







Open-Sora
论文
video-generation-models-as-world-simulators
模型结构
该模型为基于Transformer的视频生成模型,包含Video Encoder-Decoder用于视频/图像的压缩/恢复,Transformer-based Latent Stable Diffusion用于扩散/恢复,以及Conditioning用于生成对训练视频的条件(这里指文本描述)。
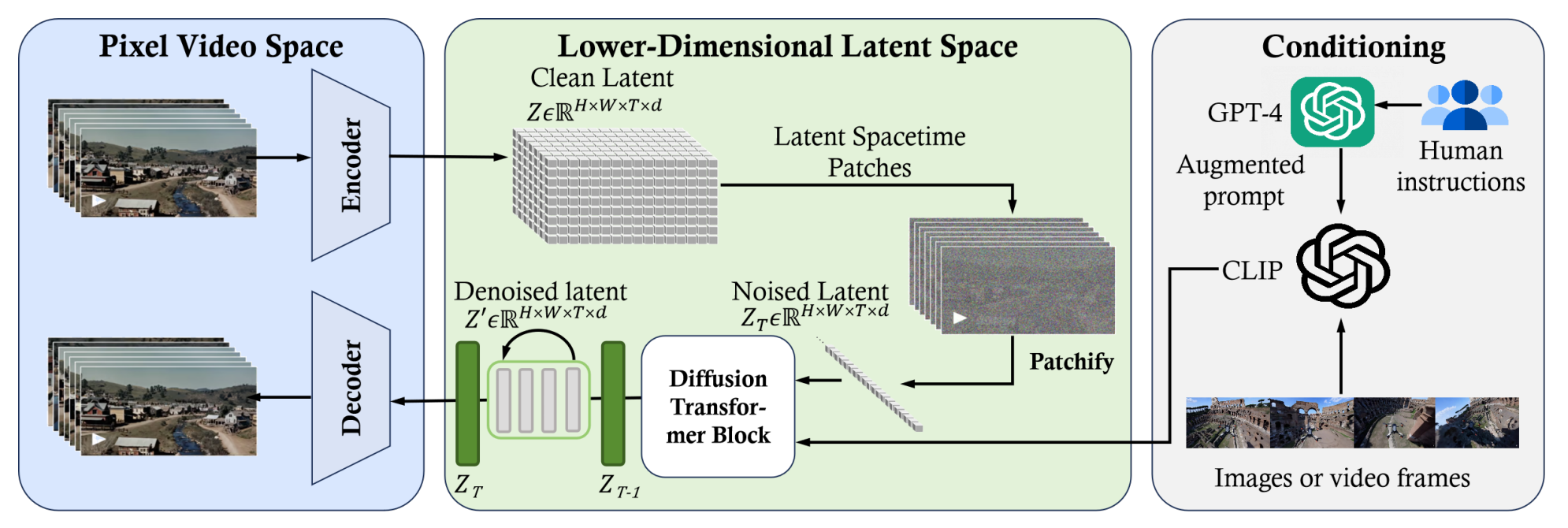
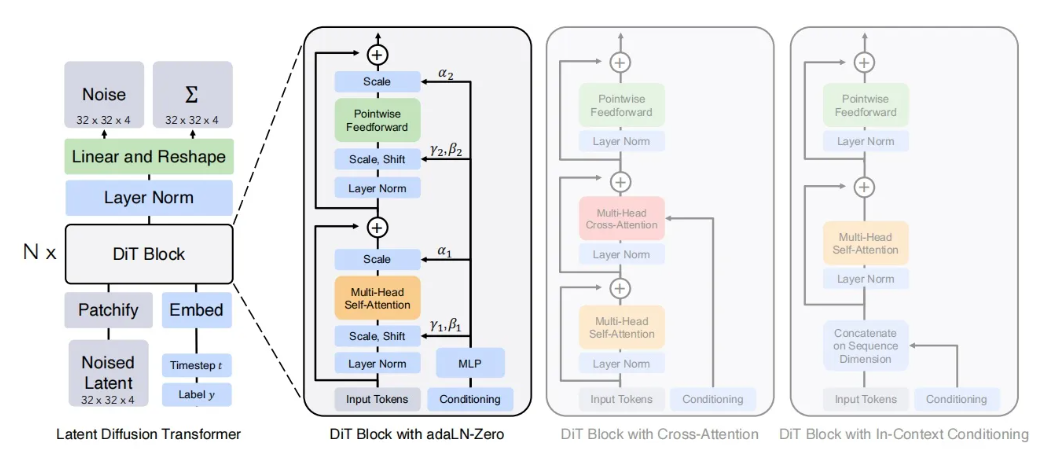
算法原理
该算法通过在隐空间使用Transformer模型对视频进行扩散/反扩散学习视频的分布。
环境配置
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk23.10.1-py38
docker run --shm-size 10g --network=host --name=opensora --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
pip install flash_attn-2.0.4_torch2.1_dtk2310-cp38-cp38-linux_x86_64.whl (whl.zip文件中)
pip install triton-2.1.0%2Bgit34f8189.abi0.dtk2310-cp38-cp38-manylinux2014_x86_64.whl (开发者社区下载)
cd xformers && pip install xformers==0.0.23 --no-deps && bash patch_xformers.rocm.sh (whl.zip文件中)
pip install -r requirements.txt
pip install .
Dockerfile(方法二)
# 需要在对应的目录下
docker build -t <IMAGE_NAME>:<TAG> .
docker run --shm-size 10g --network=host --name=opensora --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
pip install flash_attn-2.0.4_torch2.1_dtk2310-cp38-cp38-linux_x86_64.whl (whl.zip文件中)
pip install triton-2.1.0%2Bgit34f8189.abi0.dtk2310-cp38-cp38-manylinux2014_x86_64.whl (开发者社区下载)
cd xformers && pip install xformers==0.0.23 --no-deps && bash patch_xformers.rocm.sh (whl.zip文件中)
pip install -r requirements.txt
pip install .
Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK驱动:dtk23.10.1
python:python3.8
torch:2.1.0
torchvision:0.16.0
triton:2.1.0
apex:0.1
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install flash_attn-2.0.4_torch2.1_dtk2310-cp38-cp38-linux_x86_64.whl (whl.zip文件中)
cd xformers && pip install xformers==0.0.23 --no-deps && bash patch_xformers.rocm.sh (whl.zip文件中)
pip install -r requirements.txt
pip install .
数据集
完整数据集下载:https://drive.google.com/drive/folders/154S6raNg9NpDGQRlRhhAaYcAx5xq1Ok8
可使用下列数据用于快速验证
OpenDataLab 引领AI大模型时代的开放数据平台 (ImageNet)
UCF101 – Action Recognition Data Set – Center for Research in Computer Vision (UCF101)
链接:百度网盘 请输入提取码 提取码:kwai (mini数据集)
数据结构
UCF-101/
├── ApplyEyeMakeup
│ ├── v_ApplyEyeMakeup_g01_c01.avi
│ ├── v_ApplyEyeMakeup_g01_c02.avi
│ ├── v_ApplyEyeMakeup_g01_c03.avi
│ ├── ...
使用脚本对数据进行处理并获取相应的csv文件
# ImageNet
python -m tools.datasets.convert_dataset imagenet IMAGENET_FOLDER --split train
# UCF101
python -m tools.datasets.convert_dataset ucf101 UCF101_FOLDER --split videos (如:ApplyEyeMakeup)
训练
敬请期待!
推理
模型下载
| Resoluion | Data | #iterations | Batch Size | GPU days (H800) | URL |
|---|---|---|---|---|---|
| 16×256×256 | 366K | 80k | 8×64 | 117 | https://huggingface.co/hpcai-tech/Open-Sora/blob/main/OpenSora-v1-16x256x256.pth |
| 16×256×256 | 20K HQ | 24k | 8×64 | 45 | https://huggingface.co/hpcai-tech/Open-Sora/blob/main/OpenSora-v1-HQ-16x256x256.pth |
| 16×512×512 | 20K HQ | 20k | 2×64 | 35 | https://huggingface.co/hpcai-tech/Open-Sora/blob/main/OpenSora-v1-HQ-16x512x512.pth |
https://huggingface.co/DeepFloyd/t5-v1_1-xxl/tree/main (T5)
pretrained_models/
└── t5_ckpts
└── t5-v1_1-xxl
├── config.json
├── pytorch_model-00001-of-00002.bin
├── pytorch_model-00002-of-00002.bin
├── pytorch_model.bin.index.json
├── special_tokens_map.json
├── spiece.model
└── tokenizer_config.json
models/
├── OpenSora-v1-HQ-16x256x256.pth
└── ...
注意:可以使用https://hf-mirror.com加速下载相应的模型权重。
命令行
# Sample 16x256x256 (5s/sample) 显存 ~32G
torchrun --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x256x256.py --ckpt-path ./path/to/your/ckpt.pth
# Sample 16x512x512 (20s/sample, 100 time steps) 显存 > 32G
torchrun --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x512x512.py --ckpt-path ./path/to/your/ckpt.pth
result
| 模型 | prompt | 结果 |
|---|---|---|
| 16×256×256 | assets/texts/t2v_samples.txt:1 |
|
| 16×256×256 | assets/texts/t2v_samples.txt:2 |
|


精度
无
应用场景
算法类别
视频生成
热点应用行业
媒体,科研,教育

















 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











