



近年来,大型语言模型在推理任务上的突破,如OpenAI的o1模型和DeepSeek R1,似乎确立了一个“参数越大,能力越强”的行业共识。然而,这种依赖千亿甚至万亿参数规模的路径,不仅带来了高昂的训练和推理成本,也使得尖端AI研究越来越集中于少数几家资源雄厚的科技巨头手中。这种资源壁垒严重限制了广大研究机构和企业的参与,阻碍了AI技术的民主化与普及。

论文:Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B
链接:https://arxiv.org/pdf/2511.06221
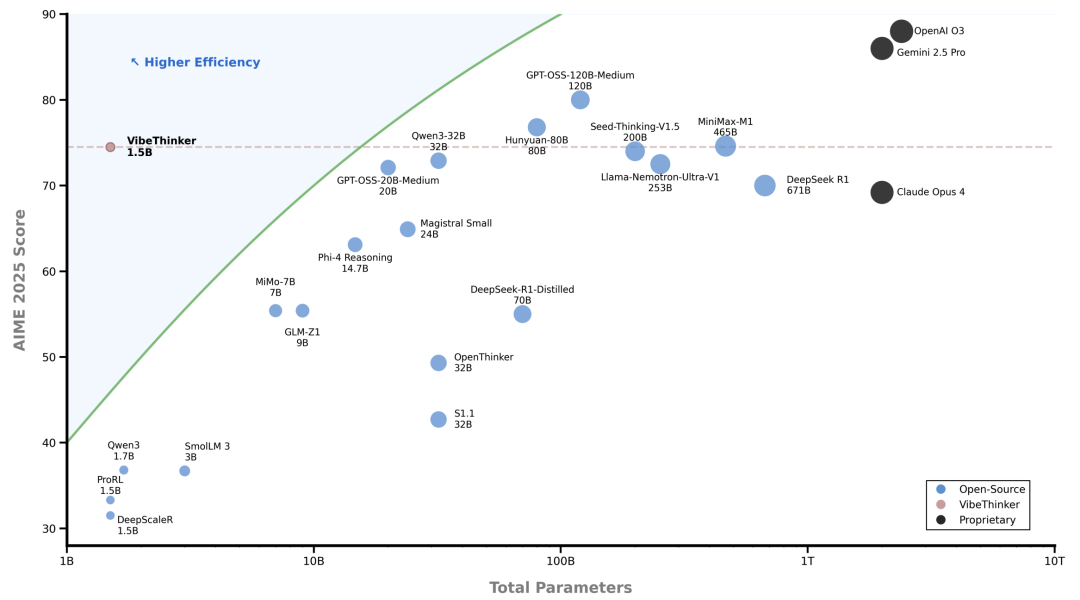
正是在这样的背景下,微博AI团队提出了一个观点:小模型同样可以具备强大的逻辑推理能力。他们开发的VibeThinker-1.5B,仅用1.5亿参数和不到8000美元的训练成本,在多项高难度数学和编程基准测试中,竟超越了参数规模超过400倍的DeepSeek R1等顶级大模型。这一成果不仅挑战了传统的“缩放定律”,也为我们打开了一扇窗:通过精巧的算法设计,而非粗暴的参数堆叠,我们或许能够以极低的成本实现高质量的AI推理。
本论文的核心创新在于提出并实践了“Spectrum-to-Signal Principle (SSP) ”——一种以多样性为中心的后训练优化框架。它重新定义了监督微调(SFT)和强化学习(RL)的角色分工,使小模型在数学、代码等复杂任务上展现出令人惊叹的推理能力。接下来,我们将深入解析这一突破性工作背后的动机、方法、实验与启示。
为什么小模型需要强大推理能力?
当前AI领域的主流观点认为,模型的逻辑推理能力与参数规模强相关。像DeepSeek R1(6710亿参数)、Kimi K2(超1万亿参数)这样的“巨无霸”模型,正是因为其庞大的参数量,才能在数学证明、临床诊断、编程竞赛等复杂任务中表现出色。然而,这种路径带来了两个严峻问题:
资源壁垒:训练和部署这类模型需要数百万美元的计算资源,将大多数高校、中小企业和研究团队排除在尖端研究之外。
能效与部署限制:大模型难以在边缘设备(如手机、车载系统)上运行,限制了AI技术的实际应用场景。
论文作者敏锐地指出:如果我们能让小模型具备媲美大模型的推理能力,将极大降低AI研发门槛,推动技术民主化。尽管已有一些小型模型(如DeepscaleR、Qwen3-1.7B)在推理任务上有所尝试,但它们尚未充分发挥潜力。VibeThinker-1.5B的目标,正是要通过一种全新的训练范式,证明“小模型也能有大智慧”。
核心方法:Spectrum-to-Signal Principle (SSP)
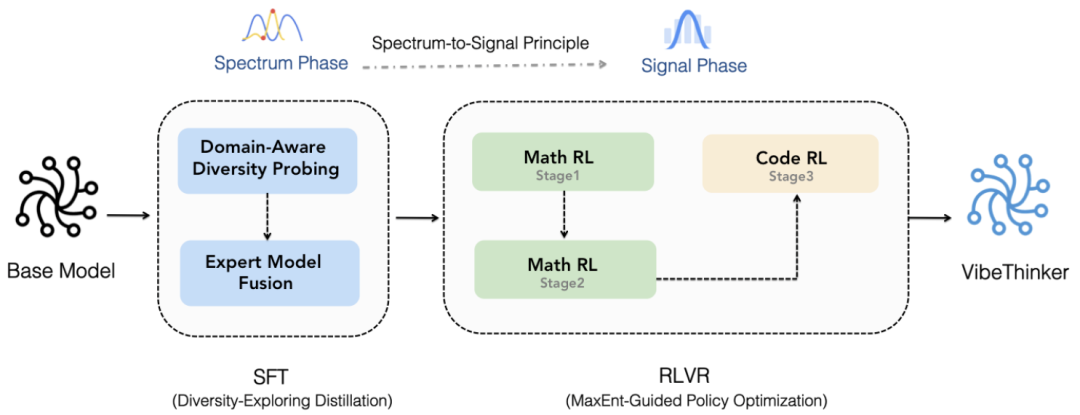
论文最核心的贡献是提出了“Spectrum-to-Signal Principle (SSP)”,这是一个将监督微调(SFT)和强化学习(RL)重新分工的框架。我们可以把它想象成“先广撒网,再精准捕捞”的过程:
Spectrum Phase(频谱阶段)—— SFT
目标不是追求单一正确答案,而是生成多样化的解题路径。这就像让学生先尝试多种解法,而不是死记硬背一种标准答案。Signal Phase(信号阶段)—— RL
目标是从多样化的路径中,找出并强化那些正确的解题方法。这就像老师从学生的多种尝试中,指出哪条路是通的,并鼓励学生以后多走这条路。
下面具体看这两个阶段是如何实现的:
SFT阶段:Two-Stage Diversity-Exploring Distillation
为了实现“频谱”的广度,作者设计了一个两阶段蒸馏方法:
阶段一:Domain-Aware Diversity Probing(领域感知多样性探测)
首先将数学知识划分为多个子领域(如代数、几何、微积分等),在每个子领域上训练“专家模型”,并选择那些在Pass@K指标上表现最好的检查点。Pass@K衡量的是模型生成k个答案中至少有一个正确的概率,它直接反映了模型的解题多样性。阶段二:Expert Model Fusion(专家模型融合)
将各子领域的专家模型参数进行加权平均,融合成一个统一的SFT模型。这个过程就像是把多个专科医生的诊断经验整合成一位全科医生的知识体系。
RL阶段:MaxEnt-Guided Policy Optimization (MGPO)
在RL阶段,作者没有使用传统的静态数据集,而是提出了一个基于信息论的动态训练策略:
核心思想:模型在那些“半懂不懂”的问题上学习效果最好。
具体来说,如果模型对某个问题的正确率接近50%,说明它正处于“认知边缘”——既不是完全不会,也不是完全掌握,这正是最有学习价值的状态。关键技术:Entropy Deviation Regularization(熵偏离正则化)
作者定义了一个“最大熵偏离距离”,用来衡量模型当前表现与理想不确定状态(正确率50%)的差距。这个距离越小,说明问题越值得被重点训练。
我们来具体看MGPO中的关键公式:
符号解释:
:模型在问题q上的正确率
:理想的不确定状态,固定为0.5
:衡量当前正确率与理想状态的“距离”
公式作用:这个公式实际上在计算“当前表现与理想学习状态的差距”。当正确率接近0.5时,距离最小,该问题在训练中的权重就最大。
基于这个距离,作者构建了一个权重函数:
其中控制权重的敏感度。这个权重随后被应用到GRPO的优势函数中,引导模型优先学习那些最“值得学”的问题。
训练流程与数据管理
VibeThinker-1.5B的训练遵循清晰的SSP管道:
基础模型:基于Qwen2.5-Math-1.5B,这是一个2024年9月发布的以数学为主的小模型。
SFT频谱阶段:通过两阶段蒸馏,构建多样性最大的SFT模型。
RL信号阶段:采用MGPO框架,分阶段训练数学推理(16K→32K上下文)和代码生成任务。
在数据管理方面,团队实施了严格的去污染措施:
使用10-gram匹配检测训练数据与测试集的重叠
去除语义相似的样本,防止信息泄露
确保模型表现反映真实的泛化能力,而非记忆结果
这些措施有力回应了关于数据污染的质疑,特别是考虑到VibeThinker在2025年发布的基准(如AIME25、HMMT25)上表现出色,而这些数据在基础模型训练时根本不存在。
实验设计与评估设置
为了全面评估模型能力,论文采用了三类基准测试:
数学推理:AIME24/25、HMMT25、MATH-500——这些是国际数学竞赛级别的难题
代码生成:LiveCodeBench V5/V6——评估实际编程能力
专业知识:GPQA-Diamond——博士水平的多学科知识测试
基线模型分为三组:
顶尖的小型推理模型(<3B参数)
大型推理模型(7B-671B参数)
顶级非推理模型(如GPT-4.1、Claude Opus)
评估使用vLLM后端,采用温度采样,并对不同任务设置不同的采样次数以确保统计可靠性。
实验结果与性能分析
与小型推理模型的对比
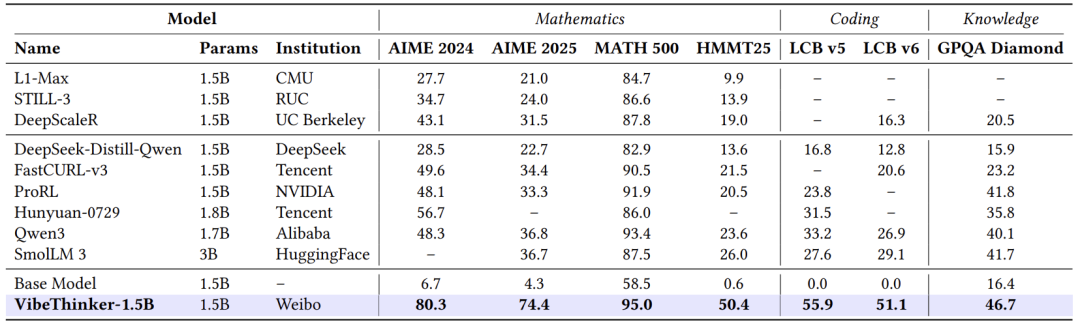
从表中可以看出,VibeThinker-1.5B在几乎所有指标上都大幅领先其他小模型:
AIME25:74.4 vs 第二名Qwen3-1.7B的36.8(领先一倍以上)
HMMT25:50.4 vs 第二名SmoILM-3B的26.0
LiveCodeBench V6:51.1 vs 第二名Qwen3-1.7B的26.9
更令人印象深刻的是,相比基础模型(AIME25仅4.3分),VibeThinker实现了超过70分的提升,证明其训练方法的极端有效性。
与大型推理模型的对比
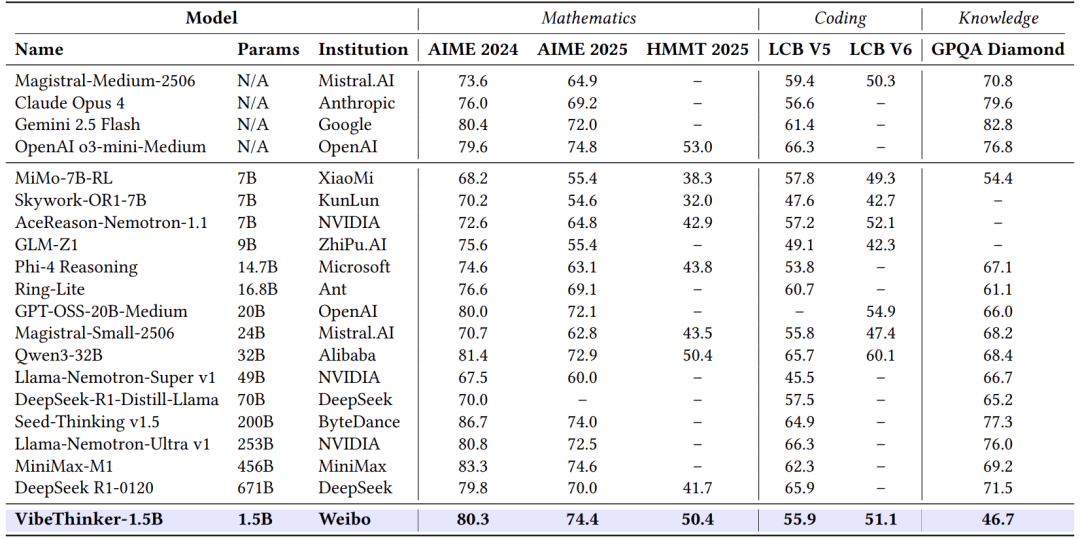
尽管参数规模相差数百倍,VibeThinker在多项数学任务上媲美甚至超越了顶级大模型:
AIME24:80.3 vs DeepSeek R1的79.8
AIME25:74.4 vs DeepSeek R1的70.0
HMMT25:50.4 vs DeepSeek R1的41.7
在代码任务上,它也达到了与Magistral Medium、Claude Opus相当的水平。这表明推理能力不一定与参数规模成正比,精巧的算法设计可以弥补参数的不足。
与非推理模型的对比
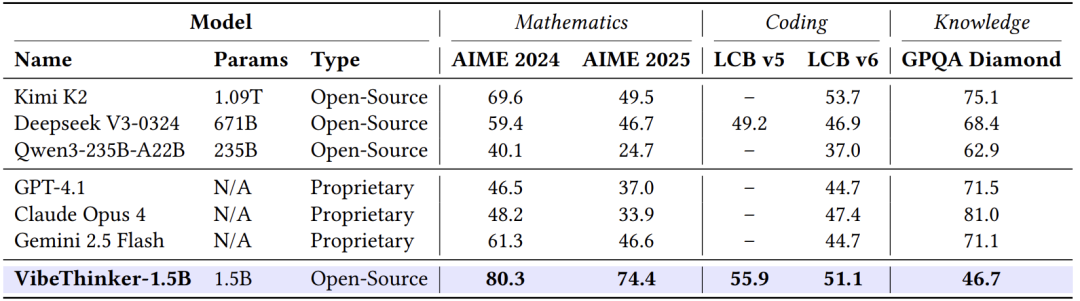
即使对比参数规模大100倍以上的非推理模型(如Kimi K2的1.09万亿参数),VibeThinker在数学任务上仍然保持绝对优势:
AIME25:74.4 vs Kimi K2的49.5
AIME24:80.3 vs Kimi K2的69.6
这进一步证明,专门优化的推理小模型可以在特定任务上超越通用的巨型模型。
成本效益分析

VibeThinker的训练成本仅为7,800美元,而同类大模型的成本在29.4万至53.5万美元之间——成本降低30-60倍。如果考虑推理成本,小模型还有20-70倍的优势,且能在边缘设备上部署。
讨论与局限性
尽管在推理任务上表现出色,VibeThinker-1.5B在通用知识任务(GPQA)上仍有明显短板(46.7分 vs 大模型的70+分)。这表明小模型在知识容量方面确实存在固有局限——它们可以学会“如何思考”,但难以存储海量事实知识。
作者也积极回应了数据污染的质疑:
基础模型发布于2024年9月,而测试基准(AIME25、HMMT25)发布于2025年,时间上不可能污染
同类基于Qwen2.5-Math的模型在相同测试中表现很差,进一步证明非数据污染所致
未来研究方向包括:
增强小模型的通用知识能力
将SSP框架扩展到更多领域
探索更高效的基础模型架构
结论
VibeThinker-1.5B的研究向我们证明了一个重要事实:AI推理能力的突破不一定来自参数规模的无限扩大,而是可以通过精巧的算法设计实现。其核心贡献可总结为三点:
提出了SSP框架,将多样性作为连接SFT与RL的桥梁
开发了MGPO算法,基于信息论动态优化训练过程
以极低成本实现了与大模型媲美的推理能力,打破了资源壁垒
这项工作的意义远不止于技术突破。它让更多研究团队能够以可承受的成本参与前沿AI研究,促进了AI技术的民主化。虽然小模型在通用知识上仍有不足,但作为专门化的推理引擎,它们已经展现出巨大的应用潜力。未来,我们有理由期待看到更多“小身材,大智慧”的模型出现,推动AI技术走向更加高效、普惠的未来。



















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









