







LivePortrait
论文
LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
模型结构
模型基于face vid2vid,并在此基础上进行改进。主要为,使用ConvNeXt-V2-Tiny作为backbone将原始的规范隐式关键点检测器L、头部姿态估计网络H和表情变形估计网络 Δ统一成一个单一的模型M,使用SPADE decoder作为生成器(在最后一层插入PixelShuffle)。
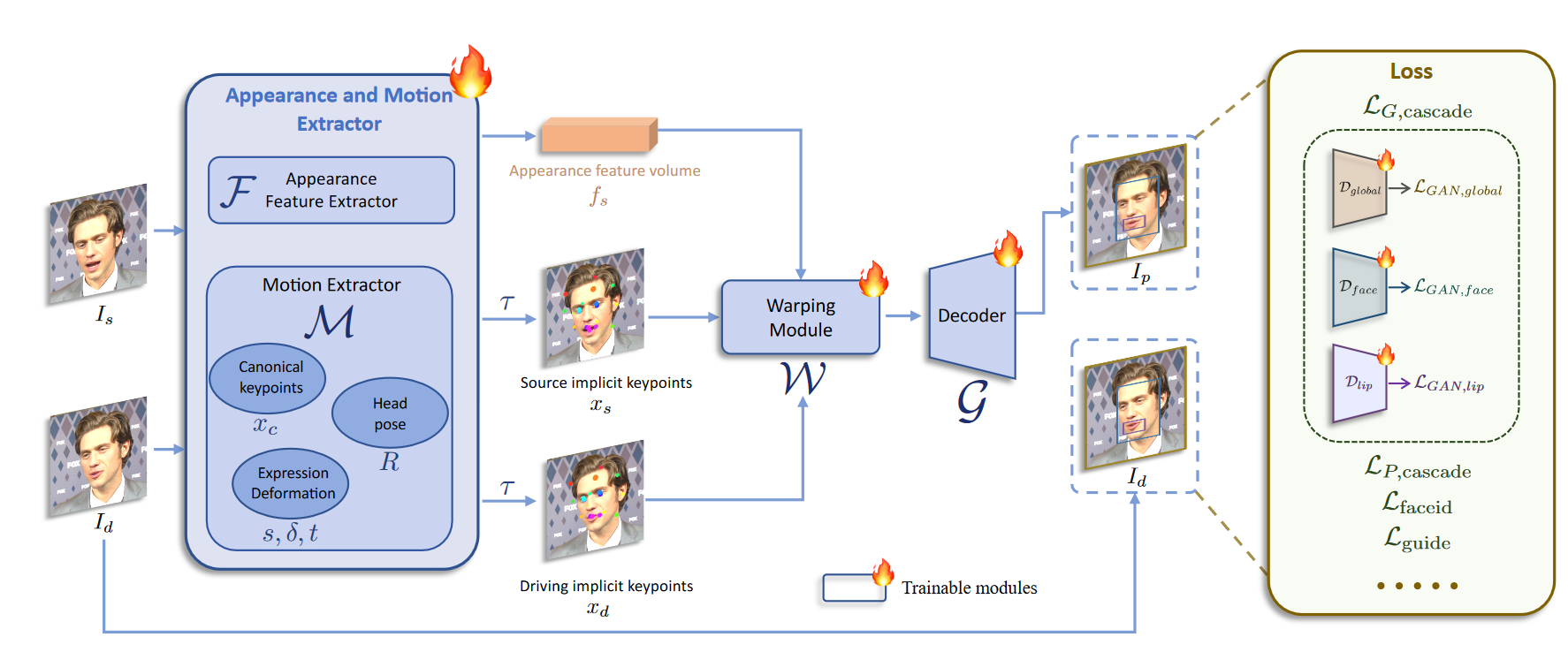
算法原理
该算法采用基于隐式关键点框架,在模型中引入缩放因子,使用高质量数据集及级联损失函数进行两阶段训练。

环境配置
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run --shm-size 50g --network=host --name=liveportrait --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
pip install -r requirements_docker.txt
apt update && apt install ffmpeg
Dockerfile(方法二)
docker build -t <IMAGE_NAME>:<TAG> .
docker run --shm-size 50g --network=host --name=liveportrait --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
pip install -r requirements_docker.txt
apt update && apt install ffmpeg
Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK驱动:dtk24.04.1
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
torchaudio: 2.1.2
triton: 2.1.0
onnxruntime: 1.15.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements_base.txt
conda install -c conda-forge ffmpeg
数据集
无
训练
无
推理
命令行
# 快速测试
python inference.py
# 指定图像及视频
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d0.mp4
# disable pasting back to run faster
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d0.mp4 --no_flag_pasteback
# 查看更多参数
python inference.py -h
# 使用pkl文件加速推理,同时保护隐私
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d5.pkl
数据准备及处理
1、裁剪成 1:1 的宽高比(例如,512x512 或 256x256 像素),或者通过 --flag_crop_driving_video 启用自动裁剪。
2、关注头部区域,类似于示例视频
3、尽量减少肩膀的移动。
4、确保驱动视频的第一帧是正面表情的中性脸。
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d13.mp4 --flag_crop_driving_video
注意:如果您发现自动裁剪的结果不够理想,您可以修改 --scale_crop_video 和 --vy_ratio_crop_video 选项来调整缩放和偏移量,或者手动进行调整。
webui
python app.py --server_name 0.0.0.0 --server_port 12321
result
| source img | driving video | output |
|---|---|---|
|
|
|  |


从左至右依次为driving video, source video以及output

精度
无
应用场景
算法类别
AIGC
热点应用行业
零售,广媒,教育
预训练权重
pretrained_weights
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
└── liveportrait
├── base_models
│ ├── appearance_feature_extractor.pth
│ ├── motion_extractor.pth
│ ├── spade_generator.pth
│ └── warping_module.pth
├── landmark.onnx
└── retargeting_models
└── stitching_retargeting_module.pth
源码仓库及问题反馈
参考资料
Release Notes
- 更多特性请等待
torch2.3

















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











