







GLM
论文
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
模型结构
2017 年, Google 提出了 Transformer 架构, 随后 BERT 、GPT、T5等预训练模型不断涌现, 并在各项任务中都不断刷新 SOTA 纪录。2022年, 清华提出了 GLM 模型(GitHub - THUDM/GLM: GLM (General Language Model)), 不同于上述预训练模型架构,它采用了一种自回归的空白填充方法, 在 NLP 领域三种主要的任务(自然语言理解、无条件生成、有条件生成)上都取得了不错的结果。
在LiBai中主要实现了GLM推理部分的工作。
算法原理
当模型规模过于庞大,单个 GPU 设备无法容纳大规模模型参数时,便捷好用的分布式训练和推理需求就相继出现,业内也随之推出相应的工具。
基于 OneFlow 构建的 LiBai 模型库让分布式上手难度降到最低,用户不需要关注模型如何分配在不同的显卡设备,只需要修改几个配置数据就可以设置不同的分布式策略。当然,加速性能更是出众。
用 LiBai 搭建的 GLM 可以便捷地实现model parallel + pipeline parallel推理, 很好地解决单卡放不下大规模模型的问题。
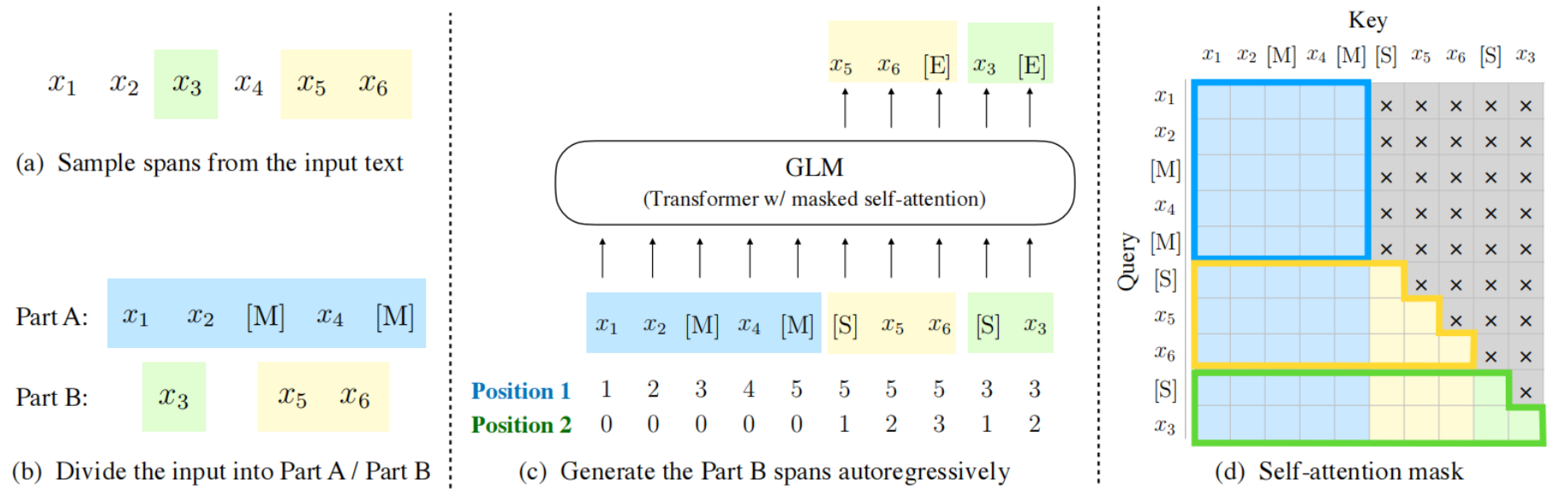
分布式推理具有天然优势
要知道,模型的参数其实就是许多 tensor,也就是以矩阵的形式出现,大模型的参数也就是大矩阵,并行策略就是把大矩阵分为多个小矩阵,并分配到不同的显卡或不同的设备上,基础的 LinearLayer 在LiBai中的实现代码如下:
class Linear1D(nn.Module):
def __init__(self, in_features, out_features, parallel="data", layer_idx=0, ...):
super().__init__()
if parallel == "col":
weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.split(0)])
elif parallel == "row":
weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.split(1)])
elif parallel == "data":
weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast])
else:
raise KeyError(f"{parallel} is not supported! Only support ('data', 'row' and 'col')")
self.weight = flow.nn.Parameter(
flow.empty(
(out_features, in_features),
dtype=flow.float32,
placement=dist.get_layer_placement(layer_idx), # for pipeline parallelism placement
sbp=weight_sbp,
)
)
init_method(self.weight)
...
def forward(self, x):
...
在这里,用户可选择去如何切分 Linear 层的矩阵,如何切分数据矩阵,而OneFlow 中的 SBP 控制竖着切、横着切以及其他拆分矩阵的方案(模型并行、数据并行),以及通过设置 Placement 来控制这个 LinearLayer 是放在第几张显卡上(流水并行)。
所以,根据 LiBai 中各种 layer 的设计原理以及基于 OneFlow 中 tensor 自带的 SBP 和 Placement 属性的天然优势,使得用户搭建的模型能够很简单地就实现数据并行、模型并行以及流水并行操作。
环境配置
Docker
提供光源拉取的训练以及推理的docker镜像:image.sourcefind.cn:5000/dcu/admin/base/oneflow:0.9.1-centos7.6-dtk-22.10.1-py39-latest,关于本项目DCU显卡所需torch库等均可从光合开发者社区下载安装
docker pull image.sourcefind.cn:5000/dcu/admin/base/oneflow:0.9.1-centos7.6-dtk-22.10.1-py39-latest
# <Your Image ID>用上面拉取docker镜像的ID替换
docker run --shm-size 16g --network=host --name=glm_oneflow --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/glm_oneflow:/home/glm_oneflow -it <Your Image ID> bash
cd /home/glm_oneflow
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
pip3 install pybind11 -i https://mirrors.aliyun.com/pypi/simple
pip3 install -e . -i https://mirrors.aliyun.com/pypi/simple
pip3 install torch-1.10.0a0+git2040069.dtk2210-cp39-cp39-manylinux2014_x86_64.whl
数据集
在代码中生成。
权重
需要先准备好模型权重:https://huggingface.co/THUDM/glm-10b-chinese/tree/main
Glm-10b-chinese权重的文件结构
$ tree data
path/to/glm-10b-chinese
├── added_tokens.json
├── cog-pretrain.model
├── config.json
└── pytorch_model.bin
推理
采用1节点,4张DCU-Z100-16G,采用tp=2,pp=2的并行配置。
将模型权重放置与demo.py同一目录下,运行以下代码:
cd projects/GLM
# 运行前修改 configs/glm_inference.py 中 `pad_token_id=50000, eos_token_id=50007, bos_token_id=None`
python3 -m oneflow.distributed.launch --nproc_per_node 4 demo.py
demo.py如下:
# model parallel + pipeline parallel demo
import oneflow as flow
from projects.GLM.tokenizer.glm_tokenizer import GLMChineseTokenzier
from libai.utils import distributed as dist
from projects.GLM.configs.glm_inference import cfg
from projects.GLM.modeling_glm import GLMForConditionalGeneration
from projects.GLM.utils.glm_loader import GLMLoaderHuggerFace
from omegaconf import DictConfig
import time
# 只需简单配置并行方案
parallel_config = DictConfig(
dict(
data_parallel_size=1,
tensor_parallel_size=2,
pipeline_parallel_size=2,
pipeline_num_layers=2 * 24
)
)
dist.setup_dist_util(parallel_config)
tokenizer = GLMChineseTokenzier.from_pretrained("glm-10b-chinese")
input_ids = tokenizer.encode(
[
"冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者 回答: [gMASK]"
],
return_tensors="of",
)
inputs = {"input_ids": input_ids, "attention_mask": flow.ones(input_ids.size())}
inputs = tokenizer.build_inputs_for_generation(inputs, max_gen_length=128)
sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast])
placement = dist.get_layer_placement(0)
loader = GLMLoaderHuggerFace(
GLMForConditionalGeneration,
cfg,
"glm-10b-chinese",
embedding_dropout_prob=0,
attention_dropout_prob=0,
output_dropout_prob=0,
)
T1 = time.time()
model = loader.load()
T2 = time.time()
if dist.is_main_process():
print('模型加载时间:%s秒' % (T2 - T1))
T3 = time.time()
outputs = model.generate(
inputs=inputs['input_ids'].to_global(sbp=sbp, placement=placement),
position_ids=inputs['position_ids'].to_global(sbp=sbp, placement=placement),
generation_attention_mask=inputs['generation_attention_mask'].to_global(sbp=sbp, placement=placement),
max_length=128
)
T4 = time.time()
if dist.is_main_process():
print('model.generate: %s秒' % (T4 - T3))
T5 = time.time()
res = tokenizer.decode(outputs[0])
T6 = time.time()
if dist.is_main_process():
print('tokenizer.decode: %s秒' % (T6 - T5))
if dist.is_main_process():
print(res)
result
>>>Total number of model parameters: 9,879,633,920
[CLS] 冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者 回答: [gMASK] <|endoftext|> <|startofpiece|> 避寒,当然是去海南呀!<n><n>海南的冬天,阳光明媚,温度适宜,而且空气清新,没有雾霾,没有沙尘暴,没有雾霾,没有雾霾!<n><n>海南的冬天,阳光明媚,温度适宜,而且空气清新,没有雾霾,没有沙尘暴,没有雾霾!<n><n>海南的冬天,阳光明媚,温度适宜,而且空气清新,没有雾霾,没有沙尘暴,没有雾霾!
问答示例
采用1节点,4张DCU-Z100-16G,采用tp=2,pp=2的并行配置。
将模型权重放置与glm-QA.py同一目录下,运行以下代码:
cd projects/GLM
python3 -m oneflow.distributed.launch --nproc_per_node 4 glm-QA.py
程序运行起来后,允许用户在命令行进行问答交互,输入“退出”,可以结束程序,如下所示:
输入
> 如何改善睡眠质量
正在生成内容...
> [CLS] 如何改善睡眠质量 回答: [gMASK] <|endoftext|> <|startofpiece|> 睡眠不好,可以试着用以下方法改善: 1、睡前不要喝咖啡、浓茶、吸烟等,也不要喝含咖啡因的饮料,如可乐、咖啡、茶等。 2、睡前不要进行剧烈运动,如剧烈的跑步、跳舞、打球等。 3、睡前不要看刺激性的电视节目,如恐怖电影、凶杀片等。 4、睡前不要思考问题,如回忆今天发生的事情、明天的工作计划等。 5、睡前不要进食,如吃得过饱、过晚、过饱等。 6、睡前不要进行剧烈的体力活动,如跑步、打球、游泳
输入:
> 从北京到郑州有多少公里
正在生成内容...
> [CLS] 从北京到郑州有多少公里 回答: [gMASK] <|endoftext|> <|startofpiece|> 北京到郑州,直线距离约1000公里,开车需要大约12个小时。 <|endofpiece|>
输入:
> 推荐一部高分恐怖电影
正在生成内容...
> [CLS] 推荐一部高分恐怖电影 回答: [gMASK] <|endoftext|> <|startofpiece|> 《恐怖游轮》<n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n><n>
输入:
> 问题:冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者
正在生成内容...
> [CLS] 问题:冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者 回答: [gMASK] <|endoftext|> <|startofpiece|> 避寒,当然是去海南呀,海南的冬天,阳光明媚,温度适宜,而且海南的冬天,没有雾霾,没有沙尘暴,没有寒冷,只有温暖,海南的冬天,是避寒的好地方。 <|endofpiece|>
输入:
> 介绍一下中科曙光公司
正在生成内容...
> [CLS] 介绍一下中科曙光公司 回答: [gMASK] <|endoftext|> <|startofpiece|> 中科曙光公司成立于2000年,是中国科学院计算技术研究所控股的高科技公司,是国家首批创新型企业,是国家规划布局内重点软件企业,是国家863计划成果产业化基地,是国家高技术产业化示范工程,是国家火炬计划重点高新技术企业,是国家创新型企业试点单位,是国家集成电路设计产业化基地,是国家信息安全成果产业化基地,是国家863计划成果产业化基地,是国家集成电路设计产业化基地,是国家信息安全成果产业化基地,是国家火炬计划重点高新技术企业,是国家创新型企业试点单位,是国家集成电路设计产业化基地,是国家信息安全成果产业化基地,是国家863计划成果产业化基地
输入:
> 退出
> 再见
应用场景
算法类别
自然语言处理
热点应用行业
医疗,教育,科研,金融
源码仓库及问题反馈
参考
- GitHub - Oneflow-Inc/libai: LiBai(李白): A Toolbox for Large-Scale Distributed Parallel Training
-
2017 年, Google 提出了 Transformer 架构, 随后 BERT 、GPT、T5等预训练模型不断涌现, 并在各项任务中都不断刷新 SOTA 纪录。2022年, 清华提出了 GLM 模型(GitHub - THUDM/GLM: GLM (General Language Model)), 不同于上述预训练模型架构,它采用了一种自回归的空白填充方法, 在 NLP 领域三种主要的任务(自然语言理解、无条件生成、有条件生成)上都取得了不错的结果。
















 3209
3209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











