






主题
RNN卷土重来:基于门控记忆槽的线性注意力机制
时间
2024.7.28 10:30-11:30 周日
入群

内容
1. 背景
- 基于标准注意力机制的大语言模型
- 线性化方法
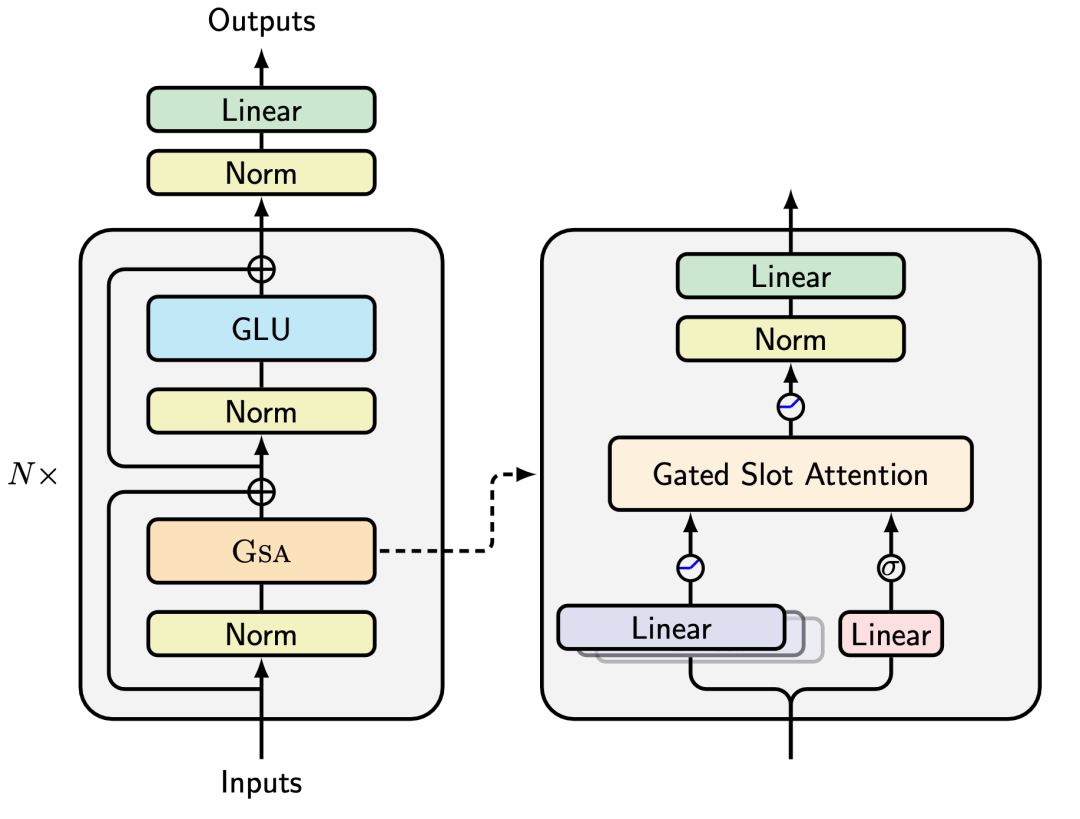
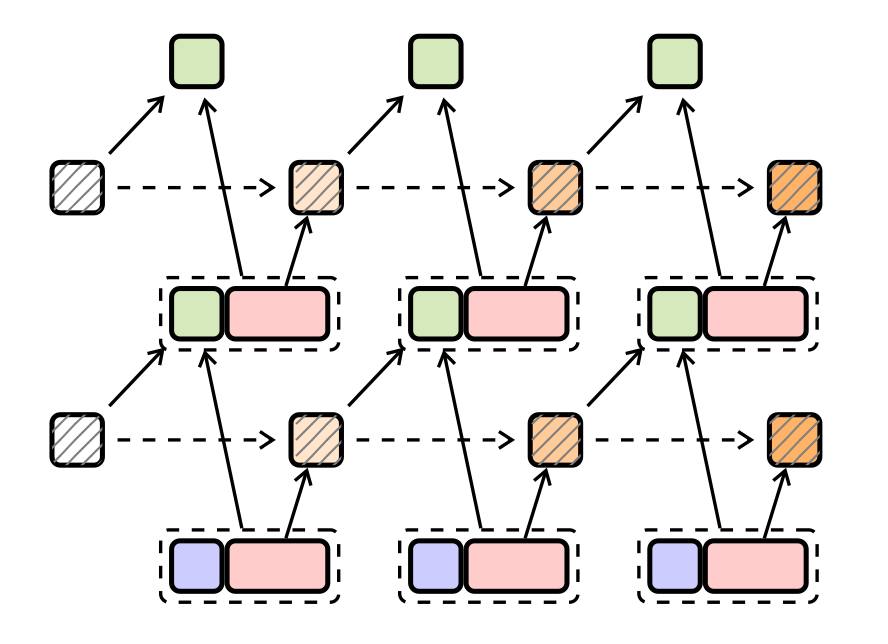
2. 门控记忆槽注意力机制
- KV memory视角下的attention及其线性化
- 数据依赖的门控机制
- 并行化方法
- 参数化
3. 实验
- 基准评测结果
- GSA的Recall能力和隐状态容量分析
- 继续训练的优势
4. FLA
5. 总结与展望
6. QA
引言
当前的大语言模型(LLM)在使用标准注意力机制时,面临着训练复杂度呈二次增长以及推理阶段管理键值(KV)缓存内存密集型的挑战。线性注意力作为一种有前景的替代方案,通过固定容量的隐藏状态取代了无界限的KV存储,从而缓解了这一问题。
然而,现有的线性注意力实现往往在性能上不及类似Llama架构(如Transformer++)的效率。
本次talk介绍了一种基于门控槽注意力(Gated Slot Attention,简称GSA)的方法,该方法融合了标准注意力的原理与数据依赖的门控线性注意力,实现了序列建模的线性化。通过更优的内存管理,采用GSA训练的LLM相较于以往的线性注意力设计应当展现出更好的性能。
更重要的是,GSA能够在现代硬件上实现高效并行化,这使得大规模实验成为可能。通过从头训练13亿和27亿参数的模型,GSA在一系列基准测试上表现出了很强的竞争力。此外,GSA与其他线性注意力变体相比,与现有的基于标准注意力的LLM有更好的兼容性。
嘉宾

张宇目前是苏州大学人工智能实验室的三年级博士生,指导老师是付国宏教授。在此之前,他于2021年在苏州大学获得了硕士学位。
他的主要研究方向主要集中于开发更高效的语言生成模型,特别是针对硬件优化、线性复杂度的序列建模方法。他致力于发掘并利用并行计算的潜力,以构建可扩展的次平方级模型。目前已在ACL/EMNLP等NLP会议上发表多篇论文,是句法分析SuPar和线性注意力FLA等库的主要贡献者和维护者。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









