







Yi
论文
- 暂无
模型结构
Yi系列模型结构与llama结构基本一致,以 Transformer 架构为基础:
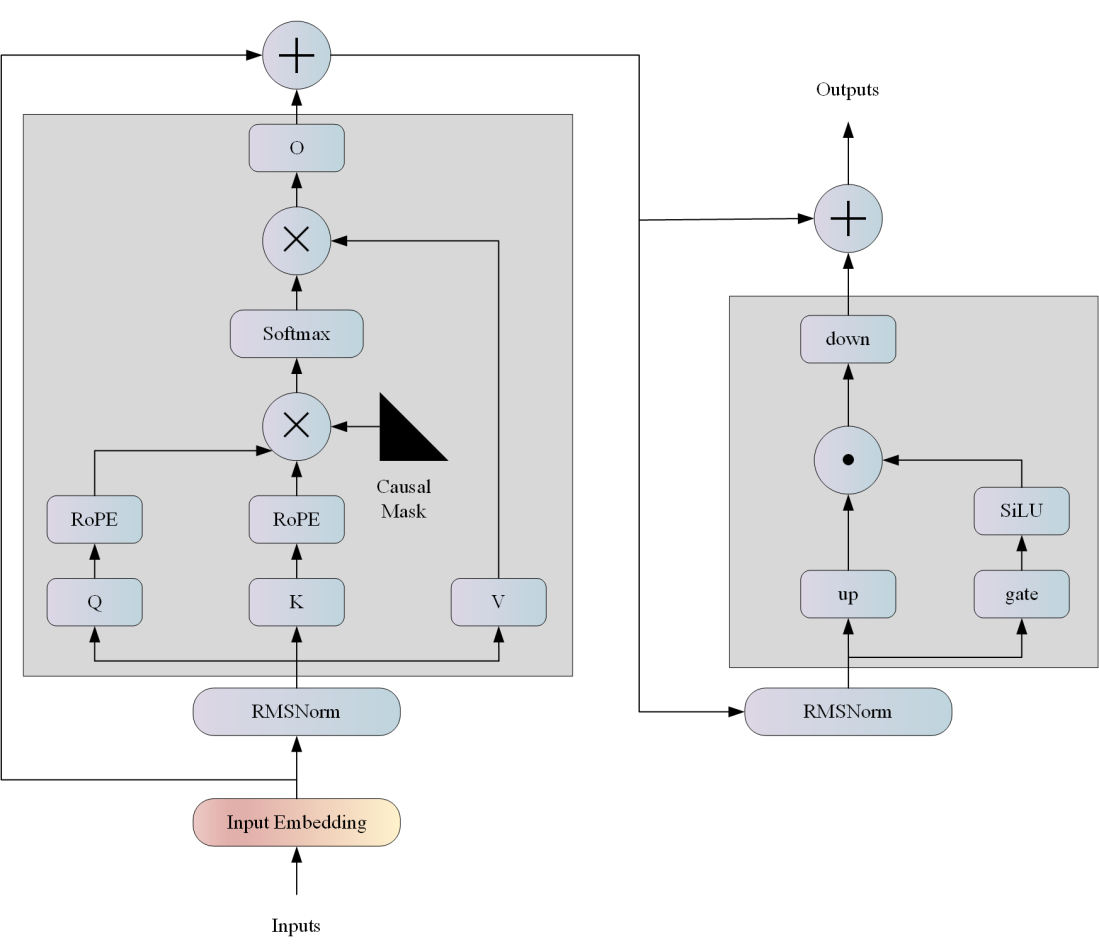
算法原理
Yi 系列模型以双语语言模型为目标,并在 3T 多语言语料库上进行训练,成为全球最强大的 LLM 模型之一,在语言理解、常识推理、阅读理解等方面显示出前景。

环境配置
提供光源拉取推理的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:lmdeploy-dtk23.10-torch1.13-py38
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name codellama --shm-size=1024G -v /opt/hyhal:/opt/hyhal --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> image.sourcefind.cn:5000/dcu/admin/base/custom:lmdeploy-dtk23.10-torch1.13-py38 /bin/bash
数据集
无
推理
源码编译安装
git clone http://developer.hpccube.com/codes/modelzoo/yi_lmdeploy.git
cd yi_lmdeploy
git submodule init && git submodule update
cd lmdeploy
mkdir build && cd build
sh ../generate.sh
make -j 32
make install
cd .. && pip uninstall lmdeploy && python3 setup.py install
模型下载
运行
模型转换
执行如下的命令,把模型权重转成 turbomind 要求的格式:
# 转模型格式,转换后的模型会生成在./workspace目录中
# 其中--tp设置为你需要使用的gpu数,tp需要设置为2^n,如果tp设置的不是1,则后续模型的运行命令中也需要带上这个参数与模型对应
lmdeploy convert yi /path/of/yi-34b/model --dst_path ./workspace_yi-34b --tp 4
bash界面运行
lmdeploy chat turbomind --model_path ./workspace_yi-34b --tp 4
web页面方式交互
lmdeploy serve gradio --model_path_or_server ./workspace_yi-34b --server_name {server_ip} --server_port {port} --batch_size 32 --tp 4 --restful_api False
浏览器上打开 http://{server_ip}:{server_port},即可进行对话 需要保证'{server_ip}:{server_port}'在外部浏览器中的可访问性
api-server
启动server:
# --instance_num: turbomind推理实例的个数。可理解为支持的最大并发数
# --tp: 在 tensor parallel时,使用的GPU数量
lmdeploy serve api_server ./workspace_yi-34b --server_name ${server_ip} --server_port ${server_port} --instance_num 32 --tp 4
浏览器上打开 http://{server_ip}:{server_port},即可访问 swagger,查阅 RESTful API 的详细信息。
可以用命令行,在控制台与 server 通信(在新启的命令行页面下执行):
# restful_api_url 就是 api_server 产生的,即上述启动server的http://{server_ip}:{server_port}
lmdeploy serve api_client restful_api_url
或者,启动 gradio,在 webui 的聊天对话框中,与服务交流:
# restful_api_url 就是 api_server 产生的,比如 http://localhost:23333
# server_ip 和 server_port 是用来提供 gradio ui 访问服务的
# 例子: lmdeploy serve gradio http://localhost:23333 --server_name localhost --server_port 6006 --restful_api True
lmdeploy serve gradio restful_api_url --server_name ${server_ip} --server_port ${server_port} --restful_api True
需要保证'{server_ip}:{server_port}'在外部浏览器中的可访问性
关于 RESTful API的详细介绍,请参考这份文档。
result
精度
无
应用场景
算法类别
对话问答
热点应用行业
金融,科研,教育
源码仓库及问题反馈
ModelZoo / Yi_lmdeploy · GitLab
参考资料
GitHub - 01-ai/Yi: A series of large language models trained from scratch by developers @01-ai
GitHub - InternLM/lmdeploy: LMDeploy is a toolkit for compressing, deploying, and serving LLMs.
















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











