










1、SkipSNN: Efficiently Classifying Spike Trains with Event-attention
全文总结:本文介绍了一种名为SkipSNN的模型,用于对稀疏事件序列进行分类。传统的神经网络在处理这种类型的信号时存在计算量大、功耗高等问题,而SkipSNN通过引入事件注意力机制和动态选择性更新突触权重的方式,能够有效地减少计算量并提高分类准确率。实验结果表明,SkipSNN在各种神经形态学任务中均表现出比现有最佳SNN更高的计算效率和分类精度。
- 文章研究背景和要解决的问题挑战
本文的研究背景是针对SNN在处理稀疏信号时存在的计算复杂度高的问题。同时,由于SNN的基本机制忽略了噪声问题,使得其分析稀疏事件序列时需要大量的计算资源和高能耗。因此,本文提出了一种名为SkipSNN的方法来提高SNN的分类准确性和效率。具体来说,SkipSNN通过引入事件关注机制,使SNN能够动态地突出原始稀疏事件序列中的有用信号,并学习跳过膜电位更新和缩短计算图的有效大小,从而有效地过滤掉噪声并降低计算成本。实验结果表明,SkipSNN比其他最先进的SNN模型具有更好的计算效率和分类准确性。
- 具体实现
该论文提出了一种名为SkipSNN的新颖神经网络架构,用于处理时间序列数据中的分类问题。与传统的SNN不同的是,SkipSNN引入了一个新的控制器神经元,它可以根据输入的时间序列动态地决定是否进入唤醒状态,并且可以跳过一些时间步长的更新以减少计算成本。具体来说,SkipSNN将所有的脉冲都连接到控制器上,在每个时间步长中,控制器会根据脉冲信号和第一层隐藏层的输出来决定是否发出一个二进制信号,从而控制模型在下一个时间步长中是否进入唤醒状态。如果进入唤醒状态,则模型会在下一个时间步长中使用输入;否则,模型将忽略这个时间步长的输入并继续等待有用的信号。
与传统的SNN相比,SkipSNN的主要改进在于引入了控制器神经元以及其对应的脉冲信号。这种设计使得模型能够动态地选择何时进入唤醒状态,从而避免了一些不必要的计算。此外,SkipSNN还使用模拟退火算法来进行优化,以克服传统梯度下降法在SNN中应用时所遇到的问题。
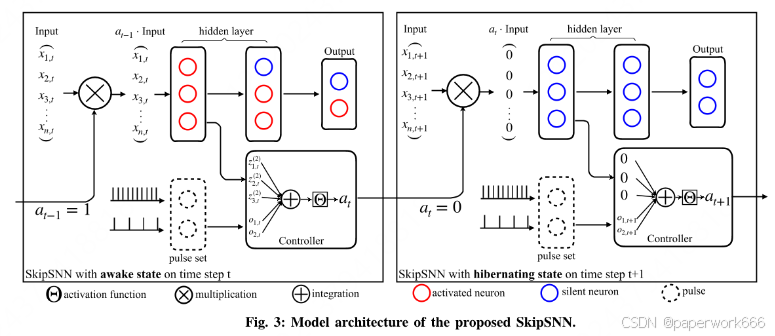
SkipSNN的目标是解决时间序列数据中的分类问题,同时尽可能地降低计算成本。通过引入控制器神经元和脉冲信号,SkipSNN能够在不牺牲准确性的情况下显著减少计算量。实验结果表明,相对于其他基准模型,SkipSNN在准确性和计算效率方面都有明显的优势。因此,SkipSNN是一种有潜力应用于实际场景中的高效分类器。
- 实验设计
本文主要介绍了基于时序跳过策略的神经网络模型SkipSNN在两个不同的神经形态数据集上的实验结果。该模型通过控制时间步长的更新率来实现对输入信号的有效过滤和分类,并且能够在保证准确性的前提下大幅降低计算成本。
首先,作者比较了不同模型在处理不同比例的时间步长更新情况下的性能表现。结果显示,固定跳过和随机跳过SNN随着唤醒状态的减少而迅速下降,而SkipRNN+SNN和SkipSNN则表现出更好的性能。特别是当每个模型只考虑少于20%的唤醒状态时,SkipRNN+SNN和SkipSNN仍然能够保持超过80%的准确性。相比之下,其他两种模型已经不再有效。此外,与SkipSNN相比,SkipRNN+SNN的分类性能稍差一些。
其次,作者展示了SkipSNN如何学习跳过含有噪声或无用信息的时间步长,并通过可视化其在控制器中的决策来展示它的能力。实验结果表明,SkipSNN能够有效地区分有用信号和噪声,并在睡眠状态下节省计算资源。
最后,作者将SkipSNN与其他传统的SNN、固定跳过SNN、随机跳过SNN以及SkipRNN+SNN进行了比较。结果显示,在N-MNIST数据集上,即使没有复杂的架构,SkipSNN和其他竞争对手的表现依然很好。相比于SNN,SkipSNN可以提供一半的计算成本,同时比固定跳过SNN、随机跳过SNN和SkipRNN+SNN具有更高的准确性。在DVS-Gesture数据集上,虽然SkipSNN的准确性略有下降,但它提供了超过10倍的速度提升,并且在相同的计算成本下仍具有更高的准确性。
- 总结
该论文提出了一种新的模型SkipSNN,通过引入事件注意力机制,在处理神经元信号时能够动态地强调有用的信息,并减少计算成本。在测试中,SkipSNN比固定和随机跳过更新的SNN表现更好,也优于基于SkipRNN的SNN适应版本。此外,该论文还提供了详细的实验结果和比较分析,证明了SkipSNN的有效性和优越性。
SkipSNN是一种结合了事件注意力机制的新型SNN模型,其主要创新点在于能够在处理神经元信号时动态地强调有用的信息,并减少计算成本。与传统的SNN相比,SkipSNN更加高效和准确,具有更好的分类性能。
- 局限性
该论文提出的SkipSNN模型为解决SNN的计算效率问题提供了一个新的思路,可以进一步应用于实际场景中的神经网络系统设计和优化。未来的研究方向包括如何更好地利用事件注意力机制来提高SNN的性能,以及如何将SkipSNN与其他深度学习技术相结合,实现更复杂的任务。同时,还需要进一步研究如何在不同硬件平台上实现SkipSNN,以满足实际应用的需求。
2、UniGAD: Unifying Multi-level Graph Anomaly Detection
全文总结:本文介绍了一种名为UniGAD的多级图异常检测框架,旨在联合检测节点、边和整个图级别的异常情况。该框架采用了最大Rayleigh商子图抽样算法(MRQSampler)将不同级别对象转化为子图上的任务,并通过理论证明最大化了子图的累积谱能量以保留最显著的异常信息。此外,还引入了一个新颖的GraphStitch网络来整合不同层次的信息并调整每个层次所需的共享量以及协调冲突的训练目标。实验结果表明,UniGAD在多个任务上优于专门针对单一任务的传统GAD方法和基于图提示的方法,并且具有良好的零样本任务转移性。
- 文章研究背景和要解决的问题挑战
这篇文章的研究背景是图结构数据中的异常检测问题,即如何识别出不寻常、偏离或可疑的对象。现有的方法通常只关注单个图对象类型(如节点、边缘、图等),而忽略了不同对象类型的内在联系。例如,在洗钱交易中,可能会涉及异常账户及其互动的更广泛社区。因此,本文提出了UniGAD,这是第一个联合检测节点、边缘和图形级别异常的统一框架。
UniGAD旨在解决以下问题挑战:
(1)多级格式的统一:UniGAD需要将不同级别的对象转换为子图任务,以便在一个统一的框架内处理多个级别的异常检测任务。
(2)跨级别信息整合:UniGAD需要整合来自不同级别的信息,以提高整体性能。为此,文章引入了图拼接网络(GraphStitch Network)来实现跨级别信息整合。
(3)端到端训练:UniGAD需要一种端到端的训练方法,以便在整个框架内学习多级异常检测任务。为此,文章开发了最大瑞利商子图采样器(MRQSampler)来实现这一目的。
总的来说,UniGAD的目标是在多级图异常检测场景下提供更好的性能和更强的可扩展性。
- 具体实现
该论文提出了一种名为UniGAD的统一多级图异常检测模型,包括三个主要组件:共享预训练无监督图卷积神经网络编码器、子图采样模块MRQSampler以及跨层信息融合网络GraphStitch Network。首先,通过共享预训练的无监督图卷积神经网络编码器来学习更加通用的节点表示。然后,使用子图采样模块MRQSampler将任务转换为图级任务,并利用谱采样技术从节点和边中提取包含最多异常信息的子图。最后,跨层信息融合网络GraphStitch Network用于整合不同层次的信息并调整不同层次之间的共享需求,以协调冲突的训练目标。
本文提出了一种名为UniGAD的统一多级图异常检测框架,用于在节点、边和图形级别上联合检测异常。该方法主要分为两个模块:
(1)最大瑞利商子图采样器(MRQSampler):这是一个用于统一不同级别的格式并转移每个级别上的对象到子图任务的算法。它通过最大化子图的瑞利商来保留最显著的异常信息,并证明了其有效性。
(2)图拼接网络(GraphStitch Network):这是一种新的网络架构,用于整合不同层次的信息,调整每个层次所需共享的数量,并协调冲突的训练目标。这有助于进一步统一多级训练。
这两个模块共同实现了UniGAD框架,能够同时处理多个级别的异常检测任务,并具有良好的零样本迁移性能。实验结果表明,UniGAD比专门针对单一任务的现有GAD方法和基于提示的多任务方法表现更好。
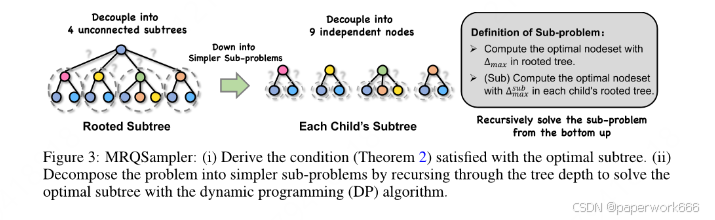
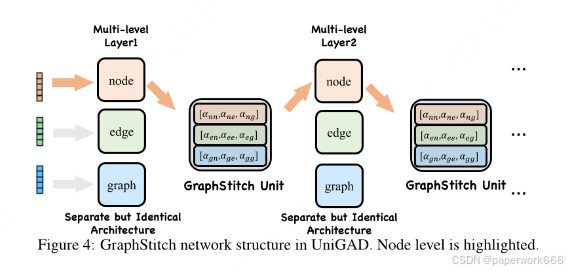
该论文解决了传统基于节点或边的异常检测方法存在的问题,即无法统一处理多级图异常检测问题,导致不同级别的效果难以协调。同时,该论文还针对传统方法中存在的缺乏有效子图采样技术和跨层信息融合策略等问题进行了改进,进一步提高了异常检测的效果。
- 实验设计
本文进行了四个方面的实验来评估UniGAD模型的性能和效率:
多级异常检测任务的比较实验(RQ1):作者在单图和多图数据集上比较了UniGAD与单一节点、边缘和图级别的方法,并使用AUROC、宏F1分数和AUPRC等指标进行评估。结果表明,UniGAD在几乎所有情况下都取得了最先进的性能,证明了它能够有效地统一不同层次的任务并增强每个任务的表现。
零样本学习下的转移能力实验(RQ2):该实验通过使用未暴露给训练集的标签来进行零样本学习,以评估UniGAD的迁移能力。作者使用AUROC作为评估指标,并发现UniGAD在零样本学习下表现优于现有的多任务提示学习方法,在某些监督设置下甚至超过了领先基线。
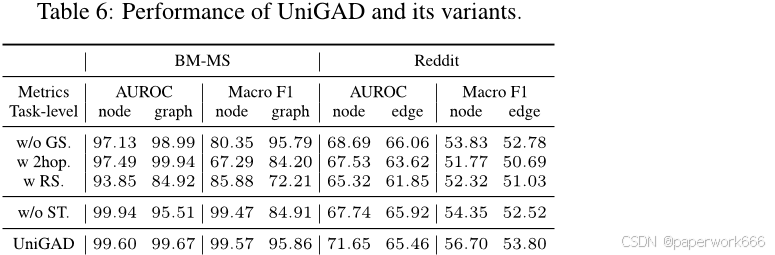
模块贡献分析实验(RQ3):该实验旨在研究UniGAD中各个模块对整体性能的贡献。作者比较了不使用子图采样、简单采样和随机采样的情况,并将Graph-Stitch模块替换为一个统一的MLP。结果表明,子图采样和Graph-Stitch模块都有助于提高UniGAD的整体性能。
效率分析实验(RQ4):该实验旨在评估UniGAD的时间和空间效率。作者在大型真实世界数据集T-Group上进行了全面的评估,并将其与其他单任务和多任务方法进行了比较。结果显示,UniGAD的执行时间比最快的单任务模型慢一些,但比组合平均值快;同时,它的内存消耗与节点级别模型相当,远低于图形级别和提示方法。


- 总结
值得精读
本文提出了一种名为UniGAD的统一图异常检测框架,该框架能够联合处理节点、边和图级别的异常情况,并且在实验中取得了显著的性能提升。此外,文章还介绍了一些新的组件,如MRQSampler和GraphStitch网络,这些组件可以有效地解决多级别任务训练的问题。
UniGAD模型采用了两个新颖的组件:MRQSampler和GraphStitch网络。其中,MRQSampler通过最大化积累谱能量来确保子图捕获关键的异常信息,解决了不同图对象格式之间的统一问题;而GraphStitch网络则通过使用相同的网络结构来实现节点、边和图级别的多级训练,并使用GraphStitch单元来有效地共享信息。这种多级训练的方法是之前没有被广泛研究过的。
- 局限性
尽管UniGAD已经在多个数据集上取得了优异的表现,但是仍有一些限制需要进一步改进。例如,现有的GNN编码器主要关注于节点级别的嵌入,可能会导致丢失关于图结构的信息。因此,在未来的探索中,应该考虑如何将多级别任务预训练应用于图学习领域,以提高模型的效果。
3、Understanding Graph Databases: A Comprehensive Tutorial and Survey
全文总结:这篇论文是一篇关于图数据库的综述和教程。文章首先介绍了图理论的基础知识,并探讨了图的不同类型和结构,包括无向图、有向图、带权图和不带权图等。然后,论文讲解了图的基本属性、术语和关键算法,如Dijkstra最短路径算法和计算节点中心性和图连通性的技术。此外,该文还详细介绍了Neo4j、Amazon Neptune和ArangoDB等流行的图数据库系统及其特点,以及如何使用NetworkX和Neo4j进行图操作,包括创建节点和边、分配属性和高级查询等。最后,论文提供了常用的图可视化技术和社区检测算法,如Louvain方法,以支持大规模网络中的聚类分析。总之,本文为读者提供了一个全面的理解图数据库的知识体系,有助于研究人员进一步探索这个领域。
- 文章研究背景和要解决的问题挑战
这篇文章的研究背景是介绍图形数据库的基础知识,并探讨其在多个领域的实际应用。它强调了图形理论的基础概念,并详细解释了节点和边的结构以及不同类型的图形,如无向图、有向图、带权图和无权图等。
- 具体实现
该论文主要介绍了在图数据处理中常用的算法和工具,包括基本图形操作、路径计算、图密度和连接性分析、基本图形操作、节点和边删除以提高网络韧性等。其中,路径计算包括最短路径算法(如Dijkstra算法)和图形相似度指标(如Gromov-Wasserstein距离)。此外,还讨论了如何使用Python库(如NetworkX)和Neo4j数据库来实现这些算法和工具。
该论文重点介绍了各种算法和工具的优点和适用场景,并提供了示例代码和实际应用案例。例如,在节点和边删除方面,提出了基于社团结构和拓扑信息的删除策略,可以有效地减少冗余连接并提高网络韧性。此外,还探讨了如何将不同的算法和工具结合起来,形成更完整的图数据分析流程。
该论文解决了图数据分析中的多个问题,包括路径计算、网络连通性评估、社区发现、节点和边删除等方面。通过介绍各种算法和工具的特点和应用场景,可以帮助读者更好地理解和应用这些技术,从而提高图数据分析的效率和准确性。同时,该论文也提供了一些实用的示例代码和案例,方便读者快速上手实践。
- 实验设计
本文介绍了关于图数据库Neo4j的性能优化和应用案例的研究。首先,文章讨论了并行处理和性能优化在大型应用程序中的重要性,并介绍了Neo4j支持的并行处理技术和代码优化方法。其次,文章通过比较不同算法和技术的效率来评估了Neo4j的性能,并提出了一些优化建议。最后,文章还提供了一个基于Neo4j的社交网络分析工具的实现案例,展示了如何使用Neo4j来解决实际问题。
在性能优化方面,文章提出了并行处理和代码优化的重要性,并介绍了Neo4j支持的并行处理技术和代码优化方法。其中,批量加载和多线程操作可以提高数据加载和查询的速度,而代码优化则可以通过调整Cypher查询来减少计算量和内存使用。此外,文章还提到了一些高级并行处理技术和硬件利用方式,如GPU和FPGA的应用,以及如何结合特定的平行处理架构来进一步提高性能。
在性能评估方面,文章采用了多个评估指标来比较不同的算法和技术。例如,在批处理中,作者使用了时间作为评估指标,并比较了不同的批量大小对性能的影响。在代码优化方面,作者使用了Neo4j的内置统计功能来测量执行时间和内存使用情况,并比较了不同优化策略的效果。在高级并行处理技术方面,作者使用了Neo4j的分布式部署模式,并比较了不同配置下的性能差异。最终,作者得出结论,通过合理选择并行处理技术和代码优化策略,可以显著提高Neo4j的性能。
在应用案例方面,文章提供了一个基于Neo4j的社交网络分析工具的实现案例。该工具使用Neo4j来存储和查询用户之间的关系,并提供了可视化界面来展示结果。具体来说,该工具实现了以下功能:
数据收集和预处理:从Twitter上收集用户的关注列表,并将其转换为节点和边的形式。
数据模型设计:设计一个适合社交网络分析的数据模型,包括用户节点、关注关系边等。
图形表示:使用Neo4j的图形界面来显示社交网络结构和分析结果。
社交网络分析:使用Neo4j提供的API来进行社交网络分析,如度中心性、介数中心性等。
可视化展示:将分析结果以图表等形式展示出来,方便用户理解和使用。
通过这个案例,读者可以了解到如何使用Neo4j来解决实际问题,并了解Neo4j的一些特性和功能。同时,这个案例也展示了Neo4j在社交网络分析领域的潜力和价值。
4、Uncover the Dynamic Community Structure of Instant Delivery Network
全文总结:本篇论文主要探讨了即时配送网络的空间结构动态变化,并提出了相应的分析方法和结果。通过对北京市的大规模数据集进行分析,构建了一个时间依赖的多层即时配送网络模型,并使用动态社区检测方法识别出随着时间变化而演变的社区结构。研究发现,在一天中,社区会形成、扩张、稳定、收缩并最终消失,其中建筑面积和人口密度是影响稳定性的重要因素,而在线零售和服务设施则对不稳定起着贡献作用。这些发现为优化平台策略、资源分配以及城市交通规划提供了实用的启示。
- 文章研究背景和要解决的问题挑战
这篇文章的研究背景是随着在线订餐服务的发展,即时配送服务已成为城市居民日常生活中不可或缺的一部分。然而,由于即时配送服务具有快速响应和灵活性等特点,其形成的社区结构仍然是未知的,并且对平台策略和资源分配的影响也尚不清楚。因此,本研究旨在揭示即时配送网络中的动态社区结构及其变化规律,以期为优化平台策略、资源分配和城市交通规划提供实践指导。
- 具体实现
该研究使用了多层网络分析来探究北京市2020年2月的外卖订单数据中的动态社区结构。首先将订单数据聚合到500米×500米网格单元中,并构建即时配送起始-目的地(OD)网络。然后将配送数据组织成18个一小时时间片,每个配送订单流表示为一个OD对,其中内层边连接同一时间片内的订单,外层边链接不同时间层之间的订单。这种结构可以同时分析空间邻近性和时序交互在网络中的作用。
接下来,使用基于随机游走的MutuRank算法计算每个时间层的权重,考虑不同时间步长的影响。然后,在加权的时间多层网络上应用Leiden算法以检测动态社区——在整个网络中相互连接良好的网格单元群组。这些社区在每个时间层中被识别出来,允许观察它们的时空变化。
最后,通过Jaccard相似度量化不同时刻之间社区重叠的程度,分析动态交付社区的生命循环。通过跟踪社区成员资格随时间的变化,识别出全天稳定和波动的单位。此外,还探索这些变化如何与特定的土地利用模式相关联,使用可解释机器学习方法结合XGBoost分类和SHAP来解释因素的相对贡献。
该研究使用了多层网络分析框架,使得能够同时分析空间邻近性和时序交互在配送网络中的作用。同时,通过使用MutuRank算法和Leiden算法,实现了动态社区的检测和分析。这种方法能够更好地理解外卖订单数据中的社区结构及其演变规律。
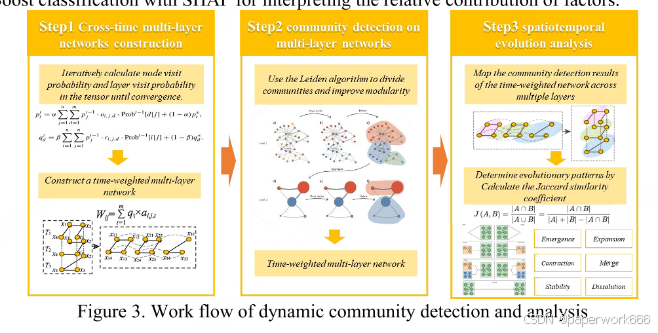
该研究旨在探究北京市2020年2月的外卖订单数据中的动态社区结构,以了解其生命循环、时空变化以及与土地利用模式的关系。通过使用多层网络分析框架,能够更全面地理解外卖订单数据中的社区结构及其演变规律,从而有助于优化外卖配送服务和城市规划决策。
- 实验设计
本文主要研究了即时配送社区的动态变化模式,并通过时间层析分析识别出了309个动态即时配送社区。其中,文章对这些社区的空间分布和大小进行了比较,得出了以下结论:
社区空间分布呈现出从密集到分散的变化趋势,城市中心区域有较为集中的社区,而郊区如怀柔区和密云区则相对分散。
社区数量在上午9点至晚上10点之间保持稳定,而其面积则呈现出“增加-减少”的波动规律,在11点至12点之间达到峰值,平均面积为13.78平方公里。
不同持续时间的即时配送社区表现出不同的生命周期,长期存在的社区通常在早晨形成、扩张、稳定并最终消失,而短期存在的社区则快速形成并在中午或傍晚迅速消失。
稳定单元和变量单元的分布特征不同,前者形成了特定的空间聚类,后者则沿着某些边界分布。此外,商业集群作为服务单位的锚定点,对于服务单位的稳定性具有一定的作用。
通过SHAP-based识别方法,作者还进一步探讨了影响社区变化的因素。结果显示,人口密度和建筑面积与社区变化的相关性较大,表明人口聚集导致服务单元不稳定,而商业集群可以起到一定的稳定作用。
- 总结
值得精读 动态社区检测方法
本文通过实证研究探讨了动态社区结构对城市空间规划和平台策略的影响,并提出了相应的启示。具体来说,文章的优点包括:
研究对象具有代表性:文章选取了某在线外卖平台在上海市的订单数据作为研究对象,该平台在中国市场占有较大份额,且其服务范围覆盖全国多个城市,因此可以代表中国城市的普遍情况。
数据处理精细:文章采用了多种数据分析工具和技术,如网络分析、聚类分析等,对数据进行了细致的处理和分析,得出了一些有意义的结果。
结果具有实际意义:文章的研究结果为城市规划者和平台经营者提供了有价值的参考,例如对于平台优化和城市空间规划等方面都提出了一些建议。
创新点主要体现在以下几个方面:
(1)动态社区结构的识别:文章采用了基于时间序列的动态社区结构识别方法,能够更准确地反映城市居民的活动规律和社区演变过程。
(2)平台优化策略:文章提出了针对不同稳定性和波动性的区域采取不同的平台优化策略,这对于提高平台运营效率和服务质量具有重要意义。
(3)地区划分与容量优化:文章将城市划分为不同的子区域,并根据每个区域的需求特点制定相应的优化方案,这有助于实现资源的合理分配和利用。
- 局限性
本文的研究结果为城市规划和平台经营提供了一些有益的启示,但还存在一些需要进一步探索的问题,例如:
如何更好地预测和应对突发状况:随着城市化进程的加速和社会经济的发展,城市面临的风险和挑战也在不断增加,如何更好地预测和应对这些风险是未来需要关注的方向之一。
如何进一步提高算法精度:目前的算法虽然已经取得了一定的效果,但在实际应用中仍存在一定的误差和局限性,如何进一步提高算法的精度和可靠性也是未来需要解决的问题之一。
如何更好地促进城市可持续发展:城市可持续发展是一个综合性问题,涉及到社会、经济、环境等多个方面的因素,如何更好地协调各方面的利益关系,推动城市的可持续发展也是未来需要深入研究的方向之一。
5、The ParClusterers Benchmark Suite(PCBS):A Fine-Grained Analysis of Scalable Graph Clustering[Experiment, Analysis& Benchmark]
全文总结:本文介绍了一个名为PCBS(ParClusterers Benchmark Suite)的工具包,用于评估并比较不同可扩展图聚类算法和实现的效果。该工具包包括多种现代图聚类使用场景下的聚类算法,并提供了方便快捷的运行和评估多个不同聚类算法实例的方式。作者通过使用PCBS对一组真实世界的数据集进行了评估,并发现一些不在流行图聚类工具包中的算法能够获得最佳质量结果。PCBS提供了一种标准化的方式来评价和判断可扩展图聚类算法的质量与性能之间的权衡关系,有助于公平、准确、细致地评估未来的图聚类算法。
- 文章研究背景和要解决的问题挑战
PCBS解决了大规模、高维的无向或有向图聚类问题,提高了聚类效率和精度。通过提供多种聚类算法和评估指标,PCBS可以帮助研究人员比较不同算法之间的性能差异,从而为实际应用提供更准确的聚类结果。此外,PCBS的灵活性和可扩展性也使其适用于不同的应用场景和需求。
- 具体实现
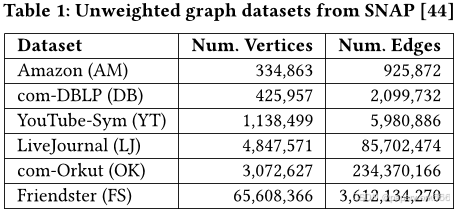
本文提出了一个名为Parallel Community-Based System(PCBS)的并行图聚类系统,该系统能够处理大规模、高维的无向或有向图,并能够在共享内存的多核机器上运行。PCBS包括11种可扩展的并行图聚类算法,其中包括重量级聚类算法Affinity Clustering、Correlation Clustering以及Modularity Clustering等。此外,PCBS还提供了多种聚类质量评估指标,如精确度、召回率、F分数、调整后兰德指数(ARI)、归一化互信息(NMI)等。
PCBS采用了灵活的配置文件和参数搜索机制,使得用户可以方便地添加新的数据集、算法、参数搜索策略以及评估指标。同时,PCBS支持在多个聚类实现中选择最佳结果,例如NetworKit、Neo4j和TigerGraph等。
- 实验设计
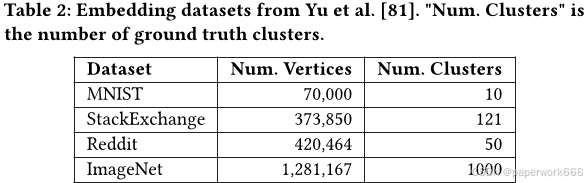
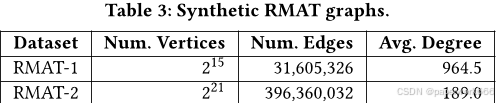
本文主要介绍了使用PCBS基准库对不同图聚类算法的性能进行了比较和分析。具体来说,本文进行了四个任务的实验:社区检测、向量嵌入聚类、密集子图分割和高分辨率聚类,并对每个任务的结果进行了详细的讨论和总结。
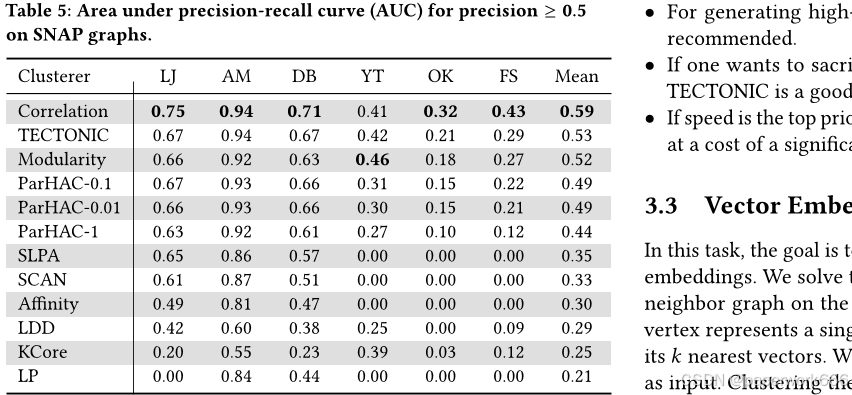
在社区检测任务中,作者使用了四个未加权的SNAP图,并计算了各种算法的质量和运行时间。结果表明,相关聚类通常可以获得最佳质量,但相对较慢。TECTONIC通常比相关聚类获得较低的质量,但它非常快。LDD是最快的算法之一,但其质量甚至低于TECTONIC。TECTONIC经常比其他方法(如LDD、KCore、LP、SCAN和Affinity)具有更高的质量。
在向量嵌入聚类任务中,作者使用了三个嵌入数据集,并计算了各种算法的质量和运行时间。结果表明,在这些数据集中,基于权重的聚类算法(如亲和力、相关性和模度)通常比不带权重的聚类算法表现更好。此外,作者还推荐使用相关聚类和模度聚类来生成高质量的聚类,并建议使用LP作为快速聚类的选择。
在密集子图分割任务中,作者使用了两个RMAT图,并计算了各种算法的密度和运行时间。结果表明,模度聚类和相关聚类可以产生最密集的聚类。当集群数量相对较少时,模度聚类产生的集群密度高于相关聚类,但当集群数量非常大时,相关聚类产生的集群密度更高。作者建议在集群数量相对较小的情况下使用模度聚类,否则使用相关聚类。
最后,在高分辨率聚类任务中,作者使用了一个新的NGrams数据集,并计算了各种算法的质量和运行时间。结果表明,相关聚类通常可以获得较高的精度和召回率,而模度聚类则表现出较差的效果。作者建议在需要快速聚类且不需要考虑精确度的情况下使用LP,而在需要高度准确的聚类时使用相关聚类。
总的来说,本文提供了对不同图聚类算法的全面比较和分析,为选择适合特定任务的算法提供了有用的指导。
- 总结
本文系统地比较了多种图聚类算法在不同任务上的表现,并提供了相应的实验结果。
作者设计了一个可扩展的基准测试套件,包括多个并行图聚类算法实现和多个评估指标。
该研究为图聚类领域的研究者提供了一个全面的工具箱,可以方便地进行各种聚类算法的比较和评估。
- 局限性
可以进一步探索如何将机器学习技术应用于图聚类问题中,以提高聚类的质量和效率。
可以继续开发更多的聚类算法,并将其添加到基准测试套件中,以便更好地比较它们的表现。
可以考虑使用深度学习等新技术来解决图聚类问题中的挑战,例如处理大规模数据集和高维特征空间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









