







论文:Following Length Constraints in Instructions
链接:https://arxiv.org/pdf/2406.17744
这篇文章的标题是《Following Length Constraints in Instructions》,作者是Weizhe Yuan、Ilia Kulikov、Ping Yu、Kyunghyun Cho、Sainbayar Sukhbaatar、Jason Weston和Jing Xu,来自Meta FAIR和纽约大学。文章主要探讨了在人工智能领域,特别是在指令遵循模型中,如何处理和优化输出响应的长度限制问题。
以下是对文章内容的简单解读:
问题引入:文章指出,在AI指令遵循模型中存在一个普遍现象,即在评估模型性能时,存在“长度偏见”(length bias),即人们倾向于偏好更长的响应。这导致训练算法倾向于生成更长的响应。
现有问题:尽管一些评估基准测试已经尝试通过引入长度惩罚来解决这种偏见,但这并没有从根本上解决问题。文章认为,许多查询中期望的响应长度是模糊的,这种模糊性使得评估变得困难,进而影响了使用这些评估信号的训练算法。
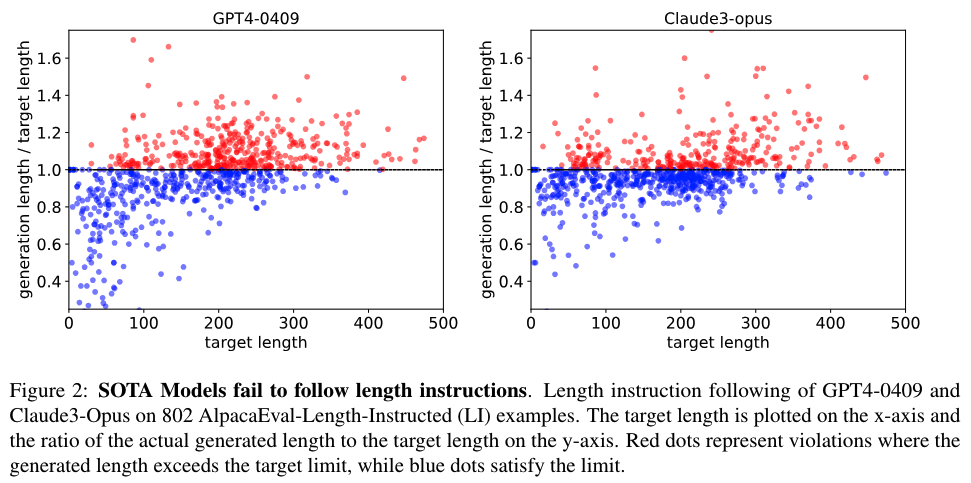

提出的解决方案:作者提出,在评估中应包括进一步消除歧义的指令,这些指令规定了期望响应的长度。例如,通过添加“答案应少于300个单词”的指令,可以明确期望的响应长度。
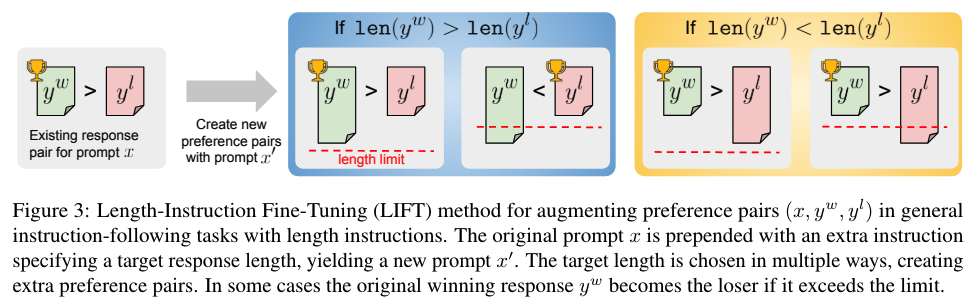
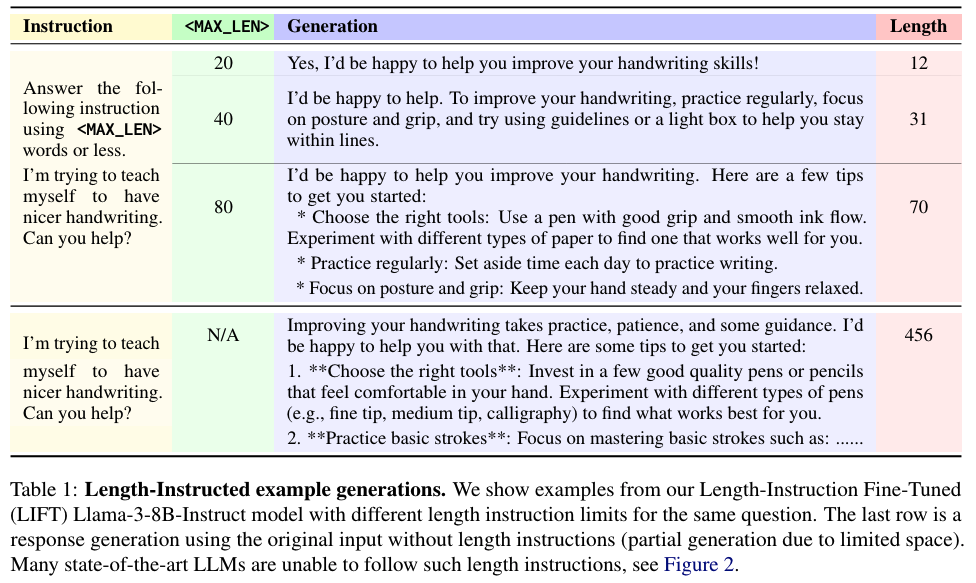
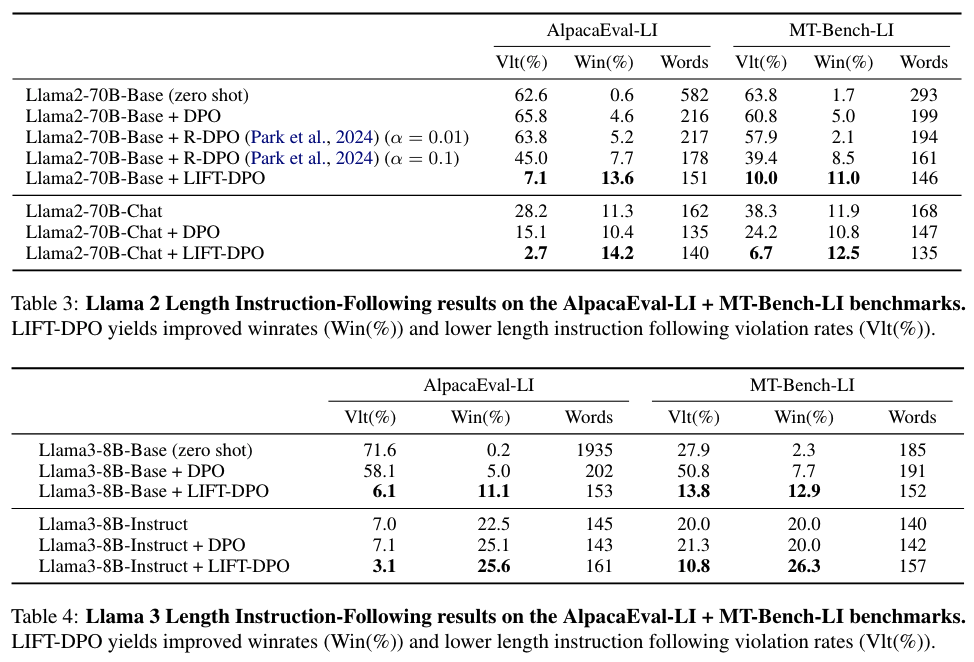
实验与方法:文章通过构建和评估模型在长度指导版本的AlpacaEval 2和MT-Bench上的表现,展示了现有最先进的指令遵循模型在遵循最大单词长度指令方面的不足。作者开发了一种方法,称为长度指令微调(Length-Instruction FineTuning,简称LIFT),通过在原始提示中插入长度指令来构建增强的训练数据。
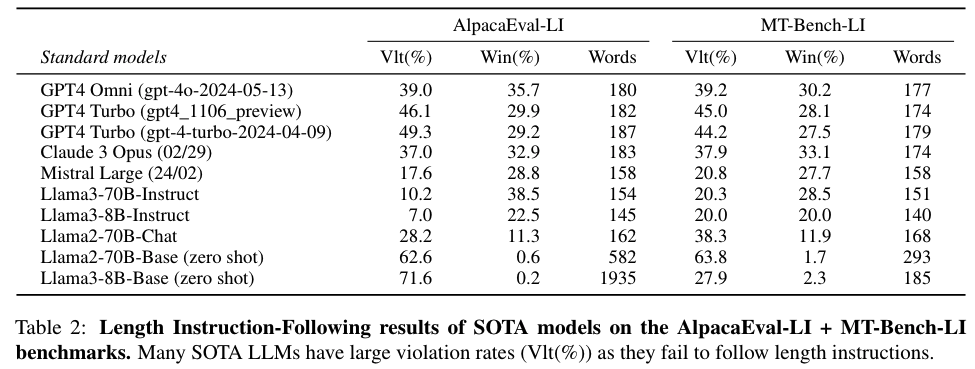
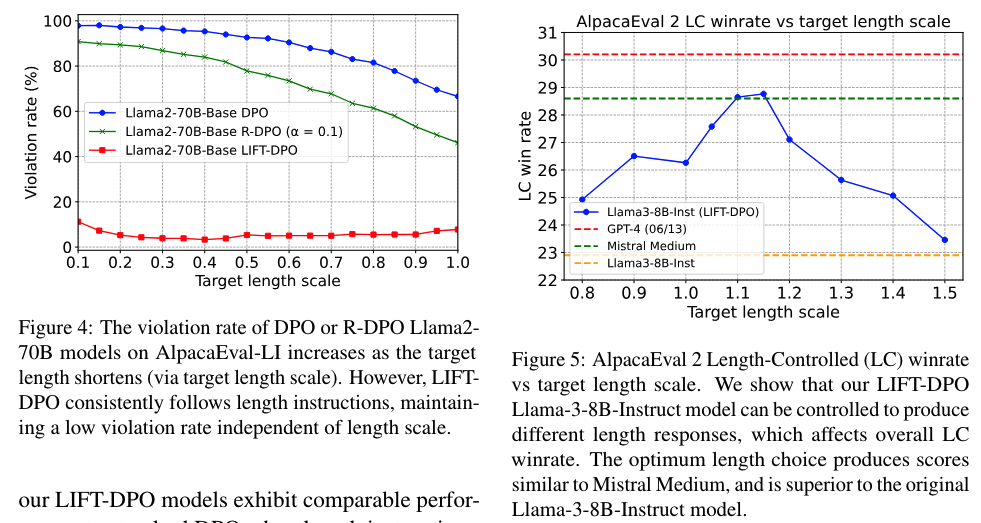
实验结果:使用LIFT方法训练的模型在长度受限的评估中表现更好,与现有的指令遵循模型相比,违反长度限制的情况更少,整体胜率更高。
相关工作:文章还讨论了与模型对齐的长度偏见相关的工作,以及考虑长度的学习方法,特别是在摘要任务中。
新基准测试:作者创建了两个新的基准测试,AlpacaEval-LI和MT-Bench-LI,用于评估模型遵循长度指令的能力。
结论与限制:文章总结了通过引入长度指令来解决一般指令遵循中的长度偏见问题,并指出LIFT-DPO模型在控制输出长度的同时保持了高响应质量。同时,作者也指出了研究的局限性,比如长度限制的设定方式和人类对更长更详细响应的自然偏好等。
文章最后提供了参考文献和附录,包含了一些技术细节和额外的实验结果。
本文由kimi+人工共同完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









