







知乎:没有鱼鳔的鲨鱼
链接:https://zhuanlan.zhihu.com/p/696065154
本系列 blog 是有关大模型的置信度、不确定性估计及校准的学习笔记分享,这些研究对提高大模型的可靠性有重要意义,我会持续更新相关基础工作和最新研究,相关文献也整理在以下 GitHub 项目中,欢迎关注~
https://github.com/AmourWaltz/Reliable-LLM
I. 大模型的过度自信和幻觉问题
当今的大语言模型(LLMs)尽管在实际应用中取得不俗的表现,但很难保证其输出的可靠性(Reliability),由于预训练阶段模型在大规模语料通过最大似然概率的方式学习,网络的海量数据总是倾向让模型给出回复。大模型获取的知识一般在预训练(pretraining)阶段就已经确定并以参数化的形式储存,如果在指令微调(instruction-tuning)中使用模型没见过的知识样例,那必然会导致模型对于未知的问题也给出确定答复,即编造一个答案,这就是模型过度自信(over-confidence)导致的幻觉问题(hallucinations)。如果盲目轻信采用模型生成的答案,很可能会误导用户。因此评估模型生成回复的置信度(confidence),也就是对一个问题的不确定性(uncertainty),让用户明白在多大程度上可以采用模型的答案,非常有助于降低风险并使模型做出更好的决策,通过进一步校准(calibration)模型可以提高其可靠性。
II. 分类模型的置信度校准
置信度 v.s 不确定性 (Confidence v.s Uncertainty)
模型校准一直是传统机器学习关注的研究,传统机器学习大都关注分类或决策任务,因此我们会特别关注一个模型预测的置信度。首先对置信度和不确定性来简单做下区分,在大部分场景下置信度和不确定性都可以混合使用,来表示机器学习模型所做预测或决策的确定程度。机器学习中的不确定性又分为偶然不确定性(Aleatoric Uncertainty)和认知不确定性(Epistemic Uncertainty),前者捕捉了来自数据的不确定性,后者则考虑了模型中的不确定性,数据的不确定性很难直接度量,但是模型的不确定性则有多种方式获取;不确定性更多是度量针对某个固定输入 query 或 prompt,模型的“发散(dispersion)”程度;而置信度则可以看做是不确定性的直接观测结果,对于一个输入为 、标签为 、模型预测结果为 的分类任务,模型的预测置信度表示为 ,分类任务中常常把预测概率直接作为预测的置信度,理想情况下,置信度分数应该准确反映模型在实际场景中的真实准确率,也就是如果模型对于 的预测置信度为 0.9,那么预测结果 的真实概率也应该为 0.9,更一般地表示为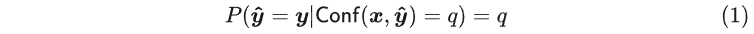
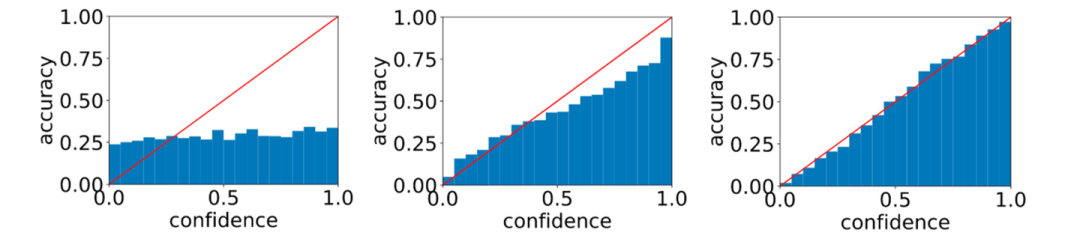
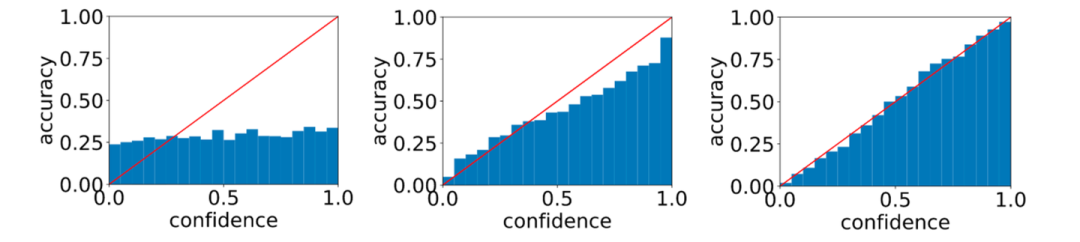
可靠性图表,随机猜测(左),过拟合(中),校准良好(右)
上面三张图叫可靠性图表(reliability diagram),横坐标是对预测结果的置信度,采用桶(bucket)的形式,每一个“桶”包含所有该置信度的样本簇,纵坐标为这批样本的准确率,从左到右依次为随机猜测、过拟合和良好校准。根据公式(1),理想情况在某个置信度 下的所有样本的实际准确率也应该等于 ,也就是蓝色桶的高度应该恰好等于红色对角线,所以最右边的图是校准的最好的。
II. 生成模型置信度估计
生成任务不确定性估计的困难
传统分类任务的不确定性或置信度度量比较简单,但是大模型的输出通常为序列,而所对应的下游任务更是种类繁多,这就给大模型不确定性度量带来一定困难,本文给出几种常见的大模型不确定性度量方法。
大模型生成任务的不确定性估计通常有以下两点困难:
传统分类任务的输出空间是有限的,一般为类别数 ,而生成任务输出空间为 ,其中 为序列长度,而又因为输出序列长度是可变的,因此生成任务的输出空间可以认为是无穷大。因此很多分类任务的不确定性估计和校准方法并不适用于生成任务。
分类任务的 SoftMax 输出概率往往可以直接反应对一个预测的置信度,但是生成任务的句子序列中每一个词元 token 的概率并不能反应置信度,因为生成任务我们更关注句子的含义,也就是语义。生成任务更关注如何捕捉准确的语义信息来进行不确定性建模。
下面给出几种大模型常见的不确定性估计方法,由于这块的研究仍面临挑战,因此列出的方法也都有对应的缺点。
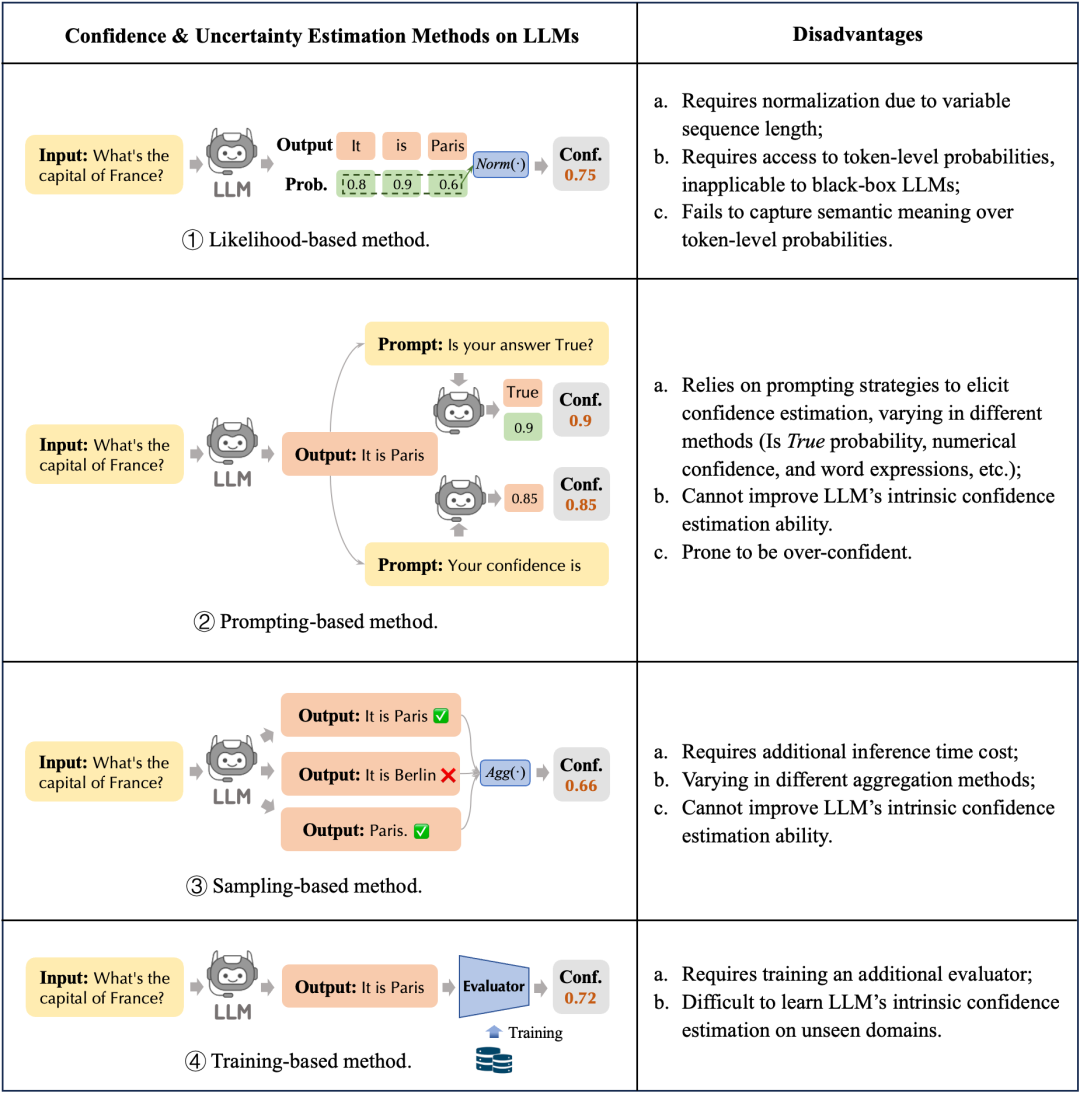
基于 Likelihoods 的置信度估计
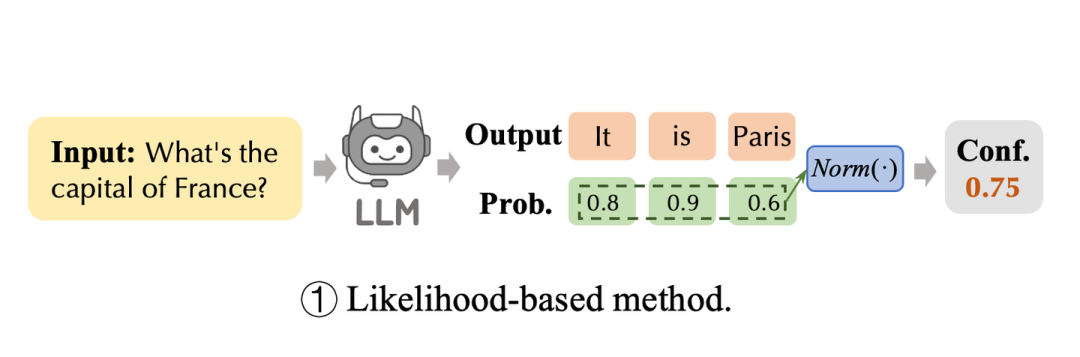 基于似然的置信度是通过计算在给定输入 下生成序列 的联合概率(joint log-likelihood probability)来估计的。由于序列越长其联合概率随长度呈指数级下降,我们通过将输出中条件标记概率的乘积归一化为序列长度来计算几何平均值,置信度可以表示为
基于似然的置信度是通过计算在给定输入 下生成序列 的联合概率(joint log-likelihood probability)来估计的。由于序列越长其联合概率随长度呈指数级下降,我们通过将输出中条件标记概率的乘积归一化为序列长度来计算几何平均值,置信度可以表示为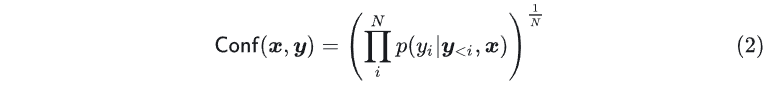 由于生成序列中一些常见词比如 the 的概率本身就很高,实际中更关心一些不常见词的概率,所以也可以直接去最小单词的概率作为预测置信度
由于生成序列中一些常见词比如 the 的概率本身就很高,实际中更关心一些不常见词的概率,所以也可以直接去最小单词的概率作为预测置信度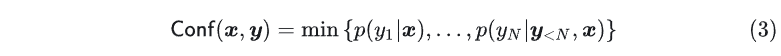 最后,我们也可以通过计算算术平均值来作为置信度
最后,我们也可以通过计算算术平均值来作为置信度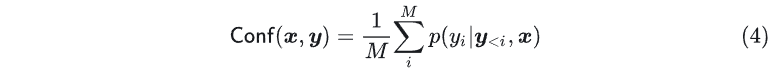 上面三种方法虽然一定程度上都能通过捕捉输出词元的概率来反应不确定性信息,但是正如一开始的分析,这些概率值反映的更多是采用最大似然概率训练后的结果,并不能反应准确真实的语义信息。并且这三种方法都要求访问词元的概率,而对于很多开源黑盒模型,我们无法直接访问每个词元token的概率,因此这些方法并不能广泛适用。
上面三种方法虽然一定程度上都能通过捕捉输出词元的概率来反应不确定性信息,但是正如一开始的分析,这些概率值反映的更多是采用最大似然概率训练后的结果,并不能反应准确真实的语义信息。并且这三种方法都要求访问词元的概率,而对于很多开源黑盒模型,我们无法直接访问每个词元token的概率,因此这些方法并不能广泛适用。
基于 Prompt 的置信度估计
基于 Prompt 的方法有两种,分别是基于 和语言置信度。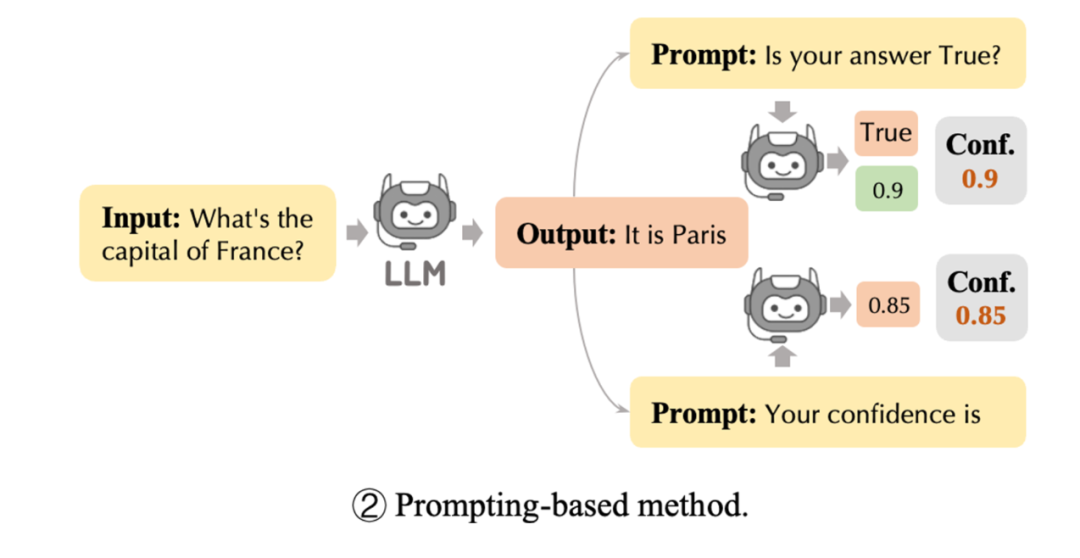 置信度分数是通过简单地询问模型本身其对于问题 回复 是否为真来实现的,即在首次生成答案后,再次询问模型“你认为你对问题 的回复 是正确(True)的吗”,然后获取模型分配的真实概率 ,这可以隐含获得模型自我反映的置信度。
置信度分数是通过简单地询问模型本身其对于问题 回复 是否为真来实现的,即在首次生成答案后,再次询问模型“你认为你对问题 的回复 是正确(True)的吗”,然后获取模型分配的真实概率 ,这可以隐含获得模型自我反映的置信度。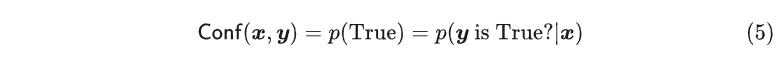 由于大模型具备良好的指令遵循能力,现在有很多研究直接让模型口语化的输出对预测的不确定性估计,即直接提问模型对于问题 回复的 的置信度是多少,要求模型返回一个 之间的小数,很多实验证明这种方法可以获得比基于似然概率更准确的置信估计。
由于大模型具备良好的指令遵循能力,现在有很多研究直接让模型口语化的输出对预测的不确定性估计,即直接提问模型对于问题 回复的 的置信度是多少,要求模型返回一个 之间的小数,很多实验证明这种方法可以获得比基于似然概率更准确的置信估计。
基于 Prompt 的方法除了引入额外的推理计算代价,对不同的 prompt 敏感程度也不同。而这些 prompt 作用和 CoT 一样,只是激发了模型表达准确置信度,对模型实际可靠性并无提升。
基于多次采样的不确定性估计
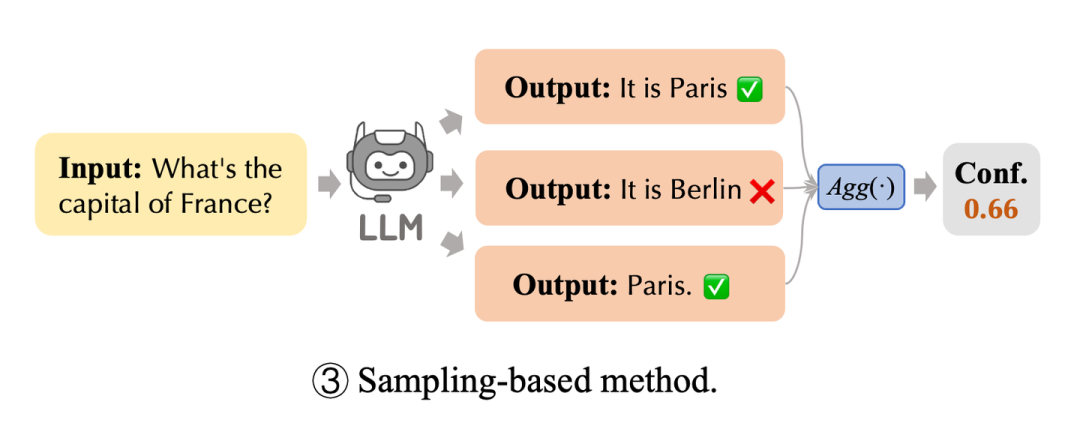 对于无法直接获得输出概率的商业黑盒模型,除了以上语言表达置信度的方法,我们也可以通过针对一个问题 通过调整 temperature 以及解码方法进行多次采样,如果采样三次其中有两次输出答案相同,我们可以认为置信度为 0.66。
对于无法直接获得输出概率的商业黑盒模型,除了以上语言表达置信度的方法,我们也可以通过针对一个问题 通过调整 temperature 以及解码方法进行多次采样,如果采样三次其中有两次输出答案相同,我们可以认为置信度为 0.66。
同样地,多次采样方法可能会引入更多的推理计算代价,并且也无法提高模型本身可靠性。
基于训练的置信度估计
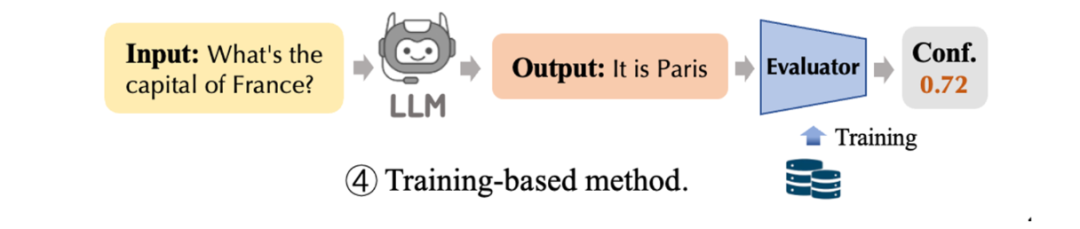 基于训练的方法就是引入一个数据集,利用监督微调的方式训练一个额外的判别器或让模型本身学习置信度分数表达,这种方法可以提高模型实际置信度的表达,如何构造可靠的训练集就称为研究重点,下一篇笔记将总结最近构造置信度数据集并进行监督微调来提高模型可靠性的几篇工作。
基于训练的方法就是引入一个数据集,利用监督微调的方式训练一个额外的判别器或让模型本身学习置信度分数表达,这种方法可以提高模型实际置信度的表达,如何构造可靠的训练集就称为研究重点,下一篇笔记将总结最近构造置信度数据集并进行监督微调来提高模型可靠性的几篇工作。
III. 大模型不确定性和校准评估指标
对大模型而言,不确定性度量应尽可能反映生成回复的可信程度,这意味着一条回复的不确定性越高,那么它越有可能是错误的。于是对于不确定性度量的评估,就转换为是否信任给定输入下模型的输出——即对某个问题的回答,这里引入 AUROC (Area Under Receiver Operating Characteristic),AUROC代表了在随机选择正确答案时,其具有更高的不确定性分数的可能性,与随机选择错误答案相比。较高的AUROC值更为理想,理想的AUROC评分为 1,而随机的不确定性估计将产生AUROC = 0.5。
关于校准,有很多测量方法可以显示模型的预测置信度与真实概率间的差异,这种差异成为校准误差。在可靠性图表中,我们将横坐标的置信度分数 分成 个等间距的桶 ,其中 包含预测置信度在区间 内的样本。最常使用的的预期校准误差 ECE(Expected Calibration Error)定义如下: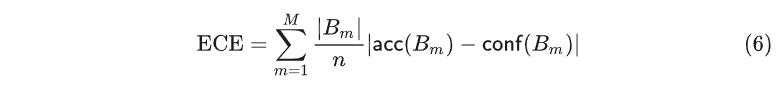 其中, 𝐵𝑚 的平均准确度和置信度定义如下:
其中, 𝐵𝑚 的平均准确度和置信度定义如下: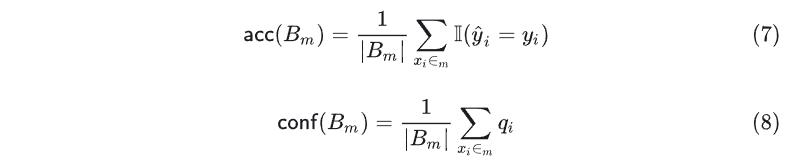 其中 分别为第 个样本、标签、预测结果和置信度。更直观的,ECE 其实就是可信图表中红色对角线与蓝桶之间的白色区域面积。可以看出,最右边良好校准的模型 ECE 几乎为 0。
其中 分别为第 个样本、标签、预测结果和置信度。更直观的,ECE 其实就是可信图表中红色对角线与蓝桶之间的白色区域面积。可以看出,最右边良好校准的模型 ECE 几乎为 0。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









