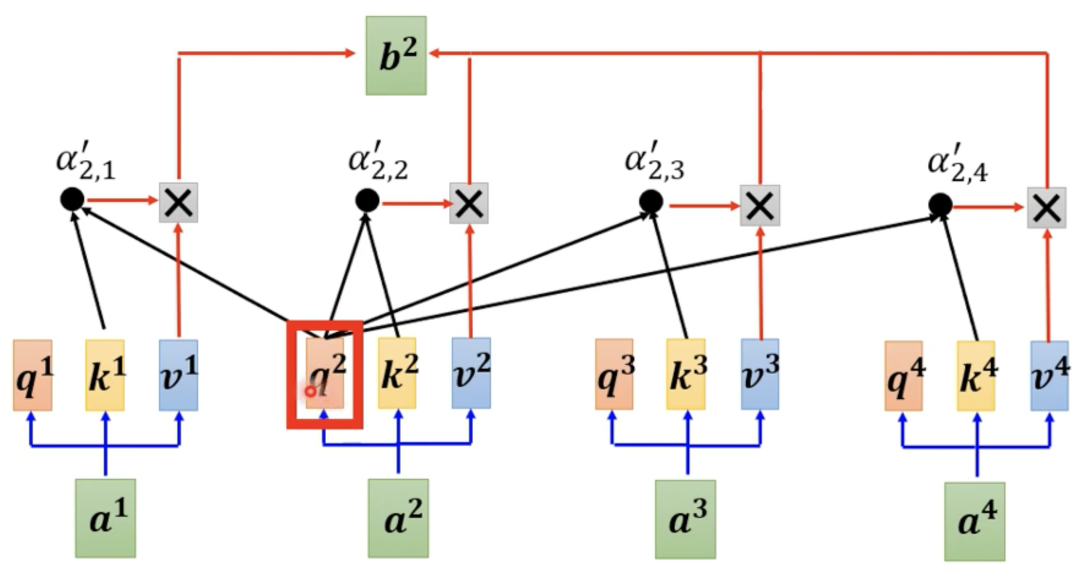
下面将以图像的方式帮助大家更形象地理解Self Attention。假设输入序列 , 对于整个输入序列 的注意力表示为 ,它的计算过程如下图所示, 。

继续观察 对于整个输入序列 的注意力表示 ,它的计算过程如下图所示 。
03
KV Cache
在推理阶段,当输入长度为 ,我们仅需使用 即可预测出下一个token,但模型却会并行计算出 ,这部分会产生大量的冗余计算。而实际上 可直接通过公式 算出,即 的计算只与 、所有 和 有关。
KV Cache的本质是以空间换时间,它将历史输入的token的 和 缓存下来,避免每步生成都重新计算历史token的 和 以及注意力表示 ,而是直接通过 的方式计算得到 ,然后预测下一个token。
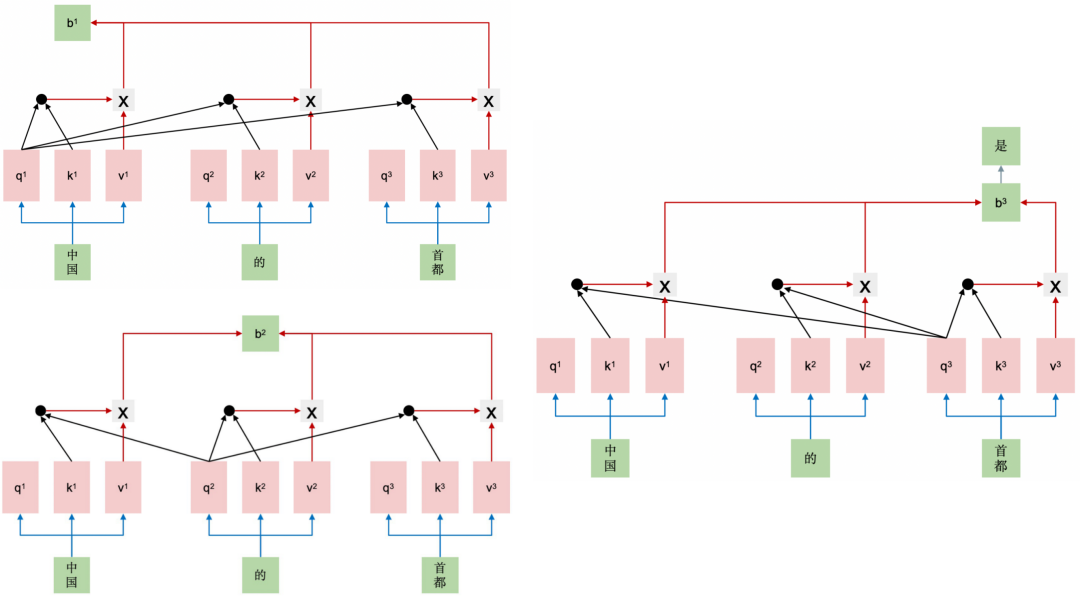
举个例子,用户输入“中国的首都”,模型续写得到的输出为“是北京”,KV Cache每一步的计算过程如下。
第一步生成时,缓存 均为空,输入为“中国的首都”,模型将按照常规方式并行计算:
并行计算得到每个token对应的 ,以及注意力表示 。
使用 预测下一个token,得到“是”。
更新缓存,令 , 。
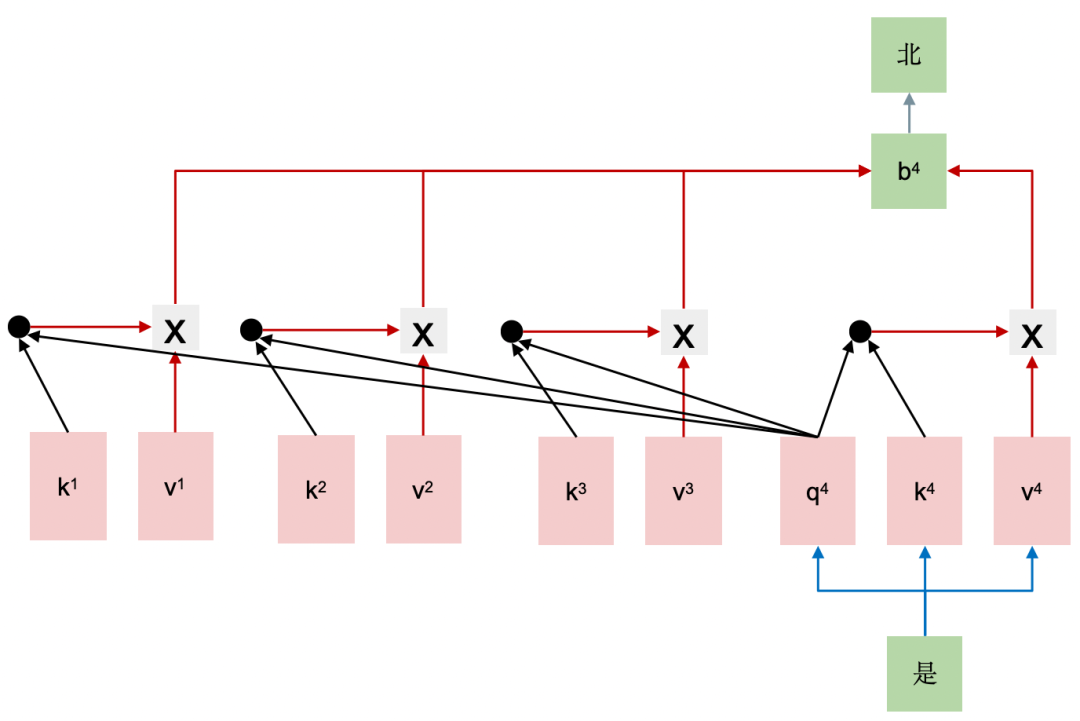
第二步生成时,计算流程如下:
仅将“是”输入模型,对其词向量进行映射,得到 。
更新缓存,令 , 。
计算 ,预测下一个token,得到“北”
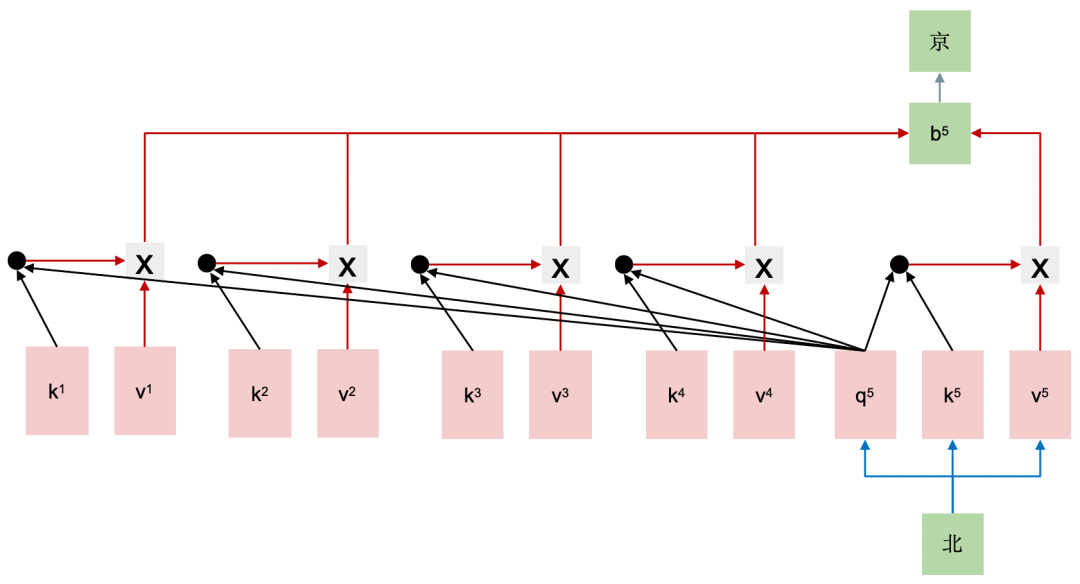
第三步生成时,计算流程如下:
仅将“北”输入模型,对其词向量进行映射,得到 。
更新缓存,令 , 。
计算 ,预测下一个token,得到“京”。
上述生成流程中,只有在第一步生成时,模型需要计算所有token的 ,并且缓存下来。此后的每一步,仅需计算当前token的 、、 ,更新缓存 、 ,然后使用 、、 即可算出当前token的注意力表示,最后用来预测一下个token。
Hungging Face对于KV Cache的实现代码如下,结合注释可以更加清晰地理解其运算过程:
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim) # 当前token对应的query
key = self._split_heads(key, self.num_heads, self.head_dim) # 当前token对应的key
value = self._split_heads(value, self.num_heads, self.head_dim) # 当前token对应的value
if layer_past is not None:
past_key, past_value = layer_past # KV Cache
key = torch.cat((past_key, key), dim=-2) # 将当前token的key与历史的K拼接
value = torch.cat((past_value, value), dim=-2) # 将当前token的value与历史的V拼接
if use_cache is True:
present = (key, value)
else:
present = None
# 使用当前token的query与K和V计算注意力表示
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)KV Cache是以空间换时间,当输入序列非常长的时候,需要缓存非常多k和v,显存占用非常大。为了缓解该问题,可以使用MQA、GQA、Page Attention等技术,在后续的文章中,我们也将对这些技术进行介绍。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦














 3693
3693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









