



 本文介绍了缓存的基本概念,包括缓存命中率、基于空间、容量、时间和JAVA对象引用的回收策略。探讨了JAVA缓存的四种类型:堆缓存、堆外缓存、磁盘缓存和分布式缓存,以及常见的缓存使用模式。内容涵盖了缓存对系统性能提升的重要性,以及在实际应用中的选择和优化。
本文介绍了缓存的基本概念,包括缓存命中率、基于空间、容量、时间和JAVA对象引用的回收策略。探讨了JAVA缓存的四种类型:堆缓存、堆外缓存、磁盘缓存和分布式缓存,以及常见的缓存使用模式。内容涵盖了缓存对系统性能提升的重要性,以及在实际应用中的选择和优化。
应用级缓存学习
前言
在整个系统中,数据的读写是必须存在的,只是量少量多的差异,当数据读写量多时,不采用缓存的话,直接去读取数据,会当值前端获取数据缓慢,甚至人多访问时,崩盘。而这个时候,就要合理的运用缓存。
一、缓存是什么?
缓存可以理解为让数据更接近于使用者,目的是让访问速度更快。工作机制就是先从缓存中读取数据,如果没有,再从数据库中读取数据。众所周知,读写数据库是很耗时间的。举个例子就是京东上购买京东物流的商品,一般当天购买,第二天就能送达,那么是为什么呢。因为他们再各地都有份仓库,如果你买的东西当地仓库就有,是不是就隔天就能送达了,这分库就相当于缓存,数据库就相当于总部。
二、基本概念介绍
1.缓存命中率
缓存命中率时从缓存中读取数据的次数于总读取次数的比率,命中的越高越好。这是一个非常重要的监控指标,如果做缓存,则应通过监控这个指标来看缓存是否工作良好。
2.缓存回收策略
基于空间
基于空间指缓存设置了存储空间,如果设置为10MB,当达到存储空间上限时,按照一定的策略移除数据。
基于容量
基于容量指缓存设置了最大大小,当缓存的条目超过最大大小时,按照一定的策略移除旧数据。
基于时间
TTL(Time To Live):存活期,即缓存数据从创建开始直到到期的一个时间段(不管在这个时间段内有没有被访问,缓存数据都将过期,然后拉取新的数据作为缓存,一定量的保证数据的一致性)。
TTI(Time To Idle):空闲期,即缓存数据多久没被访问后移除缓存的时间。
基于JAVA对象引用
在这里介绍几个概念。
JVM:Java Virtual Machine,Java虚拟机。JVM是JRE的一部分。它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java语言最重要的特点就是跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。所以,JAVA虚拟机JVM是属于JRE的,而现在我们安装JDK时也附带安装了JRE(当然也可以单独安装JRE)。
JVM内存区域划分:粗略分来,JVM的内部体系结构分为三部分,分别是:类装载器(ClassLoader)子系统,运行时数据区,和执行引擎。
类装载器:每一个Java虚拟机都由一个类加载器子系统(class loader subsystem),负责加载程序中的类型(类和接口),并赋予唯一的名字。
运行时数据区:主要包括:方法区,堆,Java栈,PC寄存器,本地方法栈。
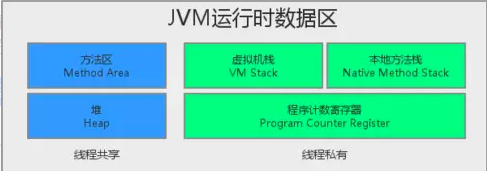
方法区域:方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、isInterface等方法来获取信息时,这些数据都来源于方法区域,同时方法区域也是全局共享的,在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。
堆:它是JVM用来存储对象实例以及数组值的区域,可以认为Java中所有通过new创建的对象的内存都在此分配,Heap中的对象的内存需要等待GC进行回收。
栈:又名JavaStack,虚拟机只会直接对Javastack执行两种操作:以帧为单位的压栈或出栈。
帧:局部变量区(包括方法参数和局部变量,对于instance方法,还要首先保存this类型,其中方法参数按照声明顺序严格放置,局部变量可以任意放置),操作数栈,帧数据区(用来帮助支持常量池的解析,正常方法返回和异常处理)。
程序计数器:每一个线程都有它自己的PC寄存器,也是该线程启动时创建的。PC寄存器的内容总是指向下一条将被执行指令的饿地址,这里的地址可以是一个本地指针,也可以是在方法区中相对应于该方法起始指令的偏移量。
JVM垃圾回收:简称GC,将内存中不再被使用的对象进行回收,GC中用于回收的方法称为收集器,由于GC需要消耗一些资源和时间,Java在对对象的生命周期特征进行分析后,按照新生代、旧生代的方式来对对象进行收集,以尽可能的缩短GC对应用造成的暂停。
执行引擎:解释,即时编译。
软引用:如果一个对象是软引用,那么当JVM堆内存(后面介绍)不足时,垃圾回收期可以这些对象。软引用适合用来做缓存,从而当JVM堆内存不足时,可以回收这些对象腾出一些空间供强引用对象使用,从而避免OOM(Out Of Menmory Error,内存溢出)。
强引用:默认情况下,对象采用的均为强引用(这个对象的实例没有其他对象引用,GC时才会被回收)
软引用:软引用是Java中提供的一种比较适合于缓存场景的应用(只有在内存不够用的情况下才会被GC)
弱引用:在GC时一定会被GC回收
虚引用:由于虚引用只是用来得知对象是否被GC
回收算法
比较常见的策略如下。
FIFO(First In First Out):先进先出算法,先放入缓存则先被移除。
LRU(Least Recently Used):最近最少使用算法,使用时间距离现在醉酒的那个被移除。
LFU(Least Frequently Used):最不常用算法,一定时间段被使用次数最少的那个被移除。
正常情况下,使用LRU的策略居多。
3.JAVA缓存类型
堆缓存
使用JAVA堆内存来存储缓存对象。优点就是访问很快。缺点就是缓存内容过多是,GC的时间会更长,并且重启时,数据会丢失。
堆外缓存
个人理解为静态文件。优点可以减少GC的时间,同时支持更大的缓存空间。缺点就是会比堆缓存速度慢一点。重启时一样会数据丢失。
磁盘缓存
即缓存数据存储到磁盘上,优点就是重启时不会丢失。缺点相对于堆缓存于堆外缓存会更慢一点。
分布式缓存
共享性缓存,并且能读写分离,让读写互不影响,同时容量能扩大。
4.缓存使用模式
Cache-Aside:即业务代码围绕着Cache写,是有业务代码直接维护缓存。
Cache-As-SoR:把Cache看作为SoR(数据库操作),所有操作都是对Cache进行,然后Cache再委托给SoR进行真是的读/写。
Read-Through:业务代码首先调用Cache,如果Cache不命中有Cache回源到SoR,而不是业务代码。
Write-Through:被称为穿透写模式/直写模式–业务代码首先调用Cache写数据,然后由Cache负责写缓存和写SoR,而不是由业务代码。
Write-Behind:也叫Write-Back,我们称之为回写模式。不同于Write-Through是同步写SoR和Cache,该模式是异步写。异步之后可以实现批量写、合并写、延时于限流。
Copy Pattern:由两种Copy Pattern。Copy-On-Read(在读时复制)和Copy-On-Write(在写时复制)。
总结
每天学习一点,每天成长一点,虽然概念现在用不上,但是碰到了就很有用了。
引用:https://blog.csdn.net/qq_41701956/article/details/80020103

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









