







- Oracle源表
create table stu(id number(5),name VARCHAR(20),grade NUMBER(5),score NUMBER(5));
INSERT INTO STU VALUES(1,'李四',8,100);
INSERT INTO STU VALUES(2,'多多',9,115);
INSERT INTO STU VALUES(3,'熊安安',7,99);
INSERT INTO STU VALUES(4,'安琪',6,56);
INSERT INTO STU VALUES(5,'等等',4,88);
INSERT INTO STU VALUES(6,'小花',2,97);
开发方式1、Oracle入Hive-编写JSON脚本开发
1.1、建表
- Hive建表
create table if not exists stu(
id int,
name string,
grade int,
score int
)
stored as textfile;
1.2、在datax的bin目录下编辑相对应的json脚本
{
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["id","name","grade","score"],
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@10.6.13.226:1521:orcl"],
"table": ["STU"]
}
],
"password": "123456",
"username": "SCOTT"
}
},
"writer": {
"name":"hdfswriter",
"parameter": {
"defaultFS":"hdfs://192.168.6.102:8020",
"fileType":"text",
"path":"/user/hive/warehouse/test_hive.db/stu",
"fileName":"stu",
"column":[
{"name":"id","type":"int"}
],
"writeMode":"append",
"fieldDelimiter":"\u0001",
"compress":"gzip"
}
}
}
]
}
}
//需要注意的是"fieldDelimiter":"\u0001" 如果是”\t”则hive中不能读取到数据,将会展示为空
1.3、在datax的bin目录下运行相对应的脚本
python /opt/module/datax/bin/datax.py /opt/module/datax/bin/json_conf/student.json
1.4、查看运行结果
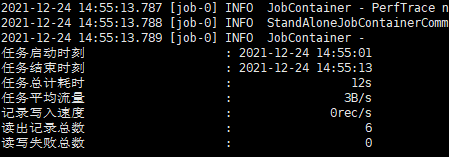
开发方式2、Oracle入Hive基于datax-web端开发
2.1、创建项目
- 项目名称:oracle_hive

2.2、创建DataX任务模板
- 执行器:datax
- 路由策略:轮询
- 阻塞处理:覆盖之前调度
- Cron:每天6点调度

2.3、配置数据源
(1)配置Oracle数据源
- 数据源-添加
数据源:oracle
用户名:SCOTT
密码:123456
JDBCURL:10.6.13.25:1521/orcl

(2)配置Hive数据源
数据源:hive
用户名:atguigu
密码:123456
JDBCURL:192.168.6.102:10000/ods

2.4、任务构建
(1)配置Reader
- 数据库源:orcle_test
- Schema:orcl
- 数据库表名:STU

(2)配置Writer
- 数据库源:hive_test
- 数据库表名:stu

(3)配置字段映射
- 源端字段全选
- 目标字段全选

(4)构建

(5)选择模板

- 选择模板后点击下一步
(6)项目创建成功
- 任务管理->查看项目

2.5、调试执行
(1)立即执行
- 任务管理-》操作-》执行一次

(2)查看日志
- 日志管理–》日志查看
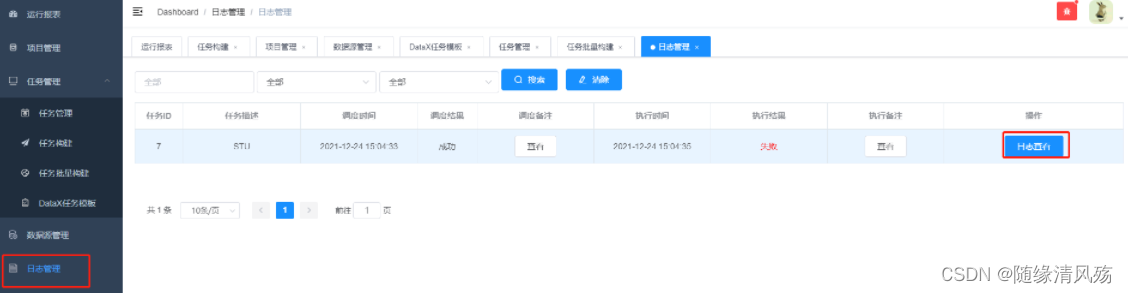
(3)查看报错原因
- 报错原因:配置的分隔符出错

(4)重新编辑任务
- 任务管理–》操作–》编辑

(5)存在问题
- 只能编辑JSON脚本,无法通过界面去编辑。

(6)再次运行&查看日志

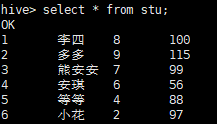
(7)查看hive表中数据

















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











