






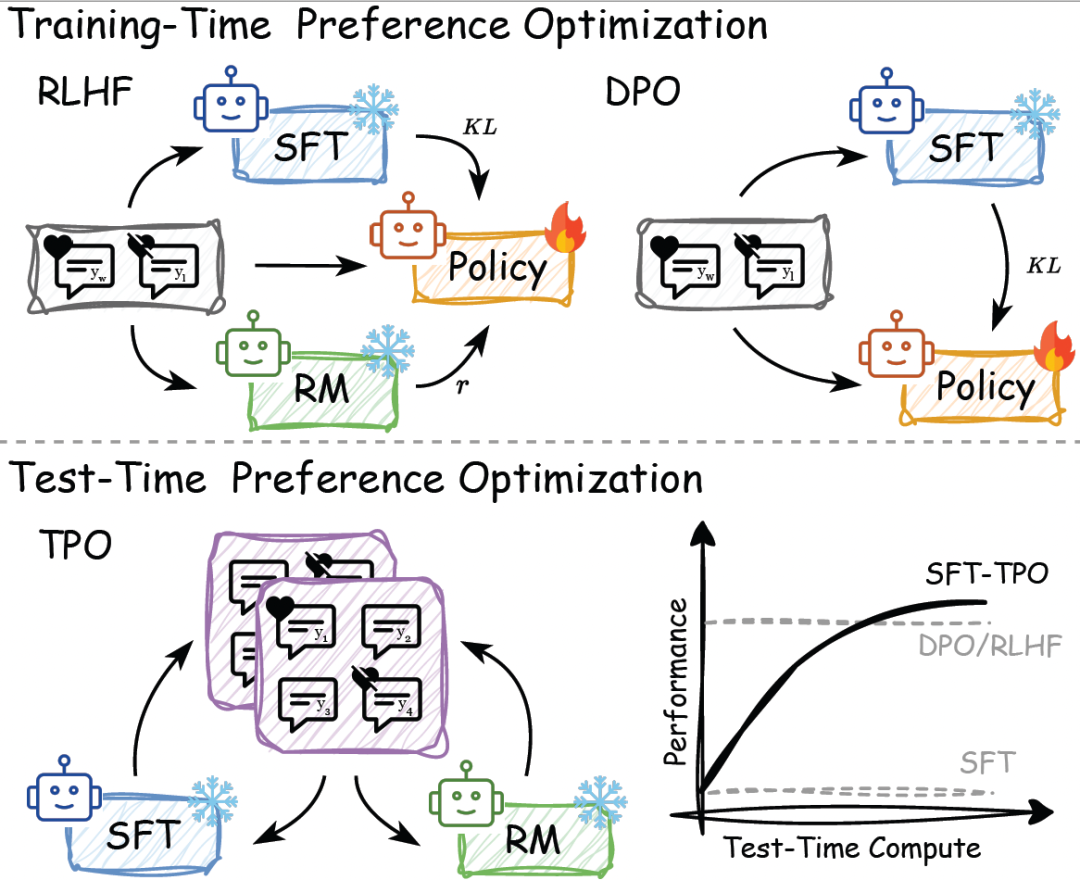
传统的对齐方法(如RLHF和DPO)通过更新模型参数来最小化损失函数,但需要迭代重训练,限制了大语言模型(LLM)对新数据和新需求的快速适应。本文提出推理时偏好优化(Test-time Preference Optimization,TPO),为推理时的偏好优化提供了一种轻量、高效且可解释的解决方案,实现人类偏好的即时对齐,无需进行额外的重训练。

标题:Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback
论文:https://arxiv.org/abs/2501.12895
Github:https://github.com/yafuly/TPO
Huggingface:https://huggingface.co/papers/2501.12895
单位:上海人工智能实验室、香港中文大学
TPO团队 投稿
编辑:深度学习自然语言处理
概述
随着大语言模型(LLMs)在各类任务中展现出令人瞩目的能力,如何确保它们生成的回复既符合预期又安全,始终是一项关键挑战。传统的偏好对齐方法,如基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO),依赖于训练过程中的模型参数更新,但在面对不断变化的数据和需求时,缺乏足够的灵活性来适应这些变化。
为了突破这一瓶颈,上海⼈⼯智能实验室、⾹港中⽂⼤学等联合提出了推理时偏好优化(TPO)方法,通过在推理阶段与奖励模型交互,借助可解释的文本反馈,迭代优化模型输出,实现了即时的模型对齐,而无需重新训练。实验结果表明,TPO 能够有效提升未对齐模型的表现,甚至超越经过训练的对齐模型,为模型偏好对齐提供了一种全新的思路。
TPO特点:
(1)推理时对齐、无需训练:TPO 通过与奖励模型的推理阶段交互,实现即时对齐偏好,省去了额外的模型参数更新过程。
(2)基于文本反馈:TPO 使用可解释的文本反馈(而非数值梯度)来指导优化,让模型“理解”并“执行”文本评价,无需更新模型参数。
(3)优于传统方法:在推理阶段,未对齐的模型(例如 Llama-3.1-70B-SFT)经过数次 TPO 迭代,能够持续逼近奖励模型的偏好。在多个基准测试中,其表现甚至超越了已在训练时对齐的版本(例如 Llama-3.1-70B-Instruct)。
(4)灵活适应性:TPO 能够灵活应对不断变化的数据和需求,具有较强的适应性,并且能够在资源有限的环境下高效运行。
方法
偏好优化旨在将策略模型 与人类偏好对齐,提升生成符合偏好的输出的概率,同时降低生成不符合偏好的输出的概率。该目标可表示为:
其中, 是评分函数,用于量化策略与数据集 中偏好的对齐程度。、和分别表示输入、优选的(获胜)回复和不优选的(失败)回复。
为实现这一目标,已有多种方法用来实现评分函数 ,如RLHF和DPO通过训练时偏好优化来对齐人类偏好。这些方法通过基于梯度的方法(如随机梯度下降,SGD)优化模型参数(如神经网络中的权重 ),使得生成符合人类偏好的输出概率更大。每次更新的步骤如下:
其中 是学习率, 是损失函数对模型参数 的梯度。通过这种方式训练时更新模型参数,以改变输出分布 ,从而生成更符合偏好的输出。
我们提出推理时偏好优化(TPO),与传统方法不同,TPO 不改变模型参数 ,而是搜索最优上下文参数 ,在推理时重新分配概率,从而更新输出分布 。TPO将传统梯度下降的核心原理适配文本化框架。与直接应用 更新模型参数不同,TPO通过解释和处理文本损失和文本梯度,为模型生成的回复提供可解释的优化信号。
如图2所示,TPO包含四个关键组件,类似于标准的梯度优化方法:变量定义、损失计算、梯度计算和变量优化。我们使用奖励模型 作为人类偏好的代理,提供生成回复质量的反馈。在推理时对齐过程中,系统通过迭代调整输出,使其逐步更符合奖励模型的偏好。
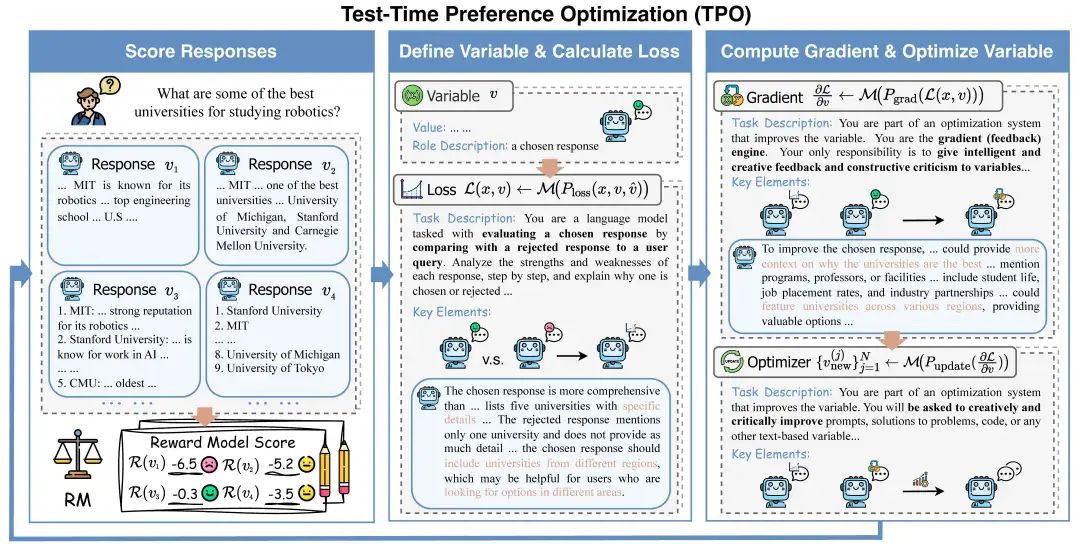
初始化:给定查询 ,我们从大语言模型 中采样 个候选回复 。然后,使用奖励模型 对每个回复进行评分,得到评分集 **,并添加到缓存中:
基于这些评分,我们选择得分最高的回复 作为选定回复,得分最低的回复 作为被拒绝回复。
文本损失函数:我们定义了一个文本损失提示 ,用于比较选定回复 和被拒绝回复 ,识别 的优点和 的不足。通过将提示 输入LLM ,我们得到文本形式的损失:
它解释了为什么 优于 ,并为进一步优化 提供了建议。
文本梯度与更新:接下来,我们通过整合文本损失 的提示 输入LLM生成文本梯度。TPO不会生成数字梯度,而是生成用于优化回复的文本指令。然后,我们通过提示 应用这些文本梯度,生成多个新的候选回复:
迭代优化:我们使用奖励模型 对每个新生成的回复 进行评估,并将评分对 添加到缓存 中。然后,从缓存中选择评分最高和最低的回复作为下一次迭代的选定和被拒绝回复。
该过程最多进行 次迭代,类似于训练过程,称为推理时训练。最终,我们选择缓存中评分最高的回复作为最终输出。
实验与结果
策略模型
未对齐模型:Llama-3.1-70B-SFT
已对齐模型:Llama-3.1-70B-Instruct; Llama-3.1-70B-DPO(UltraFeedback训练得来)
奖励模型
FsfairX-LLaMA3-RM-v0.1
Llama-3.1-Tulu-3-8B-RM
benchmark与评价指标
指令跟随:Alpaca Eval 2 (原始胜率WR和长度控制胜率LC)和 ArenaHard(胜率WR)
偏好对齐:HH-RLHF(采样500条,FsfairX-LLaMA3-RM-v0.1的平均奖励分数)
安全:BeaverTails-Evaluation(FsfairX-LLaMA3-RM-v0.1的平均奖励分数) 和 XSTest(WildGuard的准确率)
数学能力:MATH-500(使用0-shot配置和CoT提示,pass@1准确率)
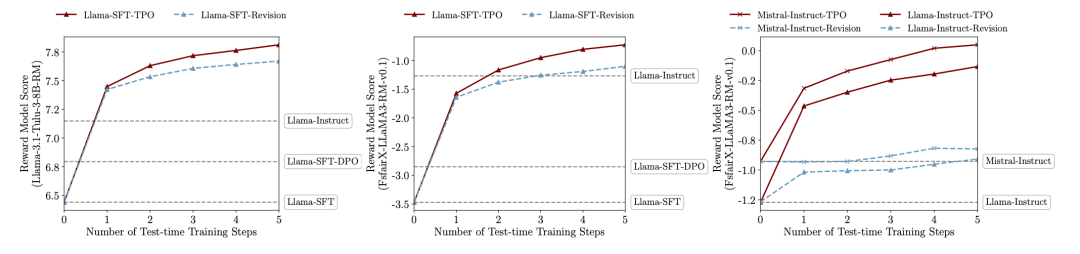
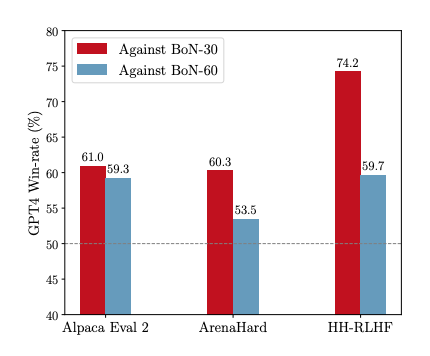
推理时训练效果:TPO 在推理时对模型进行优化,通过少量的迭代步数逐渐拟合奖励模型偏好,显著提升未对齐模型的性能,使其达到与对齐模型相当的水平;在已对齐模型上,TPO 进一步增强了对齐效果,而 Revision 版本(迭代优化选定回复而不参考被拒绝回复)的提升有限。
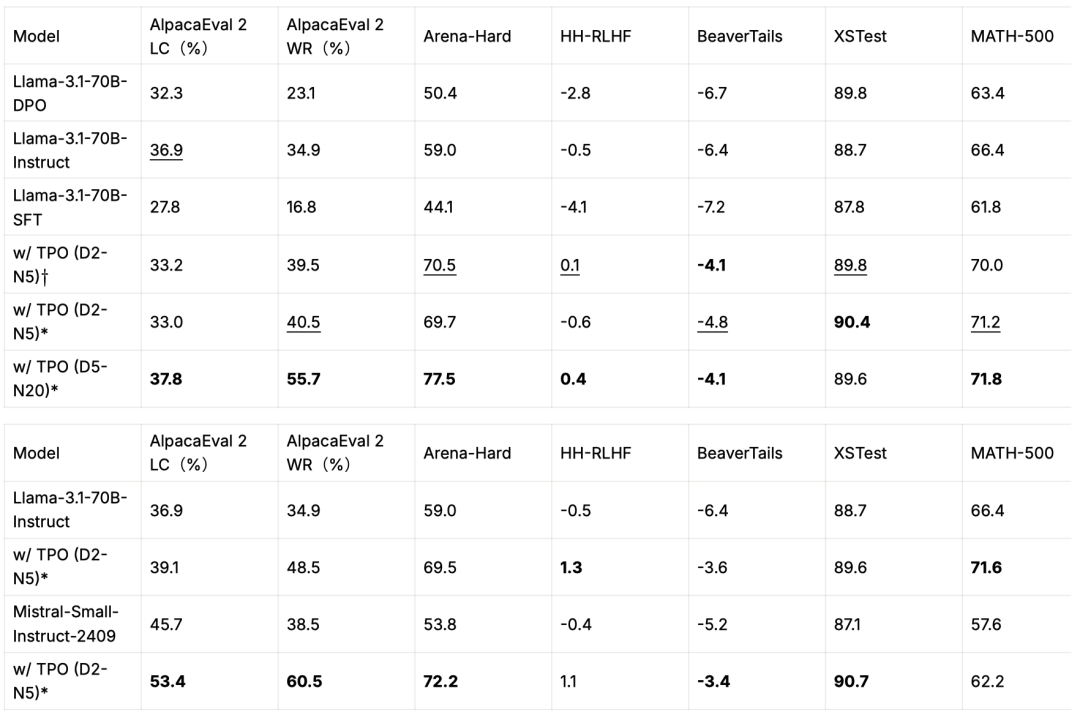
benchmark性能:TPO 能够显著提升模型性能指标,未对齐模型通过 TPO 超越了训练时对齐的模型,而对齐模型在经过TPO迭代后也获得了进一步的优化。D和N分别表示最大迭代次数和样本数量。* 表示使用奖励模型FsfairX-LLaMA3-RM-v0.1优化的模型,而 表示Llama-3.1-Tulu-3-8B-RM。
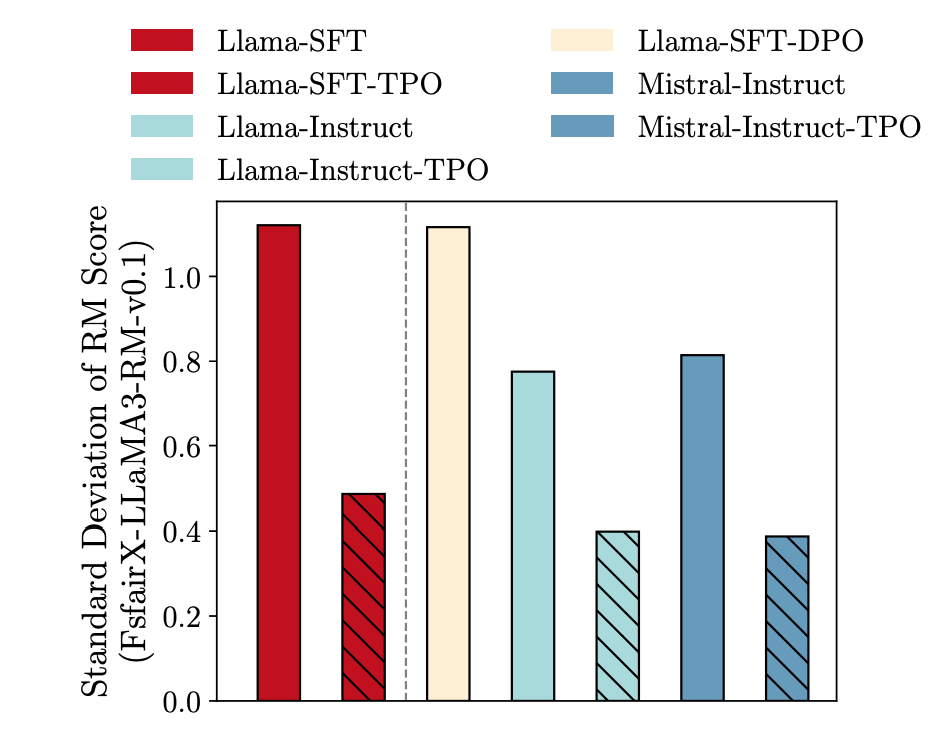
推理稳定性:TPO 能够有效地根据奖励模型的反馈调整模型输出,显著改善推理稳定性,表现为采样样本的奖励分数标准差的降低。
TPO的宽度:增加 TPO 的搜索宽度(即每次 TPO 迭代中采样的回复数量)能够显著提升性能,直到达到饱和。
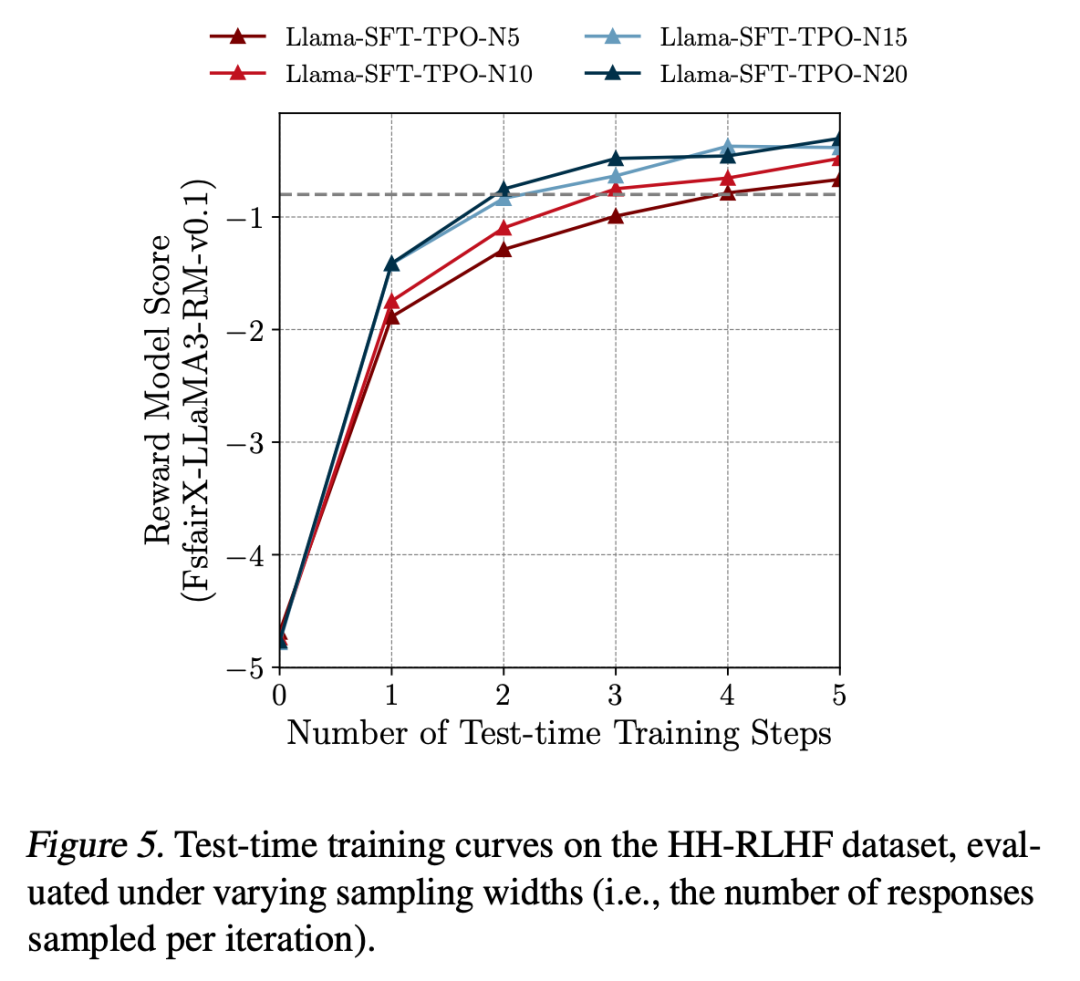
TPO的深度:增加 TPO 的搜索深度比单纯增加样本数量更有效地发现更高质量的回复。
TPO的计算成本:TPO 无需更改模型参数,与训练时偏好优化相比,在计算成本上具有显著优势。TPO 的计算成本(FLOPs)仅为一轮DPO训练(64,000条数据)所需开销的0.01%。而Instruct模型通常在百万级语料上多轮迭代,训练成本远高于DPO,进一步凸显了 TPO 在相对计算成本方面的优势。
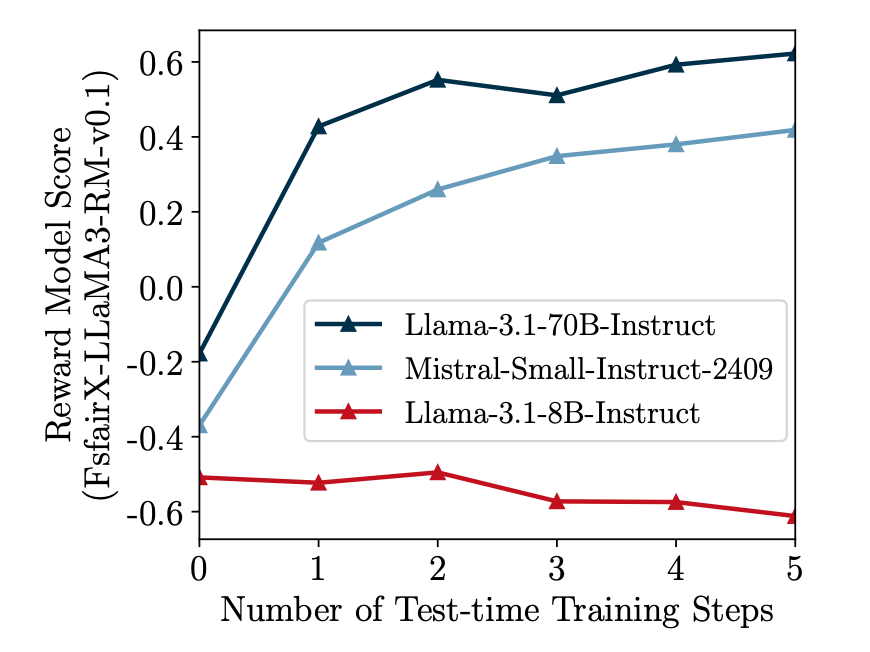
TPO的指令跟随前提:TPO 的成功依赖于策略模型具备基础的指令跟随能力,因为模型必须准确解释和响应数值形式的奖励模型偏好。
结语
提出推理时偏好优化(TPO)方法,通过在推理过程中与奖励模型交互,将奖励模型信号转化为“文本损失”和“文本梯度”,以此迭代优化模型输出。无需重新训练,即可让大语言模型与人类偏好对齐。TPO 为训练时偏好优化提供了轻量、高效且可解释的替代方案,充分利用了大语言模型在推理时的固有能力。通过即时文本反馈实现推理时对齐,TPO增强了模型在多样化场景中的适应能力,能快速响应变化的需求和任务的变化。
研究的意义与展望:未来的研究可聚焦于优化文本交互方法,使其能够适应更多专门任务,探索更鲁棒的奖励模型以提升偏好捕捉能力,并研究如何提升较弱模型在 TPO 中的表现,从而进一步拓展其应用场景和优化效果。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









