







论文:In-depth Analysis of Graph-based RAG in a Unified Framework
链接:https://arxiv.org/abs/2503.04338
代码:https://github.com/JayLZhou/GraphRAG
研究团队:香港中文大学(深圳)与华为云研究人员
编辑:深度学习自然语言处理 公众号
研究背景与动机
当前,大语言模型(LLMs)广泛应用于各种领域,但受限于预训练数据的不足,往往产生“幻觉”(hallucination)现象。为此,学界提出了检索增强生成(RAG)方法,通过外部知识补充来提升模型的可靠性。近年来,基于图的RAG方法因其能够更好地捕捉语义结构和实体关系而受到广泛关注。然而,目前缺乏统一的框架系统地对这些方法进行比较和分析。
研究问题与目标
本文旨在提出一种统一的分析框架,系统性地对现有的graph-based RAG方法进行比较分析,并探索其关键性能因素。通过实验研究,作者探究明确了不同方法适用于何种问题类型,形成了一个普适的框架。并挖掘未来的研究潜力。
核心方法与统一框架设计
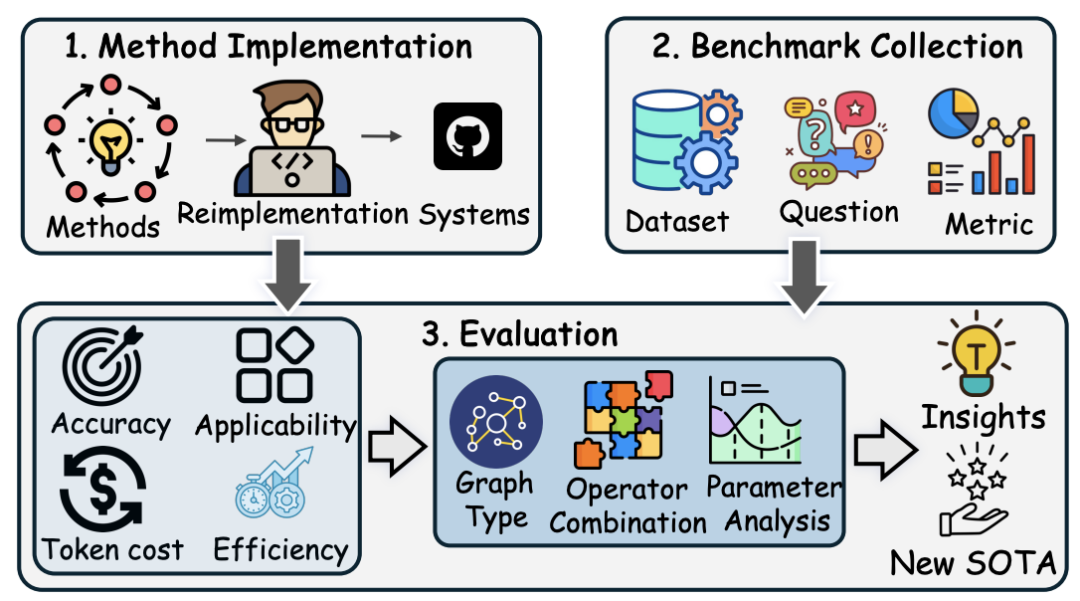
图构建(Graph Building)
将语料库分割为多个chunk
从每个chunk中提取节点和边,构建不同类型的图结构(如树、知识图谱、文本知识图谱、富知识图谱等)
索引构建(Index Construction)
为图中的节点和关系创建高效的向量数据库索引,采用文本编码模型(如BGE-M3)
使用社区发现算法(如Leiden算法)建立社区索引,以高效支持在线查询
操作符配置(Operator Configuration)提炼出节点、关系、chunk、子图、社区等多种操作符
不同方法通过选取特定操作符组合,实现个性化的检索策略
检索与生成(Retrieval & Generation)根据用户问题,检索相关节点、关系或社区,结合原始问题构造prompt
使用LLM生成答案,生成范式包括直接生成和Map-Reduce两种模式
实验评估与结果
作者在11个真实世界数据集(包括特定问题和抽象问题任务)上对12种主流的基于图的RAG方法进行全面评估。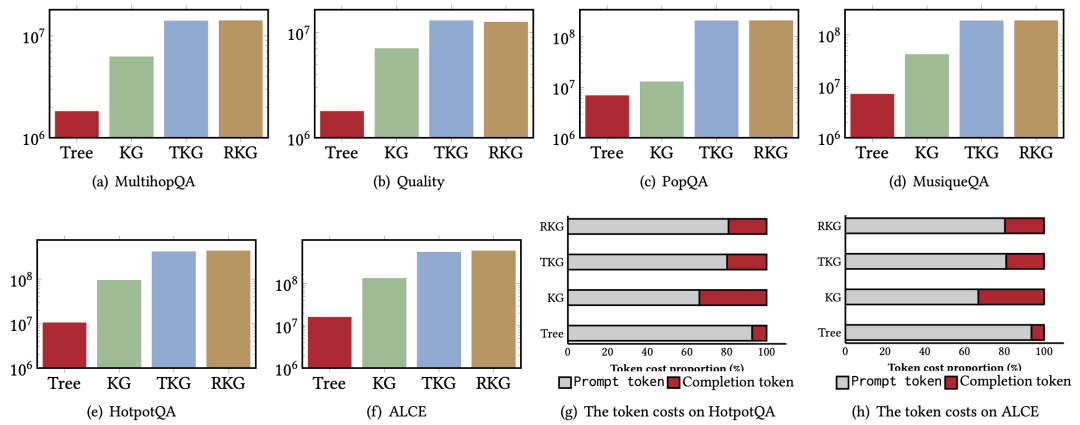
实验数据集与评估指标
特定问题(Specific QA) 数据集(如MultihopQA、Quality、PopQA等),评估指标为准确率、召回率以及字符串匹配指标(STRREC、STREM、STRHIT)。
抽象问题(Abstract QA) 数据集(如Mix、CS、Legal等),采用GPT-4o作为评估工具,从全面性、多样性、赋能性和整体质量四个维度进行比较。
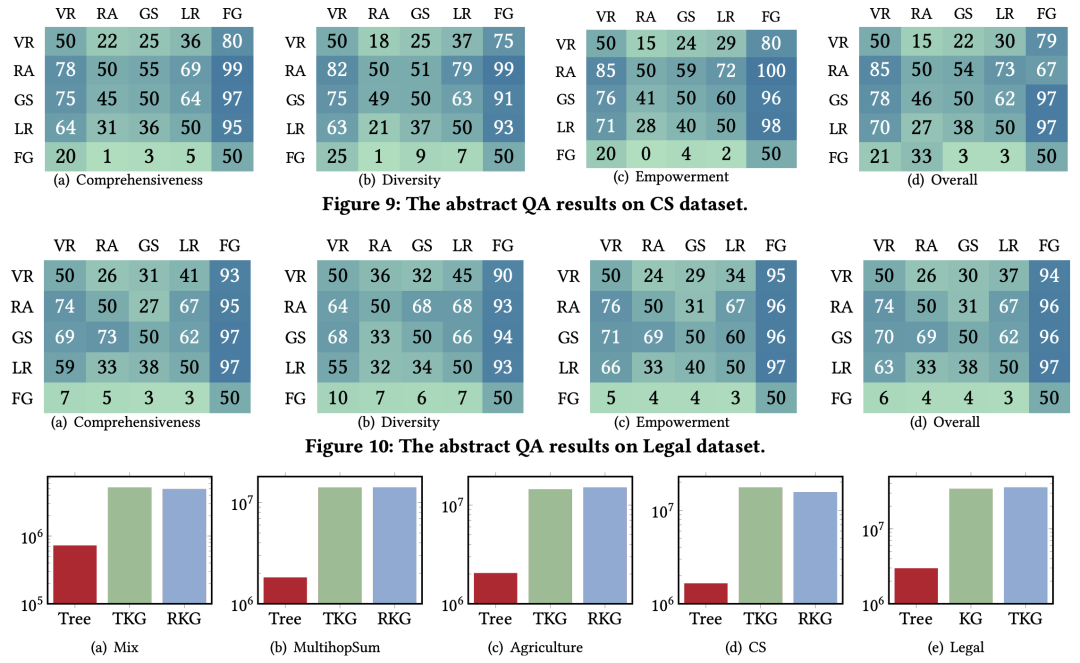
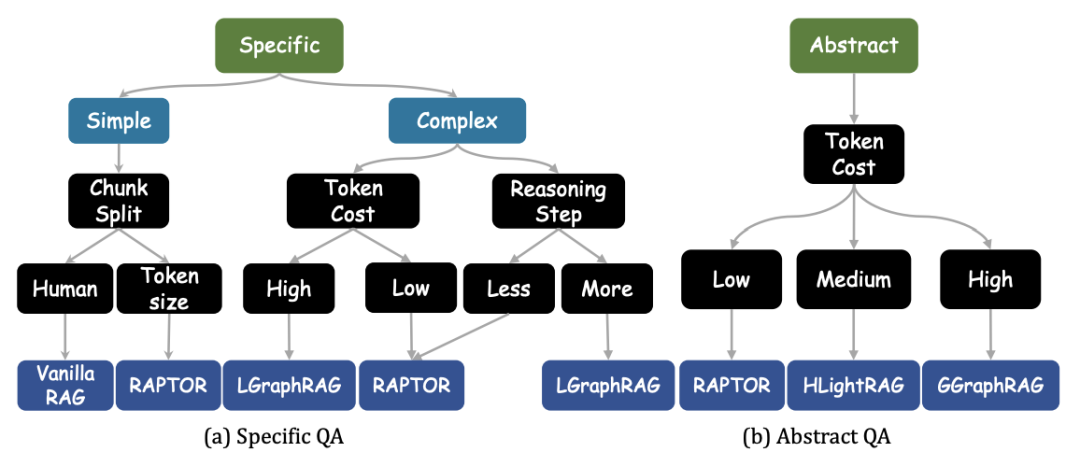
主要结论
基于图的RAG普遍优于Vanilla RAG,尤其在复杂问题和抽象问题任务中表现突出。
高层次总结信息(如社区报告)对于复杂和抽象问题具有关键作用。
在特定问题任务上,RAPTOR方法表现出色,通过树结构的高层信息显著提高了准确性。
作者提出了新的方法变体(如VGraphRAG、CheapRAG),在多个任务中超越了现有最优方法。
研究贡献与创新点
统一分析框架:首次提出覆盖全部主流图RAG方法的统一框架,明确提炼出关键操作,并分析关键性能影响因素。
系统比较:首次在统一实验设置下,细致分析现有方法的优劣及其适用场景。
新方法提出:通过组合现有技术,设计出新的图RAG方法变体,在实验中展现出更好的性能与成本效益。
未来研究展望
作者指出未来值得探索的问题:
动态更新的知识图谱如何高效地与RAG结合;
如何有效评估构建图的质量并降低图构建成本;
如何设计更为经济高效的图检索方法,尤其是在实际工业部署中;
隐私保护场景下的RAG方法研究。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









