






知乎:庞天宇(已授权)
链接:https://zhuanlan.zhihu.com/p/32092055878
编辑:「深度学习自然语言处理」公众号
介绍一下我们最新的工作:Understanding R1-Zero-Like Training: A Critical Perspective
DeepSeek-V3-Base 在强化学习调优前就已经展现出了 “顿悟时刻”?
强化学习调优过程中输出长度不断增加,是否源于 GRPO 中的偏差?
将 GRPO 做对了,我们实现了 7B模型在 AIME 上的 SOTA!
完整细节请见:https://github.com/sail-sg/understand-r1-zero/blob/main/understand-r1-zero.pdf
代码地址:https://github.com/sail-sg/understand-r1-zero
我们采取“先理解再改进”的方法来研究 R1-Zero-like 训练。首先,我们对两个核心组件进行了批判性审视:基础模型和强化学习。
1. 关于基础模型
1a) DeepSeek-V3-Base 已经展现出 “顿悟时刻”!

1b) 作为 R1-Zero-like 训练中热门的选择,Qwen2.5 基础模型即使在没有提示模板的情况下,也展示了强大的推理能力:平均基准得分立即提升约 60%。这使得 Qwen2.5 基础模型更像是经过 QA 拼接训练的 SFT 模型。
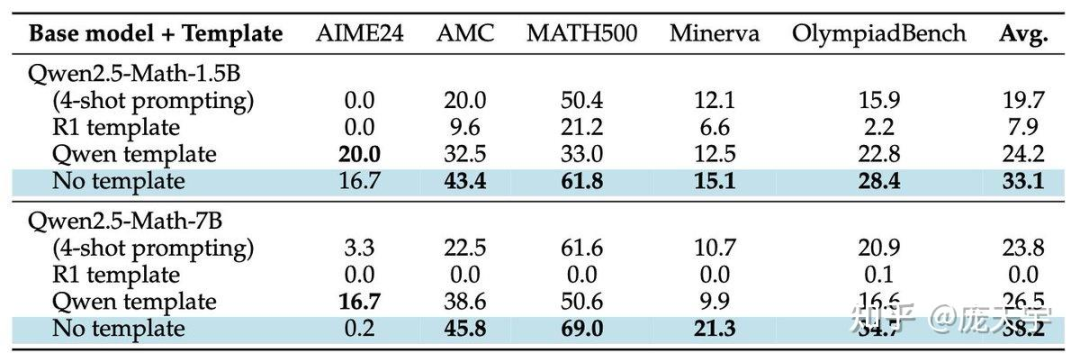
1a) 和 1b) 暗示,在强化学习通过奖励信号进一步强化之前,基础模型预训练中已经存在自我反思行为和数学解题能力的偏差。
但日益增长的回答长度,是否正是这种强化学习过程的必然结果呢?
2. 关于强化学习
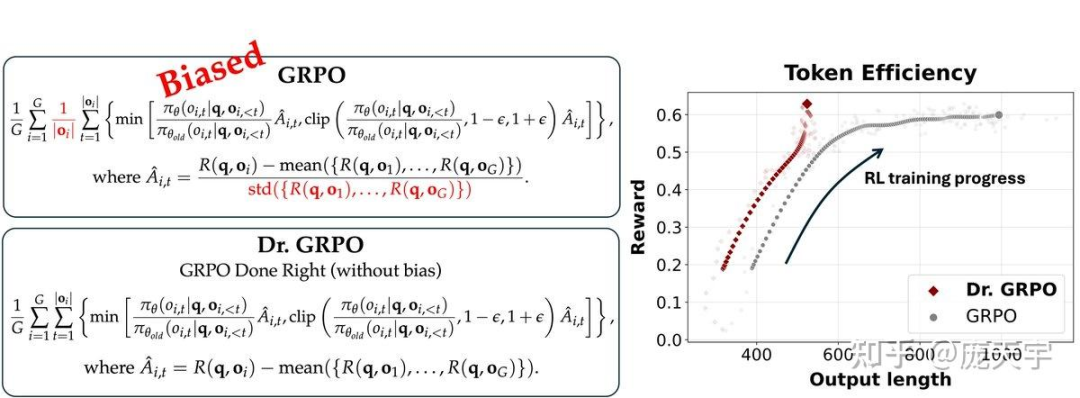
2a) GRPO 存在偏差:
长度归一化偏好较短的正确答案,而较长的错误答案则更受青睐 —— 长度偏差
标准差归一化则偏好过于简单或过于困难的问题,而非中等难度的问题 —— 难度偏差

2b) 值得注意的是,尽管 PPO 的公式本身是无偏的,但几乎所有开源实现在计算 masked_mean 时都会引入长度偏差。 部分原因正是这种长度偏差导致了回答长度的不断增长。

2c) 为了使 GRPO 真正“做对”,我们提出了 Dr. GRPO。
只需两处修改:移除长度归一化和标准差归一化(红色标记部分)。我们的新优化器无偏且具有更好的 token 效率(避免 GRPO 逐步生成越来越长的错误回答)。

分析总结
对基础模型和强化学习的分析表明,对于 R1-Zero 训练,最小化的配方(no tricks)如下:
算法:Dr. GRPO
数据:MATH 3-5 级别题目
模板:Qwen-Math
计算:27 小时 * 8 个 A100 这使我们在 Zero-RL 环境下实现了 7B 模型的 SOTA:AIME 2024 得分 43.3!
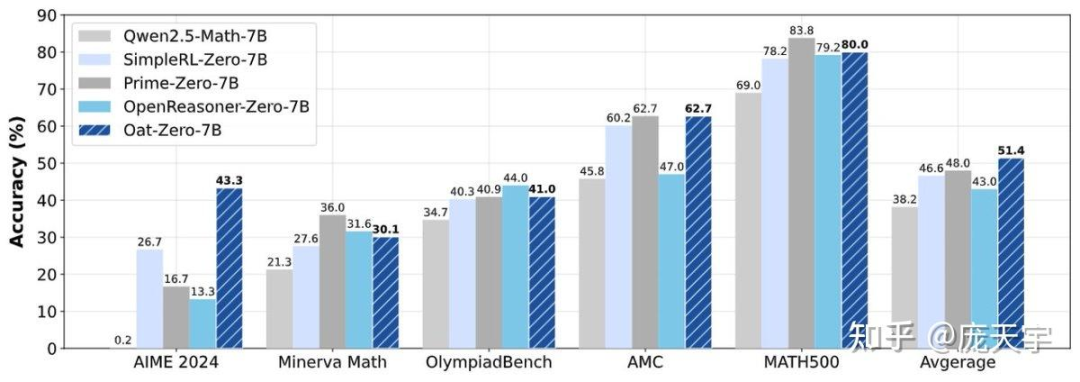
这还不是全部,更多精彩内容请查阅我们的论文、代码库和模型,例如:
针对基础代数(加、减、乘、除)题目的强化学习能提升奥林匹克级别的推理能力
Llama 模型同样可以“顿悟”
……
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









