







一、原理
请移步到《netty的内存池设计》
二、PoolChunk与PoolSubPage
2.1 PoolChunk
2.1.1 简介
PoolChunk表示一个内存块,默认16M,用于管理分配内存,以下为PoolChunk的类图
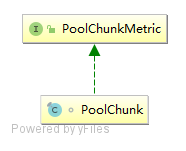
- PoolChunkMetric:接口,usage方法用于获取PoolChunk的使用率;chunkSize方法返回PoolChunk的大小;freeBytes方法返回剩余可用内存
2.1.2 字段说明
// 值为 31,用于计算log2N的值指数值
private static final int INTEGER_SIZE_MINUS_ONE = Integer.SIZE - 1;
//内存池管理,用于根据分配内存的类型和PoolChunk的内存占用率分给内存
final PoolArena<T> arena;
//对于直接内存分配,这个字段类型为ByteBuffer
//对于堆内存分配,这个字段类型为byte[]
final T memory;
//标识是否启用池化管理内存
final boolean unpooled;
//指定memory的偏移,默认是从0开始
final int offset;
//用于记录大顶堆二叉树,元素值为层数,在某个节点被分配出去后,对一个下标的值将会被设置为12
private final byte[] memoryMap;
//和memoryMap一样用于记录大顶堆二叉树,元素值为层数
//但是它的值不会因为内存的分配而改变,这样我们可以通过下标找回原来的值
private final byte[] depthMap;
//当用户申请一个小于8k的内存时,netty会从平衡二叉树中分配一个8k的内存,然后
//封装成 PoolSubpage 存到这个数组中
private final PoolSubpage<T>[] subpages;
//这个值等于 ~(pageSize - 1) ,pageSize是一个2的n次幂的值,所有的bit位上只有一个1,这个1在第14个bit位上,减1后,低13位全部变成1,高19位全是零
//然后取反,那么高19位全是1,低13位全是0,这样任何比pageSize小的数与 subpageOverflowMask 相与都会等于零
private final int subpageOverflowMask;
//pageSize默认为8k-》8192
private final int pageSize;
//页偏移,用于计算层数,这个值为log2(pageSize),pageSize为8k,所以pageShifts为13
private final int pageShifts;
//二叉树的深度,默认是11,层数从0开始
private final int maxOrder;
//PoolChunk的大小,默认是 1 << 24 = 16M
private final int chunkSize;
//log2(chunkSize) = 24
private final int log2ChunkSize;
//表示这个16M内存最大能够分配多少个8k,很显然是 (1 << 24) / (1 << 13) = 1 << 11 = 2048个
private final int maxSubpageAllocs;
/** Used to mark memory as unusable */
//当二叉树中一个节点被分配出去之后,这个节点的值就会被设置为 unusable = 12
private final byte unusable;
// Use as cache for ByteBuffer created from the memory. These are just duplicates and so are only a container
// around the memory itself. These are often needed for operations within the Pooled*ByteBuf and so
// may produce extra GC, which can be greatly reduced by caching the duplicates.
//
// This may be null if the PoolChunk is unpooled as pooling the ByteBuffer instances does not make any sense here.
//用于缓存ByteBuffer对象,有时用户会希望将ByteBuf转化成JDK的ByteBuffer对象
//为了节省创建ByteBuffer的开销,这里做个缓存
private final Deque<ByteBuffer> cachedNioBuffers;
//当前PoolChunk还剩余多少内存可分配
private int freeBytes;
// PoolChunkList 是一个集合类,用于集合PoolChunk
//内部使用链表实现,主要用于PoolArean,区分不同使用率的PoolChunk
//相同使用率的PoolChunk将被PoolChunkList综合在一起
PoolChunkList<T> parent;
//前一个PoolChunk,用于PoolChunkList
PoolChunk<T> prev;
//后一个PoolChunk,用于PoolChunkList
PoolChunk<T> next;
2.1.3 构造器
PoolChunk(PoolArena<T> arena, T memory, int pageSize, int maxOrder, int pageShifts, int chunkSize, int offset) {
//指定了二叉树深度,页大小,页偏移,那么一定是需要池化的
unpooled = false;
//指定PoolArean,内存池管理,后面会讲
this.arena = arena;
//如果是直接内存,这里memory的类型为ByteBuffer,如果是堆内存,那么这个memory的类型为byte[]
this.memory = memory;
//指定页大小
this.pageSize = pageSize;
//指定页偏移,用于计算层数
this.pageShifts = pageShifts;
//指定二叉树深度
this.maxOrder = maxOrder;
//指定PoolChunk内存大小
this.chunkSize = chunkSize;
//指定分配内存时,在memory中的偏移
this.offset = offset;
//二叉树某个节点被分配出去后,用12标记
unusable = (byte) (maxOrder + 1);
// 24
log2ChunkSize = log2(chunkSize);
//用于判断用户请求内存是否大于pageSize
subpageOverflowMask = ~(pageSize - 1);
//初始时,PoolChunk可用的剩余内存为16M
freeBytes = chunkSize;
assert maxOrder < 30 : "maxOrder should be < 30, but is: " + maxOrder;
//一个16M的PoolChunk最多能分配多少个8K的内存
maxSubpageAllocs = 1 << maxOrder;
// Generate the memory map.
//将二叉树映射到一个数组中,需要多长,2的12次幂
memoryMap = new byte[maxSubpageAllocs << 1];
depthMap = new byte[memoryMap.length];
//从1开始
int memoryMapIndex = 1;
for (int d = 0; d <= maxOrder; ++ d) { // move down the tree one level at a time
//计算当前层有多少个节点
int depth = 1 << d;
//给当前层上的所有节点值赋值(当前层数)
for (int p = 0; p < depth; ++ p) {
// in each level traverse left to right and set value to the depth of subtree
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
//初始化PoolSubPage数组
subpages = newSubpageArray(maxSubpageAllocs);
//初始化ByteBuffer缓存双端队列
cachedNioBuffers = new ArrayDeque<ByteBuffer>(8);
}
2.2 PoolSubPage
2.2.1 简介
PoolSubPage用于分配小于8k的内存,整个PoolSubPage大小为8k,内部按照tiny或者small继续划分成n份,用一个long[]类型的bitMap进行记录分配与释放
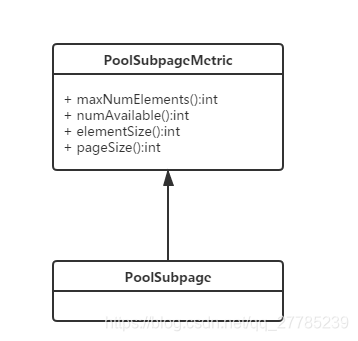
- PoolSubpageMetric
//pageSize默认是8k,没份16字节,那么这个方法返回 8k / 16 = 512
int maxNumElements();
//返回还未被分配的份数
int numAvailable();
//返回每份字节大小
int elementSize();
//返回每个页的大小,默认是8k
int pageSize();
2.2.2 字段说明
//表示当前PoolSubPage分配的8k来自哪个PoolChunk
final PoolChunk<T> chunk;
//当前分配的8k对应的二叉树节点在memoryMap数组中的下标
private final int memoryMapIdx;
//在PoolChunk.memory的开始偏移位置
private final int runOffset;
//页大小,默认8k
private final int pageSize;
//用于记录内存申请与释放
private final long[] bitmap;
//前驱节点
PoolSubpage<T> prev;
//后继节点
PoolSubpage<T> next;
//是否需要被销毁
boolean doNotDestroy;
//每份大小
int elemSize;
//pageSize / elemsize,表示pageSize按elemsize能够分成多少份
private int maxNumElems;
//bitMap数组的长度
private int bitmapLength;
//每次分配掉一份内存之后,会预计算下一个可用的bit位
private int nextAvail;
//剩余可分配的份数
private int numAvail;
三、内存的分配
//buf还未初始化,没有设置偏移,容量等属性
//reqCapacity为用户真实申请的内存大小
//normCapacity为最接近reqCapacity的一个2的n次幂的值
boolean io.netty.buffer.PoolChunk#allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
final long handle;
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
//申请大于8k的内存
handle = allocateRun(normCapacity);
} else {
//申请小于8k的内存
handle = allocateSubpage(normCapacity);
}
//没有申请到内存,返回分配失败
if (handle < 0) {
return false;
}
//从ByteBuffer缓存队列中获取一个
ByteBuffer nioBuffer = cachedNioBuffers != null ? cachedNioBuffers.pollLast() : null;
//初始化PooledByteBuf
initBuf(buf, nioBuffer, handle, reqCapacity);
return true;
}
以上方法首先会判断用户申请的内存是否大于8k,大于8k的从二叉树中直接分配,小于8k的除了会从二叉树中分配置之外,还会做进一步的处理,申请到内存之后对 PooledByteBuf 进行初始化
3.1 分配大于8k的内存
我们先简单回顾一下在《netty的内存池设计》
博文中提到的关于大于8k内存的申请与释放原理,首先netty会构建一个大顶堆的平衡二叉树。

每个节点表示的内存大小为父节点的一半,总共11层,分配内存时将对应节点的值设置为12,释放时将对应节点的值恢复即可,下面我们来分析下具体的代码实现。
private long io.netty.buffer.PoolChunk#allocateRun(int normCapacity) {
//计算当前需要分配的内存所在二叉树的层数
//假设我们需要分配一个9kb的内存,那么最接近9kb的2的n次幂的值为16k
// 11 - (14 - 13) = 10
int d = maxOrder - (log2(normCapacity) - pageShifts);
//通过二叉树查找能够分配对应内存的节点,返回其在memoryMap数组中的下标
int id = allocateNode(d);
if (id < 0) {
return id;
}
//计算剩余可用内存大小
freeBytes -= runLength(id);
return id;
}
上面有一段公式 maxOrder - (log2(normCapacity) - pageShifts) 这个公式是用于计算某个内存大小对应二叉树中的层数,为什么这么计算呢?
首先我们知道8kb所在的层数是第11层,那么假设我要申请4M的内存,这个4M所在层数与8kb相差多少呢?是不是相差 log2(4M) - log2(8k),既然知道了差值,那么用11减去
这个差值就得到了4M所在的层数。
下面我们继续分析下netty是如何从二叉树中查找可分配的节点的
private int io.netty.buffer.PoolChunk#allocateNode(int d) {
//从1开始
int id = 1;
// 1 << d 表示第 d 层第一个节点在memoryMap中的下标,由于这个下标值是一个2的d次幂的值,那么其所有bit位只有第d+1位是1
//取负值之后,低d位全部为0,d位以上全是1,等价于 ~((1 << d) - 1)
int initial = - (1 << d); // has last d bits = 0 and rest all = 1
//从memoryMap中获取指定下标的值
byte val = value(id);
//如果根节点的值就已经大于d了,说明剩余内存无法分配
if (val > d) { // unusable
return -1;
}
//如果节点值小于d,那么表示有足够的容量分配
//注意这里有一个表达式 (id & initial) == 0 ,这个表达式用于判断当前id是否小于第 d 层第一个节点在 memoryMap 的下标
while (val < d || (id & initial) == 0) { // id & initial == 1 << d for all ids at depth d, for < d it is 0
//左子节点,d层的第一个节点的下标为2的d次方,下一层也就是子节点那层的第一个节点的下标为2的d+1次方,是d层第一
//个节点的2倍,现假设d层的任意节点r的位置离d层第一个节点距离为n,那么r的下标为2^d+n,因为是完全二叉树,
//r这一层前面n个节点都会两个子节点,所以r对应的左子节点所在层离第一个节点的距离为2n,那么就有2^(d+1)+2n
//正是其父节点的2倍
id <<= 1;
val = value(id);
if (val > d) {
//右子节点,对于左子节点,其所在memoryMap的下标一定是一个偶数(除根节点外每层的第一个节点的下标为2的d次幂
//的值),所以第一个bit是0,与1异或就相当于加1得到右子节点的下标,如果是右子节点异或一,那么得到就是左
//子节点的下标
id ^= 1;
val = value(id);
}
}
byte value = value(id);
assert value == d && (id & initial) == 1 << d : String.format("val = %d, id & initial = %d, d = %d",
value, id & initial, d);
//节点被分配之后,将对应节点值设置为12
setValue(id, unusable); // mark as unusable
//更新父节点的值
//(1)
updateParentsAlloc(id);
return id;
}
//(1)
private void io.netty.buffer.PoolChunk#updateParentsAlloc(int id) {
while (id > 1) {
//计算父节点的下标
int parentId = id >>> 1;
byte val1 = value(id);
byte val2 = value(id ^ 1);
//比较左右两个子节点的值,取最小值
byte val = val1 < val2 ? val1 : val2;
//用最小值更新父节点的值
setValue(parentId, val);
//继续往上更新
id = parentId;
}
}
按照以上方法我们用文字描述一遍,假设此时我们要分配一个3M的内存
- 将3M转换成最接近3M的2的n次幂的值–》4M
- 计算4M所在层数d–》maxOrder - (log2(4M) - log2(8k)) = 11 - (22 - 13) = 2
- 从根节点开始,从左子节点到右子节点进行遍历,比较每个节点上的值(存在memoryMap的层数)与2进行比较
- 左子节点的层数大于2,那么说明这个节点以下没有足够的内存分配,那么找到右节点R进行比较
- 右节点R的层数小于2,那么说明这个节点以下有足够的内存进行分配,那么继续比较右节点R的左子节点的层数,以此类推,直到找到等于2的那个节点并且这个节点所在数组
memoryMap的下标不能小于4M所在层数第一个节点在数组memoryMap中的下标,这是因为在分配了一个节点后,父节点的值由两个子节点的最小值决定,所以当父节点的值不等于
自身所在层数时,其值来源于子节点 - 找到层数为2的节点C后,将这个节点C的值修改为12,表示这个节点C已经被分配(以后分配的其他任何内存的层数都会小于等于11,所以这里标记成大于11的值都可以)
- 由于C被分配,那么这个C的父节点还剩下右节点可以分配,那么父节点就需要将值修改为右子节点的值,然后以此类推,直到根节点
具体的图解过程请移步到《netty的内存池设计》
3.2 分配小于8k的内存
简单回顾下我们在《netty的内存池设计》
中提到的关于小于8k内存分配的原理,netty将其分成了两大类,一类是tiny,另一类是small
tiny:
small:
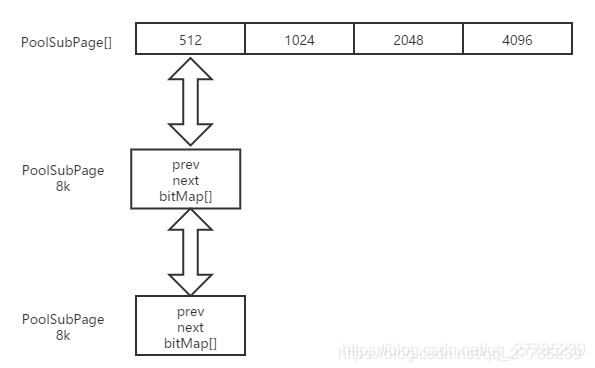
对于以上两种类型的内存分配,netty都维护了一个叫bitMap的long数组,拿tiny的第2号元素来举例,每个PoolSubPage总共8k,按照16字节划分成512份,bitMap中每个bit位
表示一份,那么需要8个long类型元素来才足够表示,分配内存的时候将bit位设置为1,释放时将bit位恢复为0,下面我们来分析下具体的代码实现
private long io.netty.buffer.PoolChunk#allocateSubpage(int normCapacity) {
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
//8k以下的内存被netty分成了两种类型,一种是tiny,另一种是small,其在PoolArean中表现为两个PoolSubPage数组
//它是由数组+链表构成的,头节点是一个空的PoolSubPage,不参与内存的分配,这段代码是获取其头节点,用于
//构建细粒度锁
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
int d = maxOrder; // subpages are only be allocated from pages i.e., leaves
synchronized (head) {
//从二叉树中获取一个8k的内存
int id = allocateNode(d);
if (id < 0) {
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
//计算剩余可用内存
freeBytes -= pageSize;
//计算在PoolSubpage[] subpages中的下标,如果使用不怎么高效的方式计算下标,会这么计算 |memoryMapIdx - maxSubpageAllocs| 取绝对值,但netty的
//计算方式为 memoryMapIdx ^ maxSubpageAllocs ,其中 maxSubpageAllocs 为2048,因为一个16M的内存最多只能分配2048个8k内存
//maxSubpageAllocs是一个2的n次幂的值,属于最后一层(第11层)的第一个节点在memoryMap中的下标,所以的bit位上只有第12位是1
//同是第11层的值大于2048的,他们的值只在12位以下变动,小于2048的也是在第12位以下的bit位发生变动,而2048第12位以下都是0,进行异或
//就是保存了第12位以下为1的变动
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
if (subpage == null) {
//runOffset方法用于计算分配内存在memory中的开始偏移
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
} else {
//初始化
subpage.init(head, normCapacity);
}
return subpage.allocate();
}
}
首先先从PoolArean中的tiny类型或者small类型PoolSubPage数组中获取一个头节点,用于加锁和插入新的节点,然后从二叉树中分配一个8k的内存,封装成PoolSubPage,然后
存入名为subpages的PoolSubPage数组中,其下标计算方式为 memoryMapIdx ^ maxSubpageAllocs ,为什么这么计算,为什么不直接 |memoryMapIdx - maxSubpageAllocs|
取绝对值?
其中 maxSubpageAllocs 为2048,因为一个16M的内存最多只能分配2048个8k内存maxSubpageAllocs是一个2的n次幂的值,属于最后一层(第11层)的第一个节点在memoryMap中
的下标,所以的bit位上只有第12位是1同是第11层的值大于2048的,他们的值只在12位以下变动,小于2048的也是在第12位以下的bit位发生变动,而2048第12位以下都是0,进
行异或就是保存了第12位以下为1的变动,位运算是计算机能够直接识别的操作方式,可以提高计算效率。
创建好PoolSubpage之后,还需要对其进行初始化
//head:链表头
//elemSize:对于tiny类型,这个值可以是 16,32,...,480,496。
//对于small类型的,这个值可以是512,1024,2049,4096
void io.netty.buffer.PoolSubpage#init(PoolSubpage<T> head, int elemSize) {
doNotDestroy = true;
this.elemSize = elemSize;
if (elemSize != 0) {
//计算按elemSize划分8k的份数
maxNumElems = numAvail = pageSize / elemSize;
//记录下一个可用bit位
nextAvail = 0;
//计算需要多少个Long来表示
bitmapLength = maxNumElems >>> 6;
//相当于对64求余,如果有余数,那么需要再加一个long来表示
if ((maxNumElems & 63) != 0) {
bitmapLength ++;
}
//初始化为0
for (int i = 0; i < bitmapLength; i ++) {
bitmap[i] = 0;
}
}
//将当前新创建的PoolSubPage加入到链表中
//(1)
addToPool(head);
}
//(1)
private void addToPool(PoolSubpage<T> head) {
assert prev == null && next == null;
prev = head;
next = head.next;
next.prev = this;
head.next = this;
}
初始化过程很简单,首先计算一个pageSize可以分成多少份,然后再计算需要多少个Long才足够表示对应的份数,最后将PoolSubPage加入到链表中。
下面我们来看看PoolSubPage的内存分配过程
long io.netty.buffer.PoolSubpage#allocate() {
if (elemSize == 0) {
return toHandle(0);
}
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
//获取下一个可用的bitmap索引
final int bitmapIdx = getNextAvail();
//除以64,确定可用bit为所在的bitMap数组的下标
int q = bitmapIdx >>> 6;
//对64求余,确定这个bit位在下标为q的long元素中的偏移
int r = bitmapIdx & 63;
assert (bitmap[q] >>> r & 1) == 0;
//将对应bit为设置为1,表示已经被分配
bitmap[q] |= 1L << r;
//如果当前PoolSubPage全部被分配出去了,那么将当前PoolSubPage从链表中移除
if (-- numAvail == 0) {
removeFromPool();
}
//将bitmapIdx左移到高32位
//(1)
return toHandle(bitmapIdx);
}
//(1)
private long io.netty.buffer.PoolSubpage#toHandle(int bitmapIdx) {
//将bitmapIdx左移到高32位,memoryMapIdx放在低32位
//0x4000000000000000L 暂时不知道用于干啥的,用了这个之后,要获取真实的bitmapIdx还得与上 0x3FFFFFFF
return 0x4000000000000000L | (long) bitmapIdx << 32 | memoryMapIdx;
}
上面一段代码首先先确定可用的下一个bit为索引,然后将对应bit位设置为1,表示已被分配,如果可用的份数全部分配完毕,那么将当前PoolSubPage从链表中移除。
下面再看下具体是怎么找到下一个可用的bit位的
private int io.netty.buffer.PoolSubpage#getNextAvail() {
int nextAvail = this.nextAvail;
//如果提前预读了下一个可用bit位索引,直接返回
if (nextAvail >= 0) {
this.nextAvail = -1;
return nextAvail;
}
return findNextAvail();
}
private int io.netty.buffer.PoolSubpage#findNextAvail() {
final long[] bitmap = this.bitmap;
final int bitmapLength = this.bitmapLength;
//遍历bitMap数组
for (int i = 0; i < bitmapLength; i ++) {
long bits = bitmap[i];
//被分配掉的bit为会被置为1,如果整个long元素被分配了,那么取反之后,它的值等于0
if (~bits != 0) {
return findNextAvail0(i, bits);
}
}
return -1;
}
private int io.netty.buffer.PoolSubpage#findNextAvail0(int i, long bits) {
//总份数
final int maxNumElems = this.maxNumElems;
//i表示遍历到的第几个long元素,然后乘以64,表示当前i对应的long元素的第一个bit为索引
final int baseVal = i << 6;
//遍历当前i对应的long元素的每个bit位
for (int j = 0; j < 64; j ++) {
//等于表示没有被分配
if ((bits & 1) == 0) {
//相当于 baseVal + j,难道 baseVal | j = baseVal + j?不是的,必须满足baseVal为1的bit位不会与j中为1的bit位进行位或
//很显然j是一个小于64 = 1 << 6的值,其为1的bit位在低6位上,而baseVal要么是零,要么就是 i << 6(i > 0),其为1的bit位不会出现在低6位上
int val = baseVal | j;
if (val < maxNumElems) {
return val;
} else {
break;
}
}
//移位
bits >>>= 1;
}
return -1;
}
遍历bitMap数组中的每个long类型的元素,然后判断其bit位是否都已经被分配出去了,如果没有,那么遍历其每个bit位,找到为零的那个bit,返回bit索引即可。
四、内存的释放
void io.netty.buffer.PoolChunk#free(long handle, ByteBuffer nioBuffer) {
// (int)handle,memoryMapIdx存在与handle的低32位
int memoryMapIdx = memoryMapIdx(handle);
//高32
int bitmapIdx = bitmapIdx(handle);
//bitmapIdx不为零,那么表示当前要释放的是小于8k的内存
if (bitmapIdx != 0) { // free a subpage
//subpageIdx方法用于计算对应PoolSubPage的下标
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage != null && subpage.doNotDestroy;
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
//在PoolArean中判断分配类型,tiny还是small,然后获取对应PoolSubPage的头节点
PoolSubpage<T> head = arena.findSubpagePoolHead(subpage.elemSize);
synchronized (head) {
//bitmapIdx & 0x3FFFFFFF 还原真实的bit索引
//释放
if (subpage.free(head, bitmapIdx & 0x3FFFFFFF)) {
return;
}
}
}
//runLength方法用于计算对应memoryMapIdx表示的内存大小
freeBytes += runLength(memoryMapIdx);
//将二叉树对应的节点恢复为原来的层数值,层数值从deptMap数组中获取
setValue(memoryMapIdx, depth(memoryMapIdx));
//更新父节点的值
updateParentsFree(memoryMapIdx);
//缓存nioBuffer
if (nioBuffer != null && cachedNioBuffers != null &&
cachedNioBuffers.size() < PooledByteBufAllocator.DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK) {
cachedNioBuffers.offer(nioBuffer);
}
}
如果是小于8k的内存释放,那么需要先将PoolSubPage中bitMap对应的bit为重置为0,然后再释放二叉树树中的节点
下面便是PoolSubPage的释放方法
boolean io.netty.buffer.PoolSubpage#free(PoolSubpage<T> head, int bitmapIdx) {
if (elemSize == 0) {
return true;
}
//计算bit索引为在bitMap数组中的下标
int q = bitmapIdx >>> 6;
//计算指定q元素中long的bit位索引
int r = bitmapIdx & 63;
assert (bitmap[q] >>> r & 1) != 0;
//将对应的bit位重置为0
bitmap[q] ^= 1L << r;
//记录将当前释放的bit位索引,下次分配内存时可快速分配
setNextAvail(bitmapIdx);
//递增可用份数
if (numAvail ++ == 0) {
//重新加入链表
addToPool(head);
return true;
}
if (numAvail != maxNumElems) {
return true;
} else {
// Subpage not in use (numAvail == maxNumElems)
//只剩最后一个PoolSubPage,不会被移除,netty需要留一个头节点构建链表
if (prev == next) {
// Do not remove if this subpage is the only one left in the pool.
return true;
}
// Remove this subpage from the pool if there are other subpages left in the pool.
doNotDestroy = false;
//从链表中移除
removeFromPool();
return false;
}
}
PoolSubPage的释放很简单,就是将原来分配了内存的bit位由1变回0
五、PooledByteBuf的初始化
分配好内存之后,需要初始化PooledByteBuf,告诉它,它所能管辖的内存范围是memory中的哪一部分
void io.netty.buffer.PoolChunk#initBuf(PooledByteBuf<T> buf, ByteBuffer nioBuffer, long handle, int reqCapacity) {
// (int) handle
int memoryMapIdx = memoryMapIdx(handle);
// handle >>> 32
int bitmapIdx = bitmapIdx(handle);
if (bitmapIdx == 0) {
byte val = value(memoryMapIdx);
assert val == unusable : String.valueOf(val);
//8k以上内存的初始化
buf.init(this, nioBuffer, handle, runOffset(memoryMapIdx) + offset,
reqCapacity, runLength(memoryMapIdx), arena.parent.threadCache());
} else {
//8k以下内存的初始化
initBufWithSubpage(buf, nioBuffer, handle, bitmapIdx, reqCapacity);
}
}
PooledByteBuf的初始化无非就是设置其负责memory的内存范围,我们重点研究一下runOffset方法和runLength方法
runLength方法用于计算对应id表示的内存大小
private int runLength(int id) {
// represents the size in #bytes supported by node 'id' in the tree
//depth(id)返回层数,比如第11层
//log2ChunkSize的值为24
//我们计算层数的时候是这么计算的
// 11 - (log2(x) - log2(8k)) 那么反过来我们要求x ==》 1 << (11 - depth(id) + log2(8k)) ==》 1 << (11 - depth(id) + 13) ==> 1 << (24 - depth(id))
return 1 << log2ChunkSize - depth(id);
}
1 << log2ChunkSize - depth(id)用于计算当前id对应层数的内存大小,其中log2ChunkSize的值为24,当初我们计算层数的时候是这么计算的 11 - (log2(x) - log2(8k))
现在反过来我们要求x的值 ==》 1 << (11 - depth(id) + log2(8k)) ==》 1 << (11 - depth(id) + 13) ==> 1 << (24 - depth(id))
runOffset方法用于计算内存偏移
private int io.netty.buffer.PoolChunk#runOffset(int id) {
// represents the 0-based offset in #bytes from start of the byte-array chunk
int shift = id ^ 1 << depth(id);
return shift * runLength(id);
}
depth(id)获取id对应的层数,记为L
1 << L 用于计算第L层第一个节点在memoryMap的下标,记为memoryIdx,那么id与memoryIdx相差 id - memoryIdx,但是netty并没有直接这样计算,它是通过 id ^ memoryIdx
位操作计算的,为什么可以这样计算?
前面也提到过,要满足公式 |a - b| = a ^ b,那么a为1的bit位不能和b为1的bit位发生异或操作,由于memoryIdx是一个2的n次幂的值,那么其低n位都是0,而id与memoryIdx
处于同一L层,那么id的值与memoryIdx相比,其发生变化的bit位都在低n位,所以可以直接通过异或的方式获取其偏移位置
六、总结
就是其原理的总结:《netty的内存池设计》

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









