







作为一名没有linux经验的计算机小白,在搭建hadoop平台时的确费了不少的功夫,再次要感谢我同门的师兄,那么多弱智的问题都回答我了,大约花了3天的时间才搭建了hadoop平台,并且成功运行了著名的wordcount的程序。下面就我所遇到的问题进行总结,当然一些涉及到的知识我也会搬上来滴~~
首先是版本问题,hadoop版本不同,安装方式差别也是有的,不要把各个版本的方法沦为一谈。下面是hadoop2.6版本的安装方法,伪分布的。
http://blog.csdn.net/stark_summer/article/details/43484545
在配置环境时需要为hadoop操作建立群组,在这个群组中创建用户,并把hadoop内文件的权限赋予给这个群组。
http://blog.csdn.net/cuker919/article/details/7595061
groupadd hadoop //创建hadoop的工作组
useradd -g hadoop hadoop//新建hadoop用户,并将这个用户添加到hadoop的群组中。
另外在root权限下创建的用户hadoop,但是很多时候hadoop自身的权限很小,所以要把hadoop加入到sudoers中,让普通用户hadoop具有root权限
http://blog.163.com/qqwmail@126/blog/static/2179665201071244722739/
在/etc/sudoers 有可以sudo的所有用户,vim 打开就可以看到
root ALL=(ALL) ALL//原有的
hadoop ALL=(ALL) ALL//添加这一句就可以了,这时普通用户hadoop也就有了root的所有权限
这里捎带说一下vim的用法,毕竟自己是linux的小白,就给自己做个笔记。
vim 文件名
i:进入到insert的模式,可以插入、删除,编辑好了,按esc退出该模式,敲键盘:输入wq!保存并退出,如果不保存,输入:q!
然后我们就可以使用hadoop用户下载hadoop2.6.2,安装了。
安装的时候就可以参考我开篇附上的那条连接,提几点注意吧!
这些配置文件的路径基本上都在hadoop2.6.2下面的etc/hadoop文件夹下。
1,配置core-site.xml
配置hdfs的文件路径,这里呢我的配置如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.75.137:9999</value>//这里尽量不要写localhost,把虚拟机的ip写上,否则在myeclipse的连接是可能会出现问题
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹,在前期的时候就创建了,写自己的临时文件夹的路径</description>
</property>
</configuration>
mapreduce-site.xml配置如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>192.168.75.137:8888</value>//这里也要写虚拟机的ip地址,端口号不要用50010
</property>
</configuration>
这里小白刚开始不知道,随口给job.tracker起了个50010,然后发现datanode一直都无法启动,并不是与namenode的cluserID不一致的问题,而是ip地址并占用,之后才发现,原来,datanode的端口号就是50010,这里附上一些资料
http://www.cnblogs.com/sunxucool/p/3957407.html
当然安装jdk,安装ssh等这都是非常必要的。
jdk的安装,这里也有详细资料
http://jingyan.baidu.com/article/c33e3f48a3365dea15cbb5c9.html
sudo chkconfig --level 2345 sshd on//ssh的自启动
也可以重启sshd服务
/etc/init.d/sshd restart
netstat -tl //检测ssh的状态 把这些都配置好了就可以启动hadoop了。
sbin/start-all.sh//所有的都启动
sbin/start-dfs.sh//启动文件系统
jps//查看是否启动成功,如果有namenode、dataname还有manager就说明启动成功了。启动成功:
5799 NodeManager
5502 ResourceManager
13355 Jps
9286 NameNode
10589 DataNode
9571 SecondaryNameNode
在之后还有可能出现datanode 或者是namenode启动不起来的情况,慢慢来说。
如果成功的话就可以用myeclipse连接了。我用的是myeclipse10,这里有一个插件,可以百度一下
hadoop-eclipse-plugin-2.6.0,可以自己下载也可以自己打包,放在myeclipse10的安装路径下
C:\Users\Administrator\AppData\Local\MyEclipse\MyEclipse 10\dropins
我是安装在这里了,但是找到MyEclipse 10 文件夹下的dropins文件夹,放下面就可以了。
之后可以参考这篇连接
http://my.oschina.net/u/570654/blog/112780?fromerr=Z04ryf20
注意两点,在配置HDFS的location时
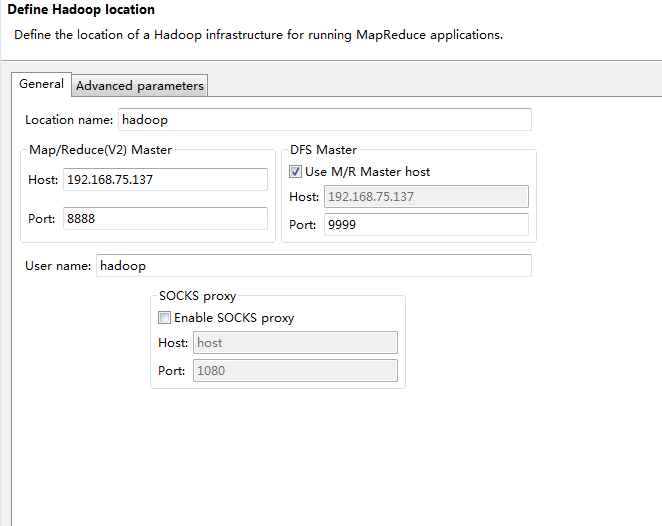
一定要和core-site.xml 和mapreduce-site.xml的配置时匹配的,ip地址端口号都一致,一致,一致,重要的事情说三遍啊~~。
另外的一个选项卡Advanced parameters比较重要的就是namenode的路径以及datanode 的路径了。
finish之后,如果成功就可以创建文件了,这里介绍几个HDFS的命令
这些是在Hadoop HDFS的文件系统上用
hadoop fs --help//可以查看用法
hadoop fs mkdir /user //创建目录user
hadoop fs mkdir /user/file //在目录user下创建fiel
hadoop fs mkdir /user/file/input //在目录user/fiel/input
hadoop fs ls /user/file/input //查看这个路径下的文件
hadoop fs -rm -r /user/file/input//删除路径下的input
hadoop fs -put file1.txt /user/file/input//将本地上传至hdfs上
hadoop jar /usr/local/hadoop/hadoop-2.6.2/share/hadoop/mapreduce/example.jar wordcount /user/file/input /user/file/input//将自带的mapreduce 的jar 处理input中的数据,也就是file1.txt,处理后放到指定路径下的output文件夹下,这里的output文件夹是自动生成的,如果自己创建好,可能就会报已存在的错误。
hadoop fs -cat /user/file/output/part-r-00000/读取处理后的数据,这里我们不用建立output的文件夹,会自动生成,将处理后的数据放入
rm -rf 文件夹名//一般的linux命令,删除文件夹及其里面的所有文件的时候使用如果连接不上,主要有下面的几个方向来考虑,参考
防火墙未关闭,我们应该关闭上
暂时关闭
service iptables stop
永久关闭
chkconfig iptables off
查看防火墙状态
iptables -l
service iptables status
http://www.centoscn.com/CentOS/help/2015/0708/5813.html
是端口配置,之前提到的在core-site.xml、mapreduce-site.xml与hdfs的location设置的不一致,无论是core-site.xml、mapreduce-site.xml还是location的设置中都不要写localhost ,而写成虚拟机linux系统的Ip地址。
最后要说的就是如果在上传数据,这里就是向input上传file1.txt文件中出现了不存在dataname的情况,使用jps查看发现没有datanode,也就是说明datanode 未启动,我们就需要重新启动。在sbin/下
hadoop-daemon.sh start namenode
hadoop-daenon.sh start datanodehttp://www.ithao123.cn/content-4582668.html
http://www.tuicool.com/articles/fQJj63
如果是由于格式化两次namenode倒是的与datanode的cluserID不一致,可以进行修改
./hadoop namenode -format//格式化
修改在之前创建的用来存储namenode和datanode 的路径下,修改下面的VERSION文件里的clusterID一致即可。
最后附上一些比较有用的链接吧~~
http://blog.csdn.net/yonghutwo/article/details/9206059
http://blog.csdn.net/ubuntu64fan/article/details/7744487
http://www.cnblogs.com/tankaixiong/p/4177832.html
http://www.tuicool.com/articles/2y6B3uA
http://blog.sina.com.cn/s/blog_4c248c5801014nd1.html
http://www.ithao123.cn/content-4582668.html
最后写写自己的小感悟:我们以为原地踏步走是没有进步,其实那只是积累的过程,一旦找到突破口我们就可以迈出一大步,无论是工作还是学习这都仅仅是开始~~















 9640
9640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









