






来自:CodeFuse
多任务学习(MTL)通过给单个模型提供更优的性能和跨任务的泛化能力,从而促进了大语言模型(LLMs)的微调。这是一种资源高效的替代方案,避免了针对每个任务单独训练一个模型而带来的资源浪费。然而,现有的 MTL 策略在 LLMs 的微调中仍有不足之处,往往要么计算资源要求高,要么无法保证多任务的同时收敛。
我们提出了一种满足了以上两种需求的新的 MTL 方法——CoBa,旨在以最小的计算开销有效控制多任务收敛的平衡。CoBa 利用相对收敛分数(RCS)、绝对收敛分数(ACS)和发散因子(DF),在训练过程中动态地调整任务权重,确保所有任务的验证集损失以均匀的速度朝向收敛推进,同时缓解了个别任务提前发散的问题。本文在四个不同的多任务数据集上进行实验,结果表明,CoBa 不仅促进了任务收敛的平衡,而且与最佳基线方法相比,还使 LLMs 的性能至多提升了 13%。
TLDR
我们提出了一种既能保持 LLMs 训练时的易用性,又能以最小的计算开销有效实现任务收敛均衡的 MTL 算法。
简介
本文源于蚂蚁集团自研项目,目前已被 EMNLP 2024 主会议接受。EMNLP(Conference on Empirical Methods in Natural Language Processing)会议是自然语言处理领域最具影响力的国际会议之一。
arXiv:https://arxiv.org/abs/2410.06741
github:https://github.com/codefuse-ai/MFTCoder

近年来,大语言模型(LLMs)因其卓越的性能已然跃升为学术界和工业界研究的焦点。这些模型通过预训练获取大量通用知识,使其能广泛适用于各种下游任务。随后的微调阶段会根据特定任务或场景,对模型进行更细致的调整。然而,微调需要针对不同任务单独训练,这会让生产环境中的部署环节变得复杂。随着任务数量的增加,庞大的模型体积也带来巨大资源消耗的问题,这使得为每个任务单独部署模型的需求变得更加棘手。
为解决这些挑战,多任务学习(MTL)应运而生[1,2]。这种方法可以同时训练多个任务,利用单个模型支持多种任务,从而显著节省计算及存储资源。此外,MTL 不仅有助于提高相关任务性能,还有行成泛化能力适应未见过的任务。LLMs 庞大的参数空间为其奠定了良好的适应性,使能够同时承担多项任务。这在 OpenAI 的 GPT-3.5/4 中得到了充分体现[3]。
要在 LLMs 上实现有效的 MTL,必须同时满足两个关键标准:一是应尽量减少额外的计算成本,二是保证所有任务能够同时收敛,并灵活优化至共享的最优保存点。
表1:现有 MTL 方法的时间复杂度对比,F 和 B 分别表示一个批数据前向和后向传播的计算开销,K 是任务个数,是模型参数量,是常量,其中,*表示权重是基于验证损失计算得来。
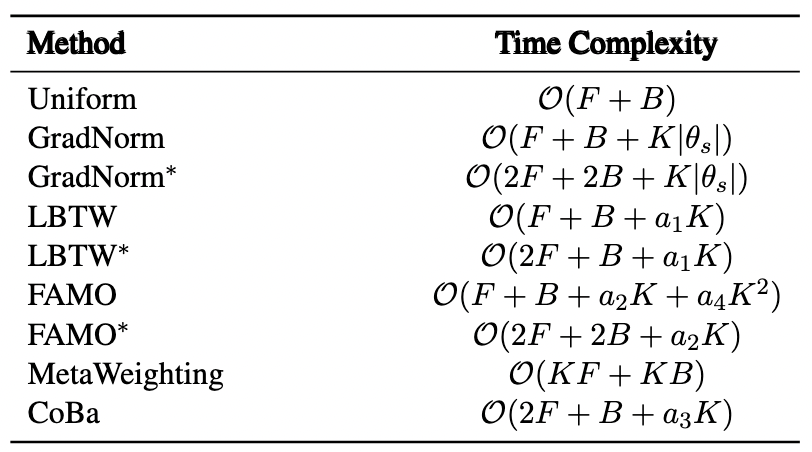
然而当前的 MTL 方法未能同时满足这两个要求。传统的 MTL 方法,如基于损失平衡和梯度操控的方法[4,5,6,7,8],在小模型和简单的分类任务上效果显著,但在处理 LLMs 时,由于计算成本和框架整合复杂性,这些方法很难适用。如 GradNorm[5]、FAMO[6] 和 MetaWeighting[7] 等方法的计算成本与任务数量息息相关(如表 1 所示),任务增加时,计算成本显著上升。另外,像 Muppet 和 ExT5 这样的 NLP 模型则采用了来自多个任务的简单数据混合策略,但未能有效解决任务收敛不均衡的问题,可能导致某些任务仍在收敛,而其他任务却开始发散,从而严重影响模型整体效果。
针对这一问题,我们提出了一种新型 MTL 方法 CoBa(COnvergence BAlancer)。该方法旨在以最小的计算开销有效实现各任务的收敛平衡,同时保持在 LLMs 训练中的易用性。其核心策略是根据验证数据集中的收敛趋势动态调整每个任务的训练损失权重。支撑 CoBa 方法的两个关键准则是:
当所有任务的验证损失持续下降时,该方法降低收敛速度更快任务(验证损失下降斜率更大)的权重,增加收敛速度较慢任务的权重(验证损失下降斜率较小)。
对于即将要发散的任务——这可能提示着该任务即将过拟合——其权重将被减少,而对于仍在稳定收敛的任务,其权重将被增加。
为了实现这些目标,我们引入了相对收敛分数(RCS)以满足第一个标准,引入绝对收敛分数(ACS)以满足第二个标准。然后应用一个收敛因子(DF)来确定哪个分数在最终权重分配中占主导地位。值得注意的是,利用验证损失的斜率通过归一化和 softmax 函数,RCS、ACS 和 DF 不仅都能进行高效计算,还能轻松与主流的并行训练架构兼容。综上所述,我们研究的主要贡献包括:
我们提出了 CoBa,这一创新策略旨在实现各任务之间的平衡收敛。CoBa 在应用于 LLMs 时简单易行,弥合了先进 MTL 要求与实用性之间的差距。
我们提出了两个新的度量标准——相对收敛分数RCS和绝对收敛分数 ACS,以及发散因子 DF。前两个标准分别为上述两个准则提供支持,而 DF 则确定哪个标准主要影响最终的权重分配。
我们通过大量实验验证了 CoBa 的有效性和高效性,结果显示 CoBa 不仅能够实现任务之间的平衡收敛,还在与表现最佳基线方法的比较中实现了至多 13% 的相对性能提升。
算法
假设模型参数量为,任务数量为,我们定义任务在第个迭代中的损失函数为,训练损失的权重为,那么 MTL 优化的整体训练损失可以构造为:
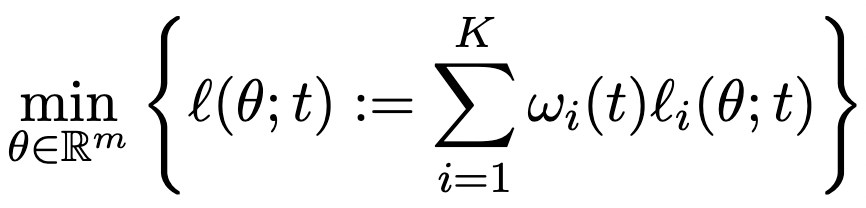
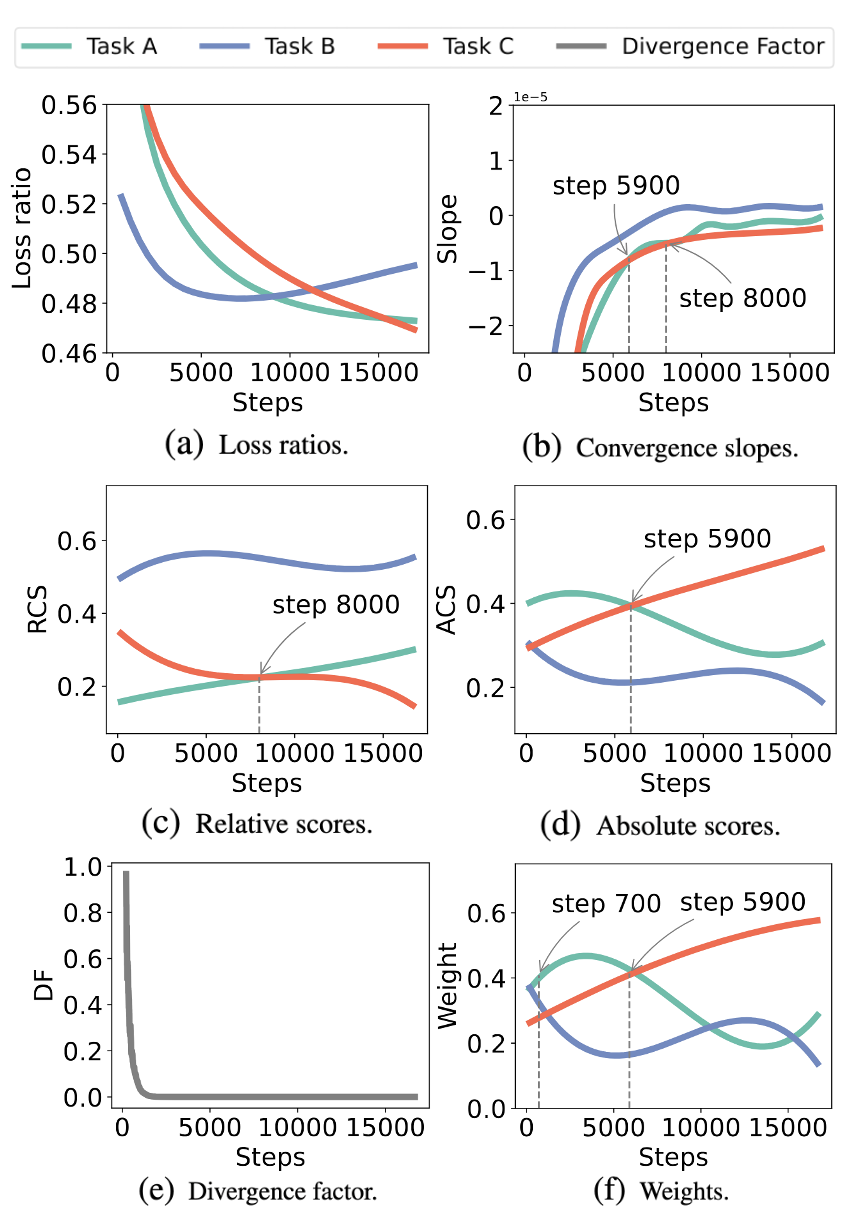
图1:CoBa 在真实训练场景下的任务权重计算过程
当权重时可以满足数据均衡,但可能会导致各任务的收敛速度不一致(如图 1(a) 所示),难以找到最优保存点。我们的目标是坚持上文提到的两个关键准则,通过调整来协调各任务的收敛速度,并优先考虑泛化能力,因此权重是由验证损失推衍得到而并非训练损失。
我们提出相对收敛分数(RCS)和绝对收敛分数(ACS),RCS 评估任务之间的相对收敛速度,而 ACS 则衡量每个任务当前的收敛速率与其历史速率的对比。为降低计算需求,这些分数是基于验证损失的斜率得出的,而不是梯度。我们还引入一个发散因子(DF),确保在所有任务都在收敛时,RCS 对权重的影响占主导地位,而当某一特定任务开始发散时,ACS 将起主导地位。
收敛斜率
不同任务的收敛速度可以通过观察验证损失曲线的斜率来直观地衡量。在图 1(a)展示的某种情况中,绿色曲线任务 B 在 5900 步前的收敛速度都快于红色曲线任务 C。如图 1(b) 所示,这一现象体现在了任务B的曲线斜率更陡,从而表示着任务B的收敛斜率绝对值高于任务 C。
我们在选定的迭代范围内拟合一个由定义的线性模型,其中的就是该段迭代内的收敛斜率的估计。
为应对初始收敛斜率的不准确性,我们的方法引入了 warm-up 参数。warm-up 期间各任务权重被统一设置为以确保平衡的起点。warm-up 期结束后,将根据滑动窗口内的收敛斜率更新权重。
相对收敛分数(RCS)
RCS 的目标是根据任务的收敛速度动态分配权重,即对收敛较快的任务分配较小的权重,对收敛较慢的任务分配较大的权重:
其中,表示对任务的维度进行 softmax 操作。首先归一化收敛斜率,即
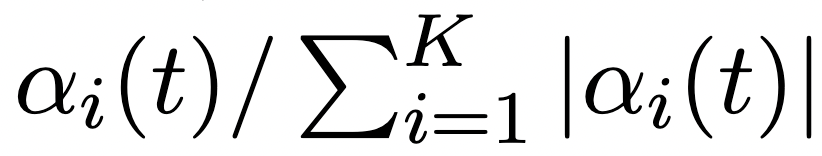
避免受到任务损失本身尺度的影响。考虑到当增加时,该归一化值趋于零,我们通过乘以来进行补偿。最后采用 softmax 计算出各个任务的 RCS 值。
在实际训练场景中,如图 1(a)所示,可以观察到任务 B(蓝色曲线)的收敛速度最慢,其 RCS 值是最高的(图1(c))。此外,任务C(红色曲线)在第 8000 步前的收敛速度慢于任务 A(绿色曲线),任务 C 的 RCS 高于任务 A。
绝对收敛分数(ACS)
仅凭 RCS 无法同时满足前文提到的两个多任务学习的需求,因为任务B虽然已经开始发散,但仍然获得了最高的 RCS(如图1(a)和1(c)所示)这可能使整体模型性能下降。因此 ACS 是必要的,通过为即将发散任务分配较小的权重,而对仍在收敛的任务赋予更大的权重,降低此类风险。ACS 对数学表达式为:
ACS 的计算方式与 RCS 不同,先沿着迭代维度进行归一化, 随后才在任务维度上进行 softmax 操作,且在归一化过程中仅考虑任务自身的历史表现。此外,ACS 式子中的反向归一化能让持续收敛的任务获得一个比开始发散任务更高的值。最后在任务间应用 softmax 分配 ACS 权重,实现增强收敛任务和抑制发散任务效果。
如图 1(a),1(b) 和 1(d) 所示,任务 B 由于最早开始发散而获得最小的 ACS。此外,由于任务 A 和任务 C 在 5900 步前后的收敛斜率相对大小发生变化,其 ACS 的相对大小也发生了转变。
发散因子(DF)和最终权重
在训练初期,任务通常表现为收敛模式,此时 RCS 应在权重分配占主导。随着训练进行,部分任务可能发散,此时 ACS 应优先影响权重分配。为实现从 RCS 主导到 ACS 主导的无缝过渡,我们引入发散因子(DF)来监控发散趋势。则最终的权重向量可以表示为:
提取每次迭代时所有任务中(考虑符号后)的最大收敛斜率,再通过以下公式进行量化:
在 softmax 函数中,我们将分子乘以当前步数,以防止随着增加而急剧下降,温度参数确保了 softmax 输出分量的区分度。
CoBa 与现有方法的差别
当前的收敛平衡方法主要通过减缓快任务和加速慢任务来实现,我们提出的 RCS 同样有效地实现了这一目标。然而,当某些任务开始发散时,这种方式会产生反作用,影响收敛平衡。为此,CoBa 引入了 ACS 和 DF,有助于抑制某些任务过早的发散趋势,从而确保多任务训练的整体稳定性。
实验
我们在四个不同数据集上评估了 CoBa 的表现:代码补全(CC)数据集,涵盖五种编程语言;代码相关任务(CRT)数据集[9],包含五个独特的编程任务;XTREME-UP 数据集[10],包含九种自然语言中的问答;以及多领域问答数据集,包含编码、数学和自然语言领域的问答数据。
我们将 CoBa 与八个最先进的基准模型(SOTA)进行对比:单任务学习(STL),Uniform[9],GradNorm[5],LBTW[8] 和 FAMO[6]。值得注意的是,后三种方法最初是基于训练损失设计的。为了提高泛化能力,我们已将这些方法调整为关注验证损失,分别记作 LBTW、GradNorm 和 FAMO*。
实验结果
CC 数据集上的结果
表2:Phi-1.5-1.3B 模型在 CC 数据集上的实验结果
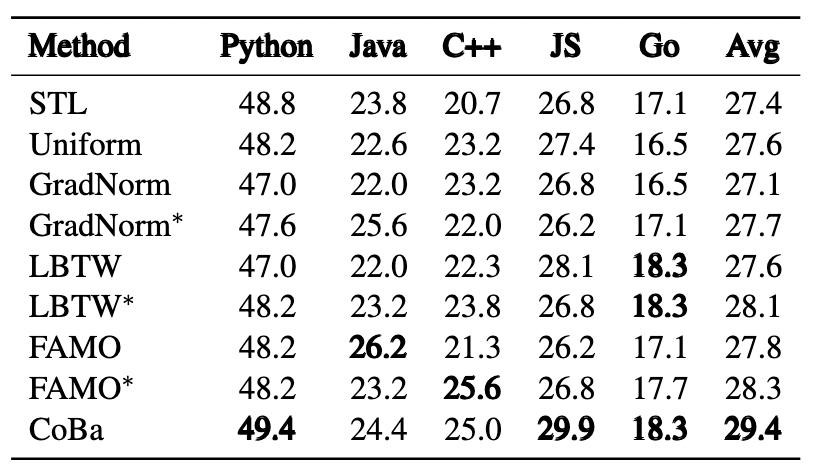
表3:CodeLlama-13B-Python 模型在 CC 数据集上的实验结果
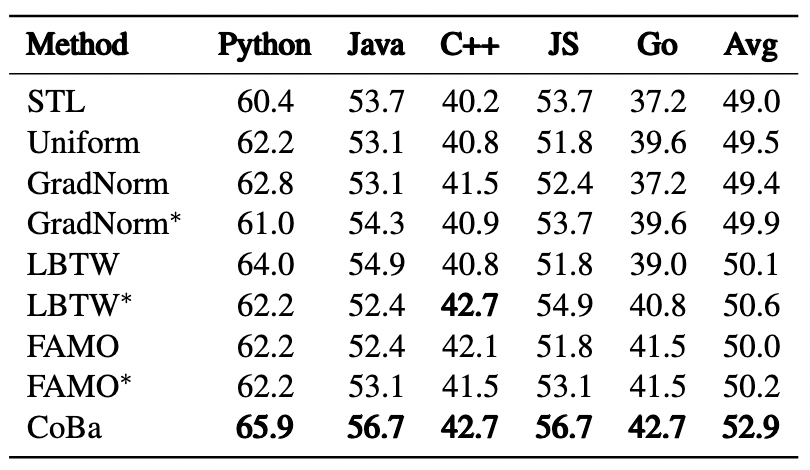
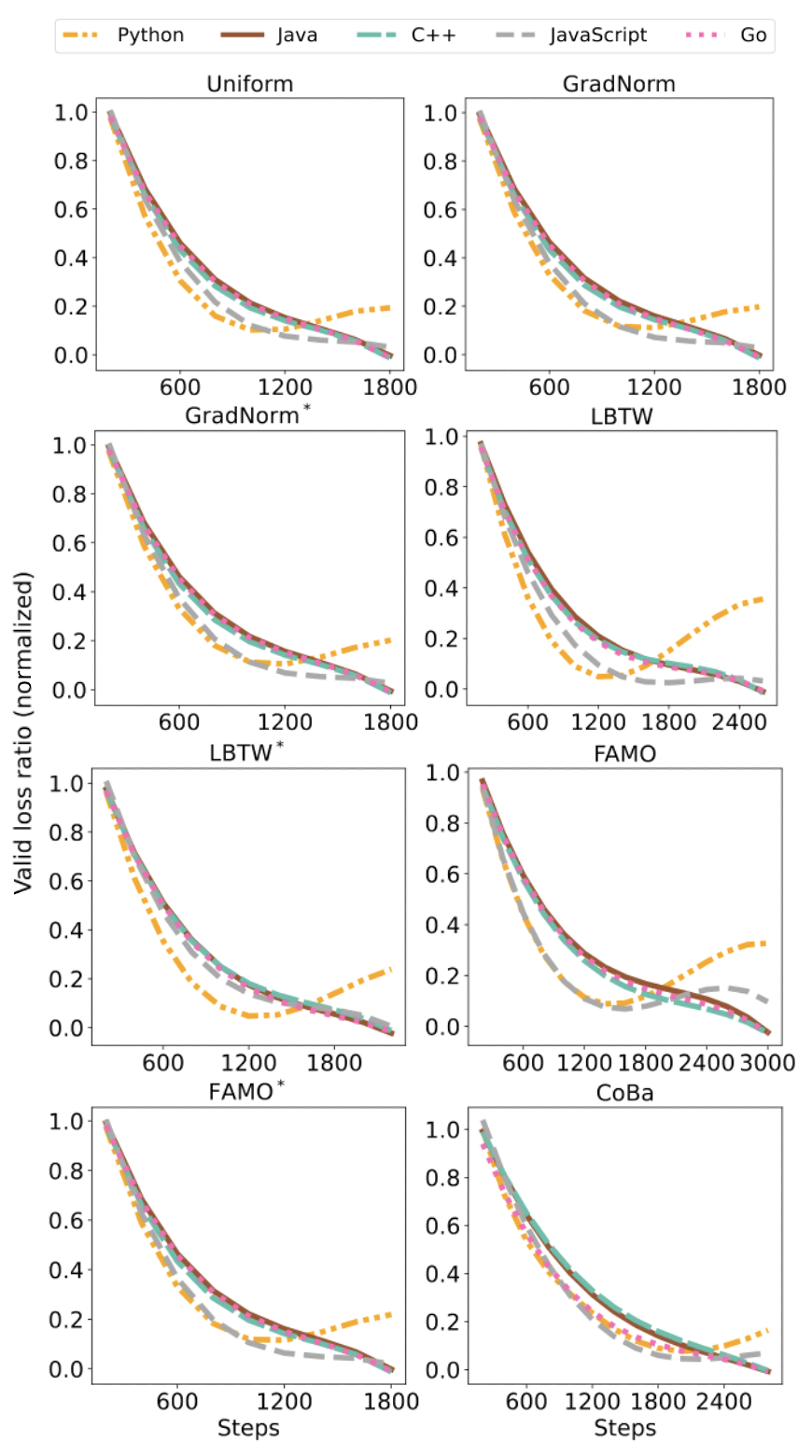
图4:Phi-1.5-1.3B 模型的 CC 实验中 5 种语言的归一化验证损失收敛情况对比
表 2 和图 4 展示了所有方法在 CC 数据集上的表现。CoBa 在五种编程语言的 Pass@1 指标上表现优于基线方法,平均得分至少提高 4%。此外,将 FAMO、LBTW 和 GradNorm 适配于验证损失(即 FAMO、LBTW 和 GradNorm)能有效提升性能,这一提升强调了根据验证损失来平衡收敛速度从而增强泛化能力的重要性。虽然 FAMO 的表现接近 CoBa,但在 Python 补全任务中存在潜在的发散趋势(图 4),影响了整体效果。相较之下,CoBa 通过利用 ACS 和 DF,有效地缓解了该问题。尽管 GradNorm 旨在以相同速度学习所有任务,但由于其采用相同且较小的学习率更新权重和模型参数,因此其性能仍落后于 CoBa、FAMO 和 LBTW 等方法。此策略在 LLMs 训练场景下表现不佳,导致 GradNorm 调整的权重几乎与初始的均匀权重相同,未能有效响应学习进展。
🔍CRT 数据集上的结果
表4:CRT 数据集上 Code Completion 任务的实验结果
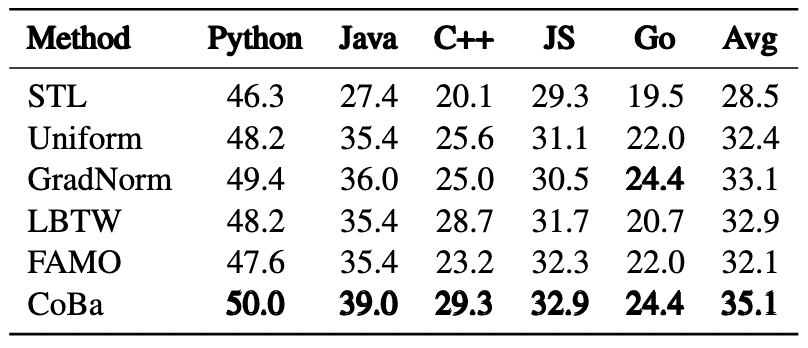
表5:CRT 数据集上 Unit Test 生成任务的实验结果
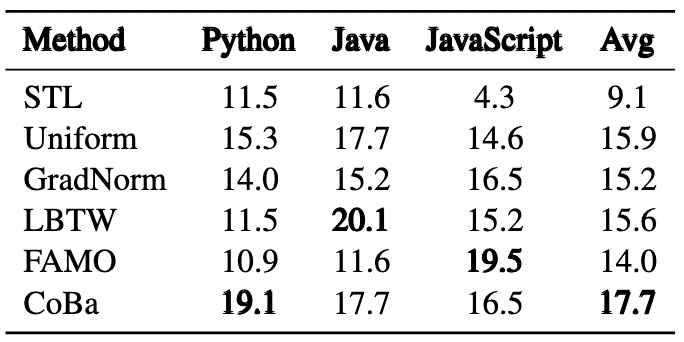
表6:CRT 数据集上 Code Translation 任务的实验结果
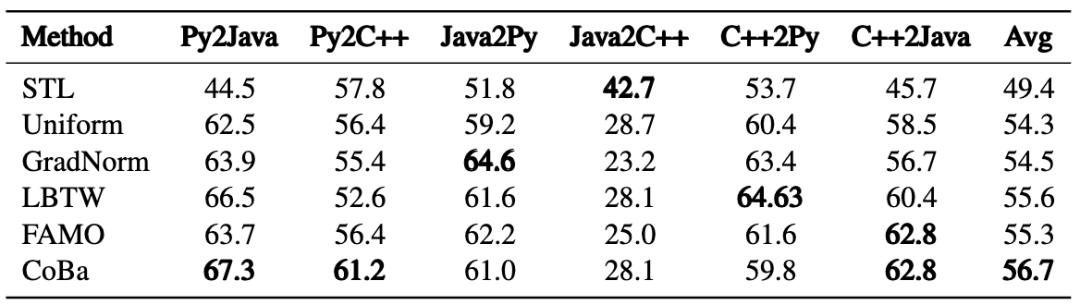
表7:CRT 数据集上 Code Comment 任务的实验结果
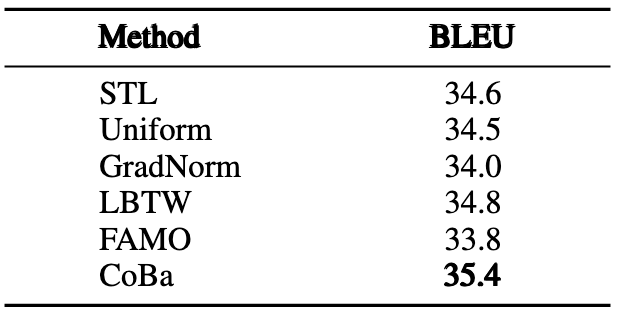
表8:CRT 数据集上 Text2Code 任务的实验结果

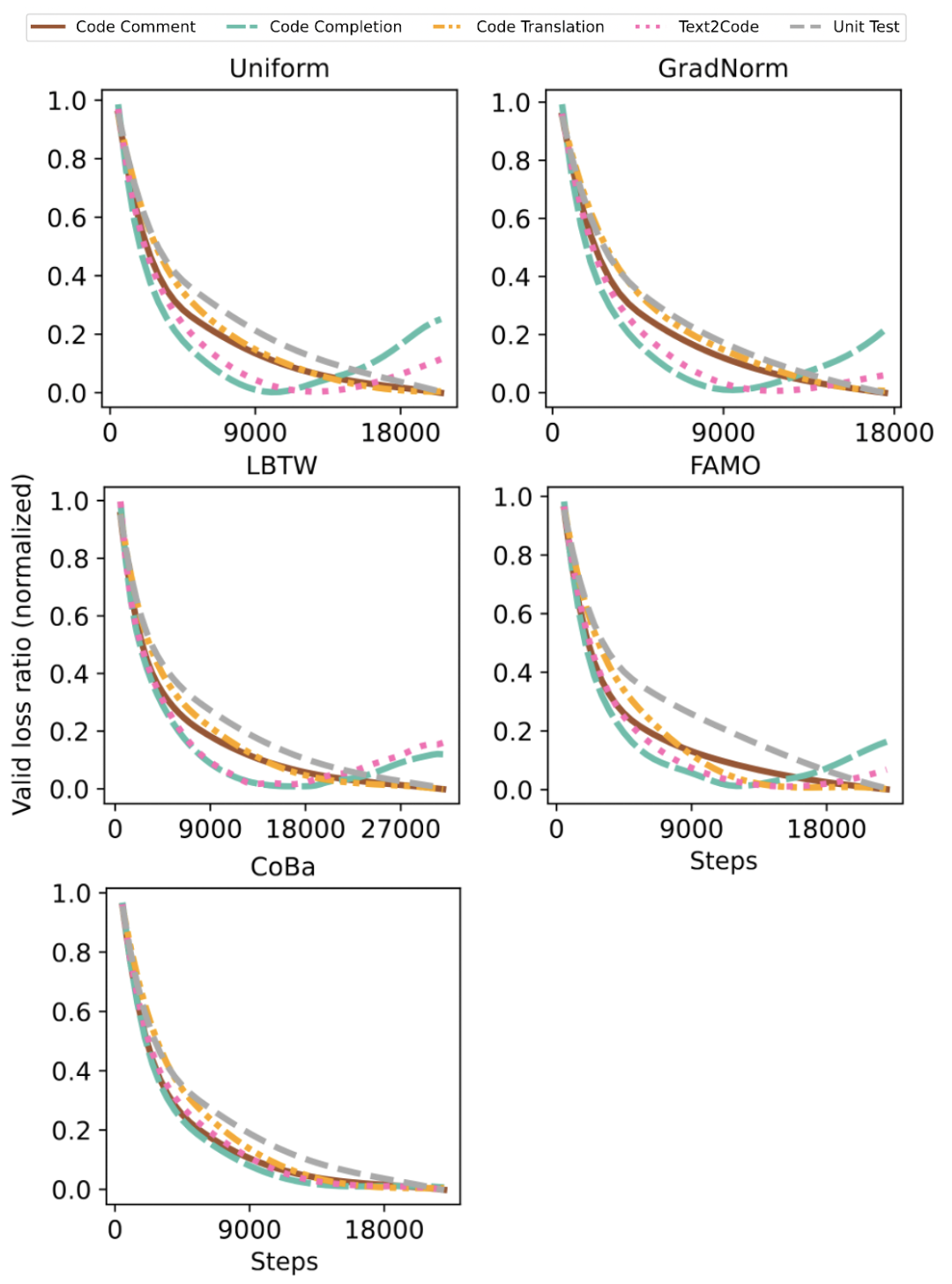
图5:CRT 实验中 5 种任务的归一化验证损失收敛情况对比
我们进一步探讨了所有方法在 CRT 数据集上的表现,这里的任务是按具体的代码需求划分的。实验结果表明,CoBa 在几乎全部任务中均超越了所有 SOTA 方法,唯独在 Text2Code 任务中表现稍逊。特别是在代码补全和单元测试生成任务中,CoBa 表现突出,分别实现了至少 6% 和 13% 的相对平均 Pass@1 提升。此外,图 5 显示 CoBa 不仅避免了在代码补全和 Text2Code 任务较早发散,还加快了其他任务的收敛,验证了了 CoBa 在实现收敛平衡和增强多任务学习能力方面的有效性。相反,GradNorm、LBTW 和 FAMO,在不同任务中的表现较不稳定,未能有效防止代码补全和 Text2Code 任务提前发散,凸显出了这些方法潜在的局限性。
🔍XTREME-UP 数据集上的结果
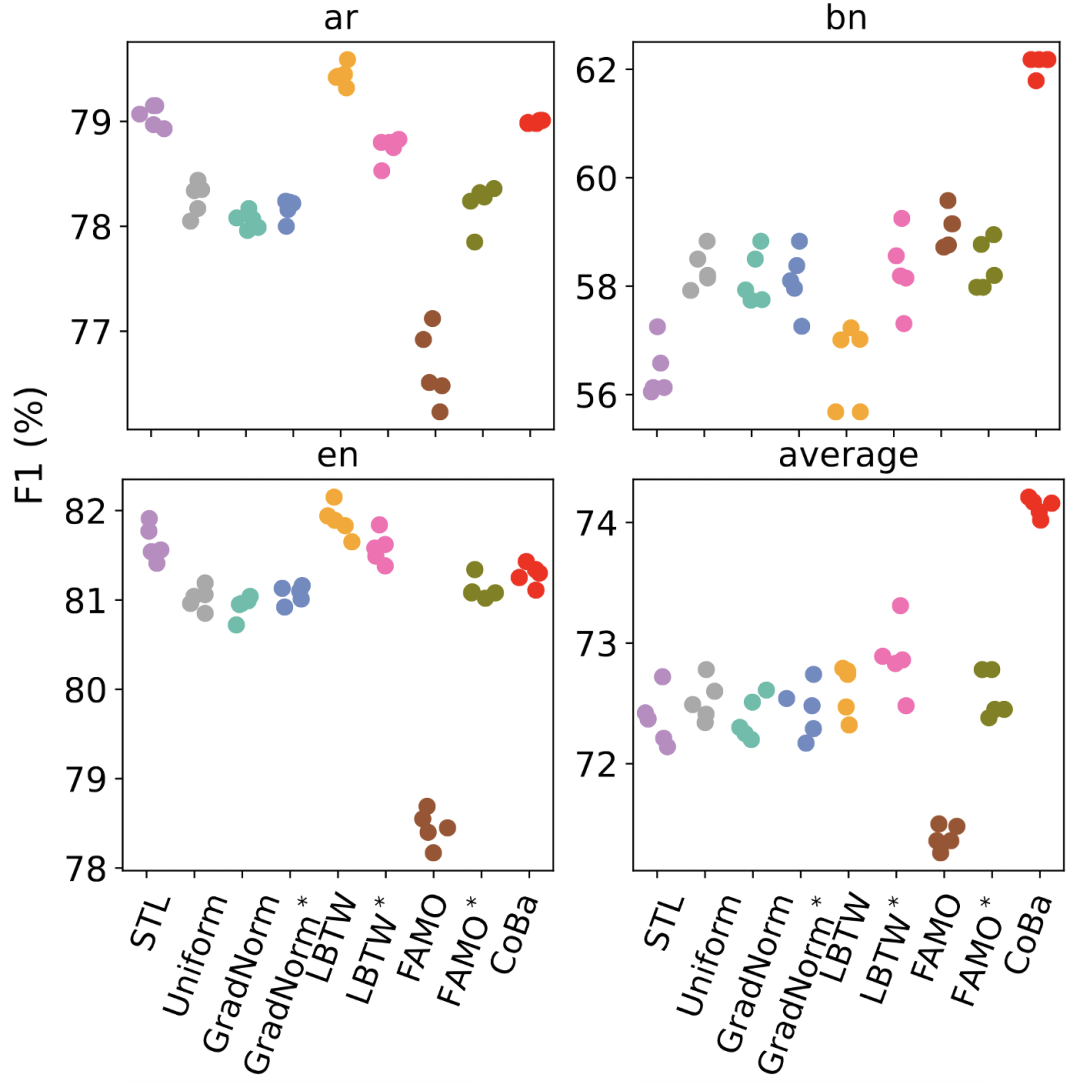
图6:XTREME-UP 数据集的 3 任务设定实验结果
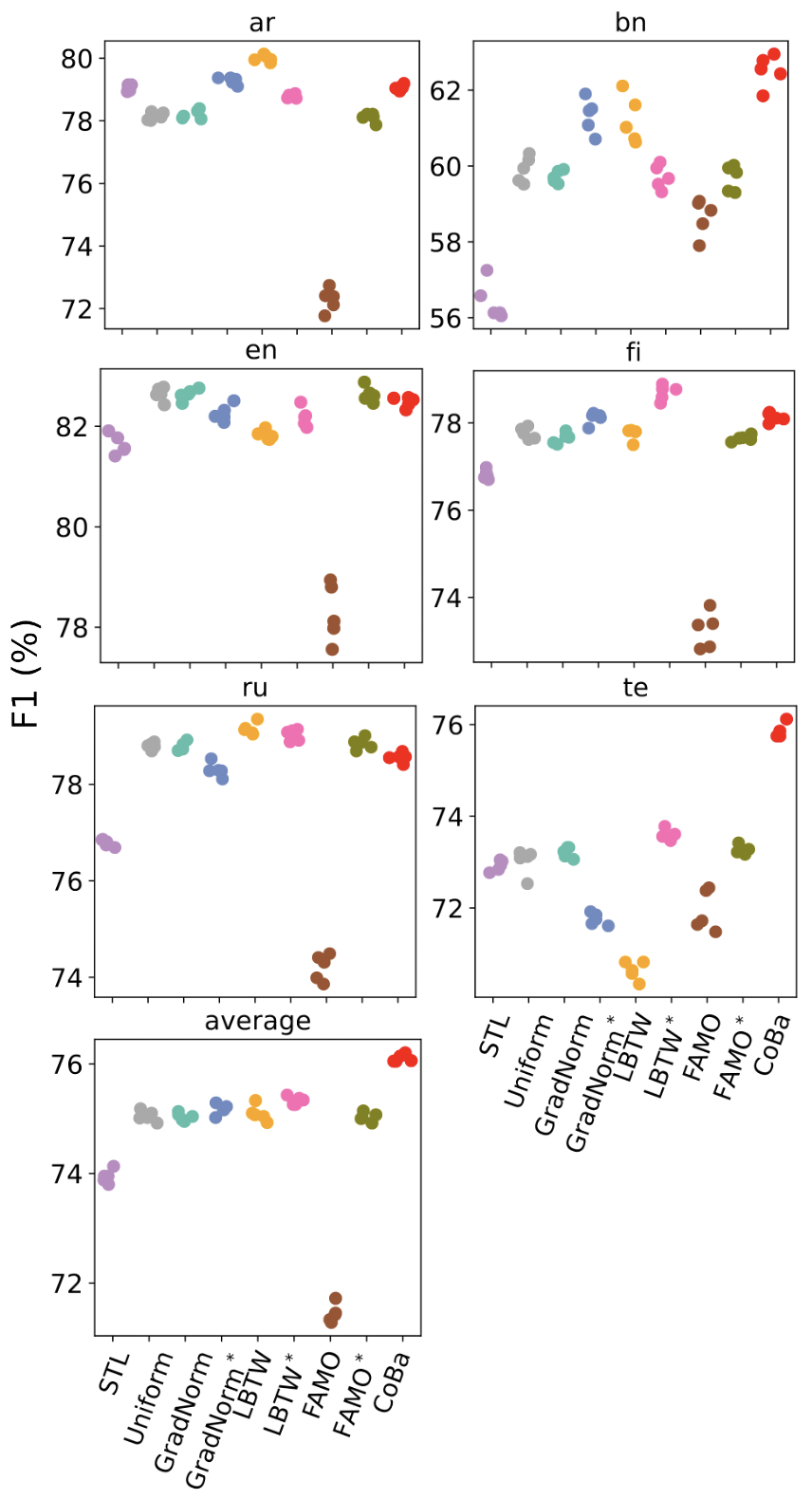
图7:XTREME-UP 数据集的 6 任务设定实验结果
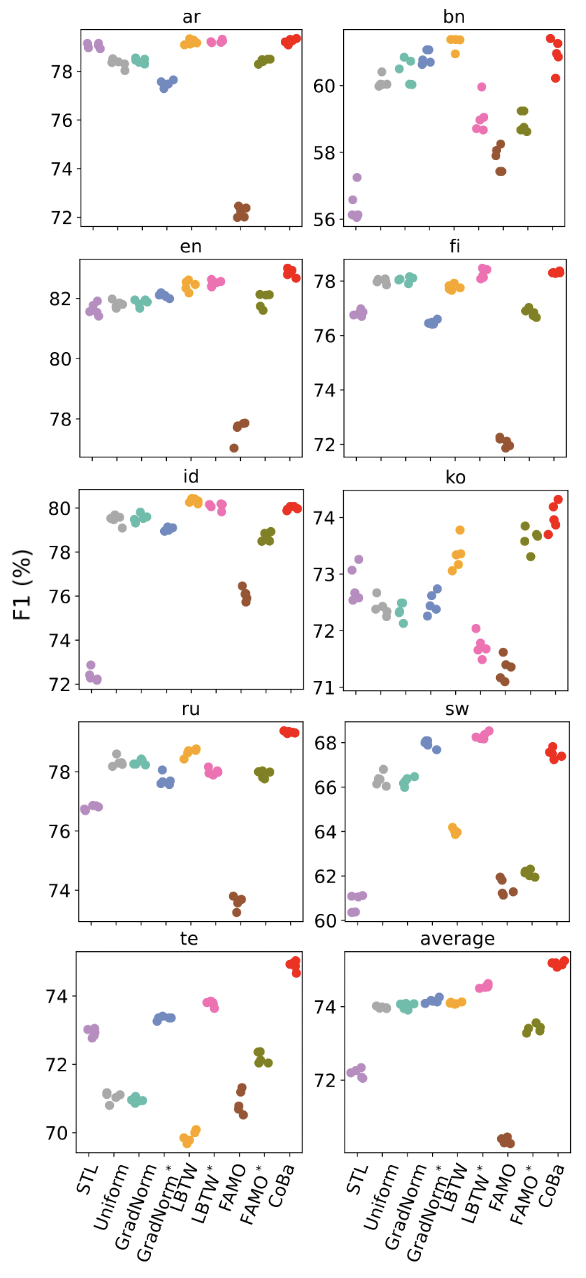
图8:XTREME-UP 数据集的 9 任务设定实验结果
我们进行了三组实验,任务数量分别为 3,6 和 9,混合高低资源语言。每组进行五次试验,以评估 CoBa 对于不同任务数量的适应能力,以及其对低资源语言的泛化能力。实验结果显示,CoBa 在所有条件下的平均的分数均明显优于所有基线方法,且在任务数量变化时保持鲁棒性。在低资源的孟加拉语(bn)和泰卢固语(te)任务中,CoBa的分数比 STL 提高了 3% 至 5%,高资源语言中,CoBa 的表现与 STL 持平或更好,这表明平衡收敛能够促进相关任务间的协同增益。
总结
我们提出了一种新颖的多任务学习方法 CoBa,旨在为大语言模型(LLMs)实现同时满足多任务收敛平衡和低计算复杂度的微调训练。我们采用四个真实世界的数据集进行了大量实验,验证了 CoBa 的有效性和高效性。
参考文献
[1] Simon Vandenhende, Stamatios Georgoulis, Wouter Van Gansbeke, Marc Proesmans, Dengxin Dai, and Luc Van Gool. 2021. Multi-task learning for dense prediction tasks: A survey. IEEE transactions on pattern analysis and machine intelligence, 44(7):3614–3633.
[2] Zhihan Zhang, Wenhao Yu, Mengxia Yu, Zhichun Guo, and Meng Jiang. 2023. A survey of multi-task learning in natural language processing: Regarding task relatedness and training methods. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 943–956.
[3] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
[4] Alex Kendall, Yarin Gal, and Roberto Cipolla. 2018. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7482–7491.
[5] Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. 2018. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In International conference on machine learning, pages 794–803. PMLR.
[6] Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. 2024b. Famo: Fast adaptive multitask optimization. Advances in Neural Information Processing Systems, 36.
[7] Yuren Mao, Zekai Wang, Weiwei Liu, Xuemin Lin, and Pengtao Xie. 2022. Metaweighting: Learning to weight tasks in multi-task learning. In Findings of the Association for Computational Linguistics: ACL 2022, pages 3436–3448.
[8] Shengchao Liu, Yingyu Liang, and Anthony Gitter. 2019a. Loss-balanced task weighting to reduce negative transfer in multi-task learning. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 9977–9978.
[9] Bingchang Liu, Chaoyu Chen, Cong Liao, Zi Gong, Huan Wang, Zhichao Lei, Ming Liang, Dajun Chen, Min Shen, Hailian Zhou, et al. 2024a. Mftcoder: Boosting code llms with multitask fine-tuning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
[10] Sebastian Ruder, Jonathan H Clark, Alexander Gutkin, Mihir Kale, Min Ma, Massimo Nicosia, Shruti Rijhwani, Parker Riley, Jean Michel Amath Sarr, Xinyi Wang, et al. 2023. Xtreme-up: A user-centric scarce-data benchmark for under-represented languages. In The 2023 Conference on Empirical Methods in Natural Language Processing.
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









