







 本文介绍了如何使用Python3爬取并分析BOSS直聘网站上的数据分析岗位信息,包括信息爬取、数据解析、数据分析等步骤。通过爬虫抓取北上广深的职位详情,利用BeautifulSoup解析数据,然后进行数据清洗和特征分析,揭示岗位特点和行业趋势。
本文介绍了如何使用Python3爬取并分析BOSS直聘网站上的数据分析岗位信息,包括信息爬取、数据解析、数据分析等步骤。通过爬虫抓取北上广深的职位详情,利用BeautifulSoup解析数据,然后进行数据清洗和特征分析,揭示岗位特点和行业趋势。
Boss直聘网站已改用ajax了,可以改用selenium库爬取,下面爬虫已过时,但数据分析方法还是可以用的,数据分析全部代码都已给出。
语言:Python3
目录
一、信息爬取
二、数据分析
2.1 数据解析
2.2 数据分析
2.2.1 数据清洗
2.2.2 查看单个特征分布
2.2.3 分析特征与标签的关系
三、建模
ps:这里推荐一个学习Python3爬虫非常好的网址,https://cuiqingcai.com/5052.html。内容来自于《Python3网络爬虫开发实战》一书。
首先来参观下页面信息,要爬取的信息有:岗位名称,地区,工作经验,学历,企业信息,薪水。我们会爬取北上广深四个城市的招聘信息。
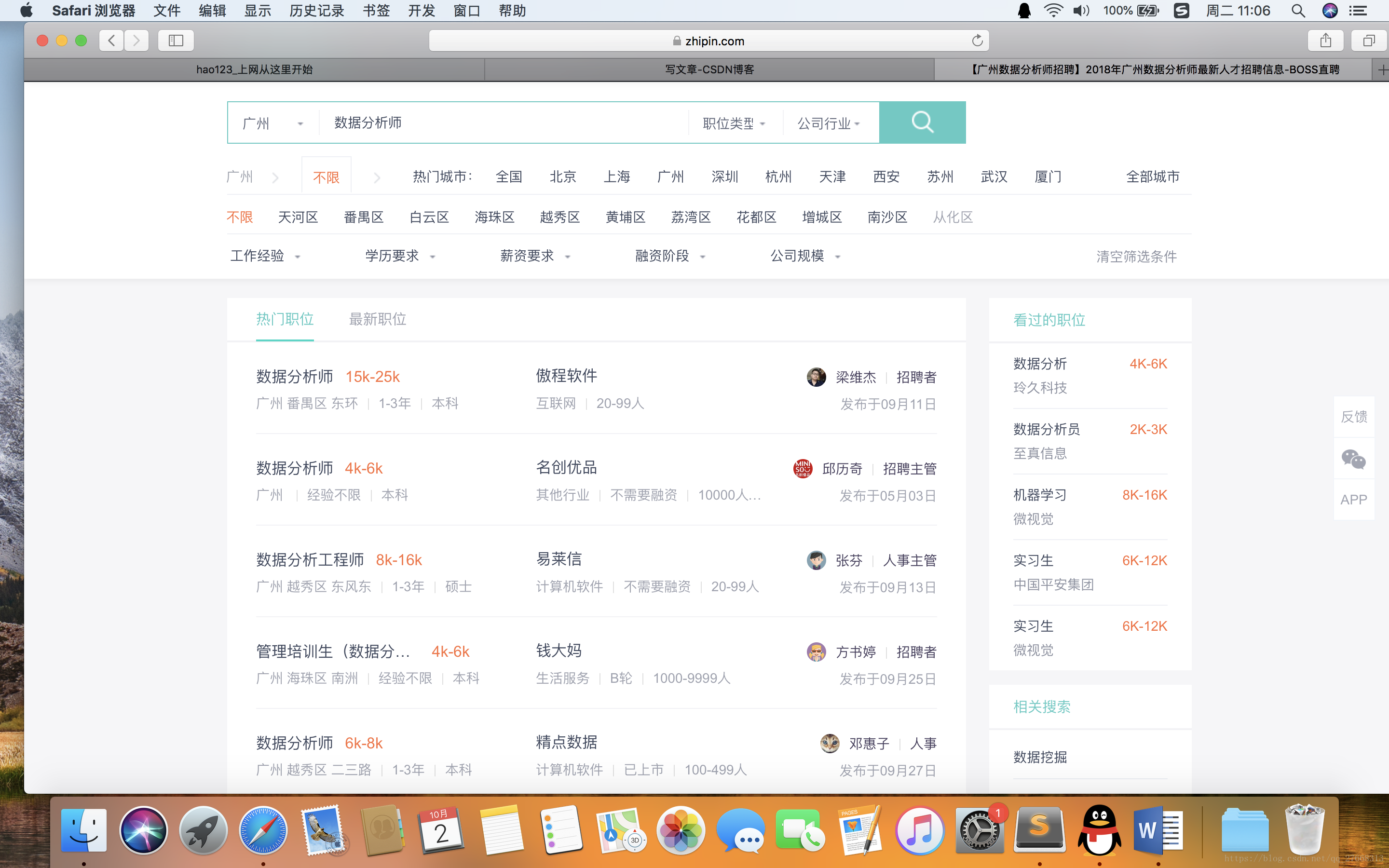
一、信息爬取
需要导入的库如下,库的安装参考上面给出的链接。
# coding:utf-8
import requests
import csv
import pandas as pd
from bs4 import BeautifulSoup
from requests.exceptions import RequestExceptionrequests相对urllib更加强大,更加友好。虽然与高大上的scrapy相比low了不少,但我们只是从网页上简单爬取一些信息,所以选用requests库。使用BeautifulSoup解析库对爬取的网页信息进行解析。使用pandas.DataFrame将数据保存为csv格式,使用这种方式保存非常方便。
下面我们逐步来完成代码的编写
首先我们需要定义一个函数来获取网站每页的内容。这里使用了一个代理IP。首先,构建一个最简单的GET请求,网站会判断如果客户端发起的是GET请求的话,它返回相应的请求信息。
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) ' +
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
html = requests.get(url, headers=headers)
if html.status_code == 200:
return html.text
return None
except RequestException:
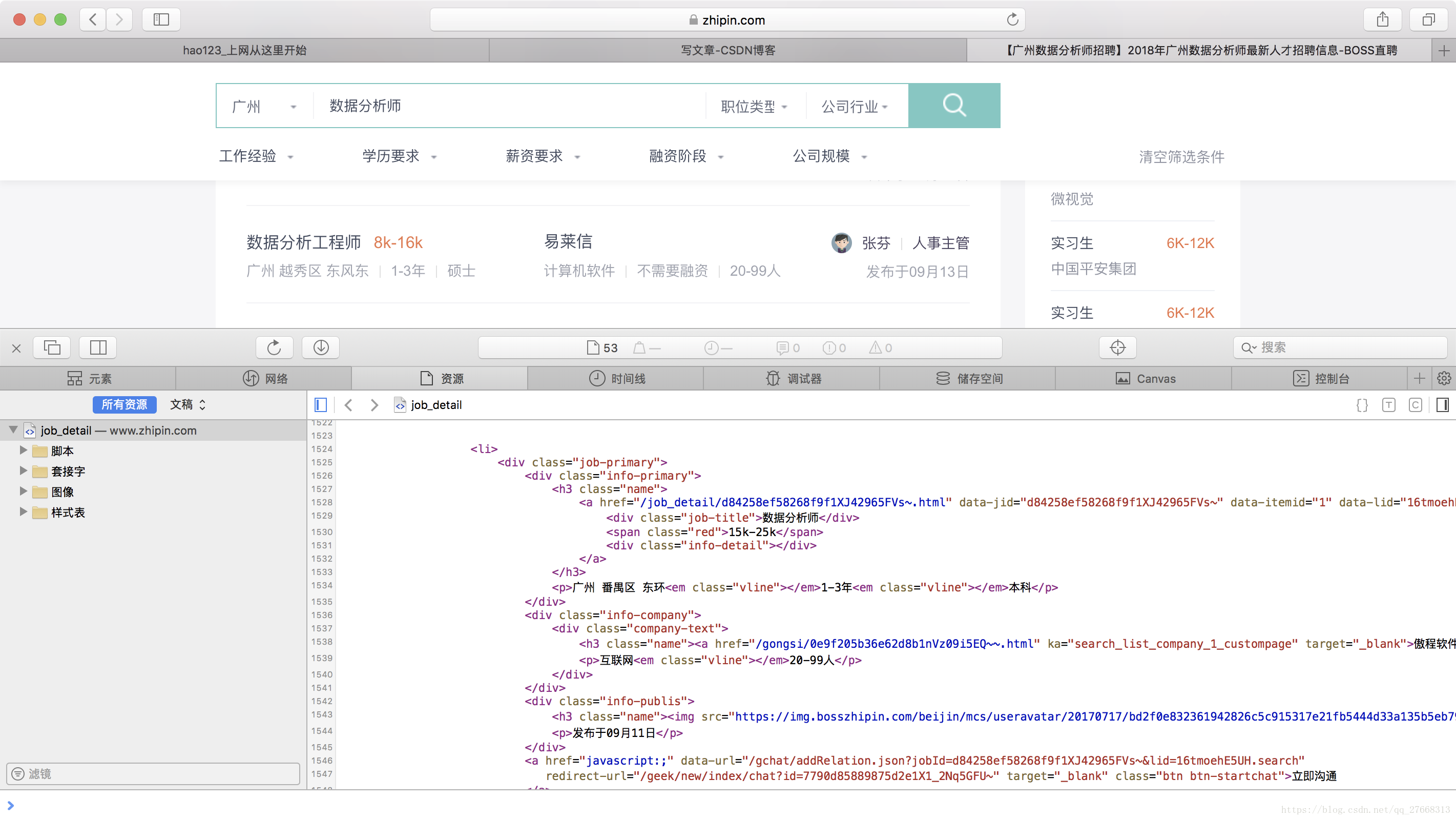
return None来看下我们爬取的页面信息源代码长啥样(查看网页源代码的方法这里就不叙述了,网上很多教程),里面的部分黑色字体就是我们要爬取的数据。
获取了一个页面的信息后,就可以对信息进行解析,我们定义一个可以一次解析一个页面的函数,如下。首先定义一个全局变量,用于存储每个公司的招聘信息。(ps:再次说一下,对代码中函数用法不明白的,或者对网页结构不懂的同学,先去文章最上面给出的链接看看)
网页结构可以看成是树结构,上图中<div class='job-primary'>~~</div>可看成一棵子树,包含了一个企业该岗位的全部招聘信息,该子树包含了<div class='info-primary'>~~</div>和<div class='info-company'>~~</div>两个子节点。
下面代码中使用find_all函数获取当前页面中所有<div class='job-primary'>~~</div>子树,即当前页面中所有企业该岗位的招聘信息。通过一个for 循环来遍历companies中的每棵子树,对每棵子树调用parse_one_company()函数进行解析。然后将解析得到的数据存储到result_all列表中。
result_all = [] # 用于存储样本
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
companies = soup.find_all('div', 'job-primary', True)
for com in companies:
res = parse_one_company(com)
result_all.append(res)parse_one_company()函数用来对每个<div class='job-primary'>~~</div>子树解析,也就是对每个企业该岗位的招聘信息的解析。在<div class='info-company'>~~</div>节点下解析得到企业所属行业和规模两个信息,即对应网页源代码中的“互联网”和“20-99”。在<div class='info-primary'>~~</div>节点下解析得到岗位名称,薪水,企业地址,工作经验和学历要求信息,即对应网页源代码中的“数据分析师”,“15k-25k”,“广州 番禺区 东环”,“1-3年”,“本科”。最后将这些数据存储到result列表中,并返回。
def parse_one_company(comp):
result = []
company_soup = comp.find('div', class_='info-company')
com_desc = company_soup.find('p').text
primary_soup = comp.find('div', class_='info-primary')
job_name = primary_soup.find('div').text
salary = primary_soup.find('span').text
requirement = primary_soup.find('p').text
result.append(com_desc)
result.append(job_name)
result.append(salary)
result.append(requirement)
return result上面只是爬取了一个页面一个地区的信息。接下来我们完成要对BOSS直聘上北上广深四个地区的所有数据分析师岗位信息进行爬取。这也是代码的最后一部分。
我们定义了parse_all_page()函数用于爬取四个地区的所有信息。函数中给出了四个地区的url链接,参数num用于指定要爬取的地区,offset参数用于指定要爬取的页面。在最下面的两个for循环中调用parse_all_page()函数。
最后一行生成文件代码中,参数mode='a'可以不用设置,使用mode='w'也可以。encoding='utf_8_sig'一定要设置,否者csv文件会乱码。
def parse_all_page(num, offset):
url1 = 'https://www.zhipin.com/c101280100/h_101280100/?query=数据分析师&page='+str(offset)+'&ka=page-'+str(offset) # 广州
url2 = 'https://www.zhipin.com/c101280600/h_101280600/?query=数据分析师&page='+str(offset)+'&ka=page-'+str(offset) # 深圳
url3 = 'https://www.zhipin.com/c101010100/h_101010100/?query=数据分析师&page='+str(offset)+'&ka=page-'+str(offset) # 北京
url4 = 'https://www.zhipin.com/c101020100/h_101020100/?query=数据分析师&page='+str(offset)+'&ka=page-'+str(offset) # 上海
urldict = {'1':url1, '2':url2, '3':url3, '4':url4}
html = get_one_page(urldict[str(num)])
parse_one_page(html)
if __name__ == '__main__':
for j in range(1, 5):
for i in range(1,11):
parse_all_page(j, i)
file = pd.DataFrame(result_all, columns=['公 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









