







1、业务背景
1.1、典型需求
-
业务需求:用户轨迹行为分析
-
离线架构:日志文件+数据采集组件+kafka+ETL+hIVE+报表工具。
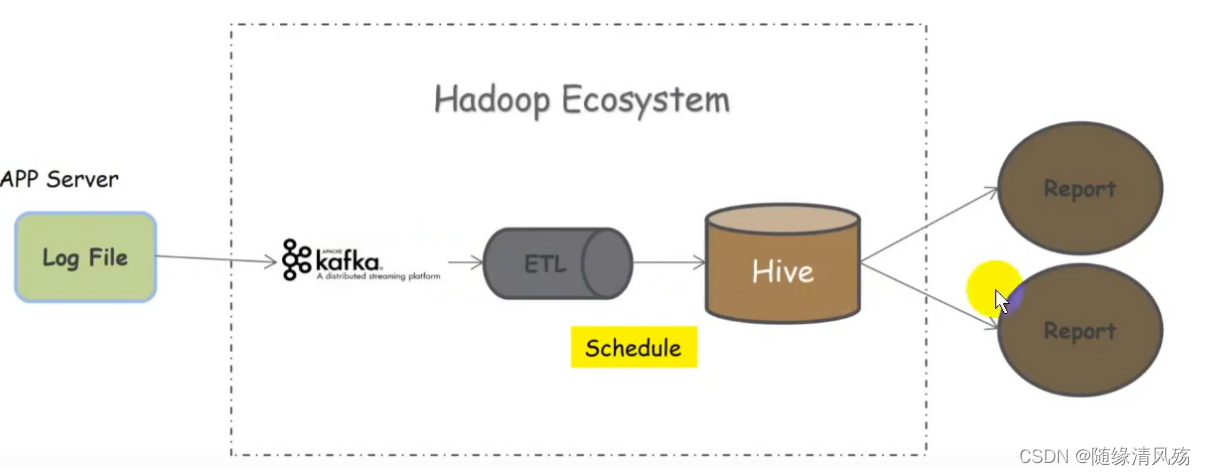
- 架构分析:
- 1.数据时效性低:中间过程经过Kafka、ETL、调度处理,报表的时效性不理想;
- 2.即席分析性能低:HIve存储是hdfs文件系统,查询效率不高,不适合即席查询;
- 3.涉及到Hadoop组件多:涉及到Flume、Kafka、HDFS等,数据冗余过多,技术知识储备身后;
- 4.数据链路长:数据链路处理流程长,繁琐容错也不好。
1.2、典型需求分析优化
- 架构目标:
- 1.海量数据
- 2.实时导入
- 3.实时查询
- 4.多维聚合分析
- 选型分析 - 即席查询
- 少量数据:单机程序
- 中级数据:ES、Mysql分库分表
- 海量数据:Druid、Kylin、Doris、ClickHouse、Kudu等
2、OLAP概述
- OLAP+OLTP====》难以同时满足
2.1、OLAP介绍
(1)OLTP
-
Transaction:事务处理,侧重于增删改,一般都是写模式
-
代表:Mysql、Oracle等
(2)OLAP
- Analysis:分析,大批量数据的聚合查询,一般都是读模式
- 代表:Hive、ClickHouse
(3)读 & 写模式区别
- 写模式:数据插入进来会做校验,如果满足要求则插入,不满足则拒绝
- 读模式:数据读取进来会做校验,如果满足要求则读取,不满足则报错
(4)海量数据做查询分析高效率
- 列式数据库:便于字段查询
- 写模式:每一列数据格式在数据写入时进行校验,保证同一列的数据类型是一样的,便于用连续内存方式进行存储,解析和压缩比较性能高。
- 排序:排序,可便于生成索引做高效的查询分析。
2.2、OLAP场景特征
(1)读多于写
数据一次性写入后,不断多数据做多种ETL处理、数仓模型建设、数据挖掘等相关,其中数据读取的次数远大于写入次数。这就要求底层数据库为这个特点做专门设计,而不是盲目采用传统数据库的技术架构。
(2)大宽表,读大量数据但是少量列,结果集比较小
通常存在一张或是几张多列的大宽表,列数高达数百甚至数千列。
对数据进行分析处理时,选择其中的少数几列作为维度列、其他少数几列作为指标列,然后对全表或某一个较大范围内的数据做聚合处理。这个过程会扫描大量的行数据,但是只会用到了其中的少数列。
select department,count(id) as total from student group by department;
(3)数据批量写入,且数据不更新或少更新
OLTP类业务对于延时要求高,要避免让客户等待造成业务损失;
OLAP类业务,由于数据量非常大,通常更加关注写入吞吐,要求海量数据能够尽快导入完成,一旦导入完成历史数据将作为存档,不会再做更新、删除操作。
- mysql:Insert、Update、Delete,一般作为Source
- Clickhouse:单条记录的增删改,批量导入导出多
(4)无需事务,数据一致性要求低
OLAP类业务对于事务需求较少,通常导入历史日志数据,或搭配一款事务型数据库进行数据同步,多数OLAP系统都支持最终一致性。
(5)灵活多变,不适合预先建模
预建模技术无法满足业务灵活多变的发展需求,维护成本过高。
2.3、常见数据库及业务场景
| 序号 | 数据库名称 | 说明 |
|---|---|---|
| 1 | Mysql | 少量结构化数据的针对单条记录的增删改查 |
| 2 | Hbase | 针对海量数据的Key-Value的增删改查 |
| 3 | Redis | 基于内存的针对Key-value类型增删改查,热数据的缓存 |
| 4 | mongodb | 文档数据库 |
| 5 | elasticsearch | 针对文件做全文检索(倒排索引) |
3、列式数据库
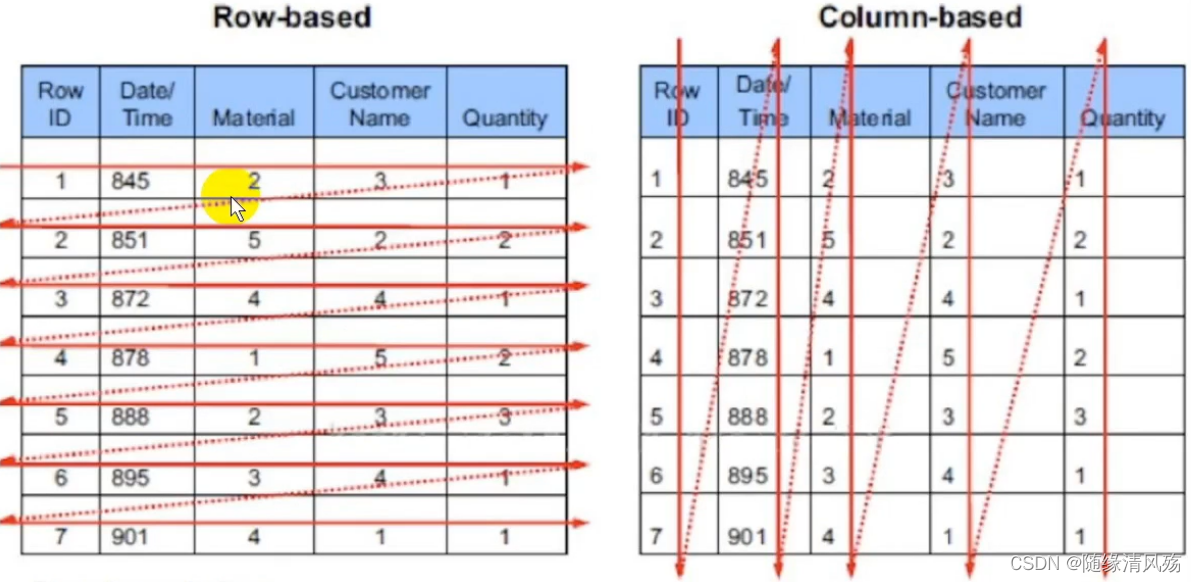
3.1、行式存储 VS 列式存储
- 行式存储:一行数据接着一行数据做存储,一行数据中的多个字段的值都是物理相邻的。
- 列式存储:一列数据单独存储,多行数据的相同列的值在物理存储上是相邻的。
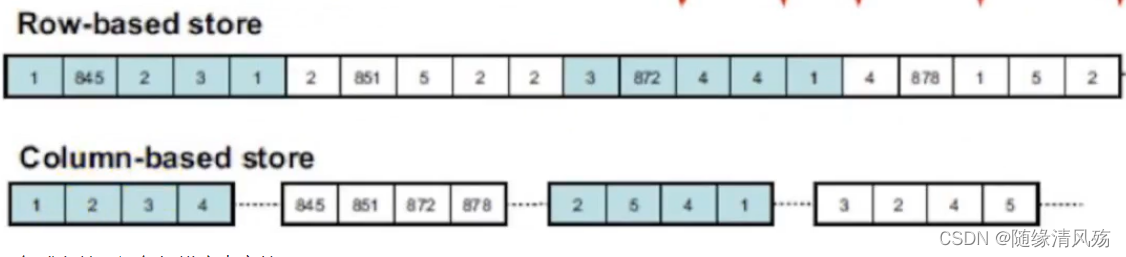
- 行式存储:逐行扫描库表文件
- 列式存储:逐列扫描库表文件
3.2、列式存储特性
(1)读取扫描数据量少
列式存储模式下,只读取参与计算的列即可,极大的减低了IO cost,加速了查询
(2)高压缩比
同一列的数据属于同一个类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,减低了存储成本。
(3)读取时间少
更高的压缩比意味着更小的data size,从磁盘中读取相应耗时更短。
4、ClickHouse概述
4.1、ClickHouse基础介绍
(1)适用场景
- 1、Web和App数据分析
- 2、广告网络和RTB
- 3、电信
- 4、电子商务和金融
- 5、信息安全
- 6、监测和遥测
- 7、时序数据
- 8、商业智能
- 9、在线游戏
- 10、物联网
(2)不适用场景
- 1、事物性工作(OLTP)
- 2、高并发的键值访问
- 3、Blob或者文档存储
- 4、超标准化的数据
(3)优点
①真正的面向列的 DBMS
ClickHouse 作为一个被设计用来在实时分析的 OLAP 组件,只是在高效率的分析方面性能发挥到极 致,那必然就会在其他方面做出取舍: ClickHouse 是一个 DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行 查询,而无需重新配置和重新启动服务器。
②数据压缩
一些面向列的 DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
③磁盘存储的数据
许多面向列的 DBMS(SAP HANA 和 GooglePowerDrill)只能在内存中工作。但即使在数千台服务器 上,内存也太小,无法在 Yandex.Metrica 中存储所有浏览量和会话。
④多核并行处理
多核多节点并行化大型查询。
⑤在多个服务器上分布式处理
在 ClickHouse 中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分 片上并行处理。
⑥SQL支持
ClickHouse SQL 跟真正的 SQL 有不一样的函数名称。不过语法基本跟 SQL 语法兼容,支持 JOIN、 FROM、IN 和 JOIN 子句以及标量子查询支持子查询。
⑦向量化引擎
数据不仅按列存储,而且由矢量 - 列的部分进行处理,这使开发者能够实现高 CPU 性能。
⑧实时数据更新
ClickHouse 支持主键表。为了快速执行对主键范围的查询,数据使用合并树 (MergeTree) 进行递增排 序。由于这个原因,数据可以不断地添加到表中。
⑨支持近似计算
(很多组件不具备的)统计全中国到底有多少人?1434567654 14.3E PV 近似计算UV 具体的值 该库支持为有限数量的随机密钥(而不是所有密钥)运行聚合。在数据中密钥分发的特定条件下,这提供了相 对准确的结果,同时使用较少的资源。
⑩数据复制和对数据完整性的支持。
ClickHouse 使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副 本上保持相同的数据。数据在失败后自动恢复。 扩展成为分布式的数据库OLAP引擎,严重依赖于zookeeper 。
4.2、ClickHouse单机安装
(1)安装前准备
- CentOS7打开文件数限制
#在 /etc/security/limits.conf 这个文件的末尾加入一下内容:
sudo vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
#在 /etc/security/limits.d/90-nproc.conf 这个文件的末尾加入一下内容:
vim /etc/security/limits.d/90-nproc.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
#重启服务器之后生效,用 ulimit -n 或者 ulimit -a 查看设置结果
ulimit -n
ulimit -a
- CentOS7取消SELINUX
#修改 /etc/selinux/config 中的 SELINUX=disabled 后重启
vim /etc/selinux/config
SELINUX=disabled
- 关闭防火墙
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl start firewalld.service
- 安装依赖
yum install -y libtool
yum install -y *unixODBC*
(2)单机模式安装
ClickHouse的安装可以使用 yum在线安装,也可以使用 rpm 离线安装的方式! 具体信息见官网文档:https://clickhouse.tech/#quick-start
- 准备操作
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
- 下载安装包
#下载地址:https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
clickhouse-server.noarch.rpm
clickhouse-common-static.rpm
clickhouse-client.noarch.rpm

- 安装
rpm -ivh clickhouse-common-static-20.9.2.20-2.x86_64.rpm
rpm -ivh clickhouse-common-static-dbg-20.9.2.20-2.x86_64.rpm
rpm -ivh clickhouse-server-20.9.2.20-2.x86_64.rpm
rpm -ivh clickhouse-client-20.9.2.20-2.x86_64.rpm
- 启动服务端
#前台启动
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
#后台启动
nohup clickhouse-server --config-file=/etc/clickhouse-server/config.xml 1>~/logs/clickhouse_std.log 2>~/logs/clickhouse_err.log &

- 启动客户端
clickhouse-client
或者:
TZ=Asia/Shanghai clickhouse-client

- 基本使用
#1、创建库
create database test;
#2、切换库
use test;
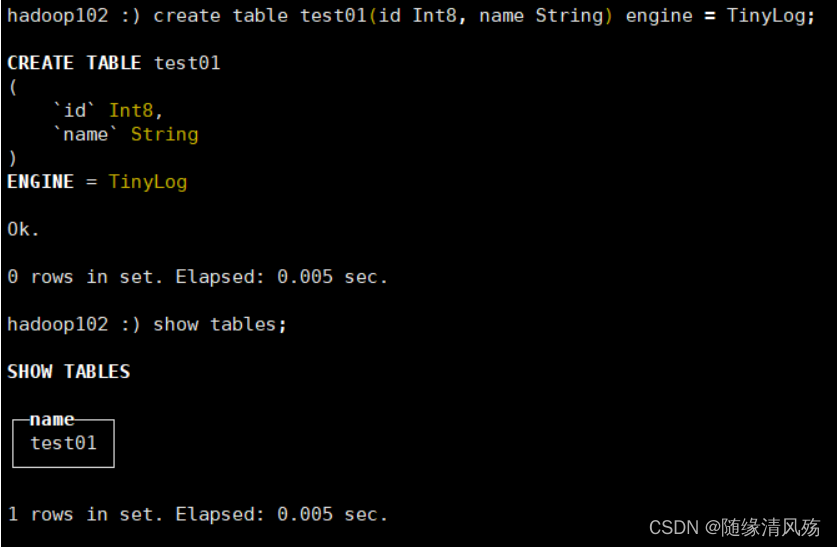
#3、创建表
create table test01(id Int8, name String) engine = TinyLog;
#4、查询表列表
show tables;
- 安装成功的核心目录
Ⅰ、/etc/clickhouse-server
服务端的配置文件目录,包括全局配置config.xml和用户配置users.xml 等。
Ⅱ、/var/lib/clickhouse**
默认数据存储目录,通常会修改默认路径配置,将数据保存到大容量磁盘挂 载路径
Ⅲ、/var/log/clickhouse-server
默认日志保存目录,通常会修改路径配置将日志保存到大容量磁盘 挂载的路径
- 可执行文件
Ⅰ、clickhouse:主程序的可执行文件。
Ⅱ、clickhouse-client:一个指向ClickHouse可执行文件的软链接,供客户端连接使用。
Ⅲ、clickhouse-server:一个指向ClickHouse可执行文件的软链接,供服务端启动使用。
Ⅳ、clickhouse-compressor;内置提供的压缩工具,可用于数据的正压反解。
附录:离散知识点
1、client连接拒绝
(1)报错
Connecting to localhost:9000 as user default.
Code: 210. DB::NetException: Connection refused (localhost:9000)
(2)解决方案
#systemctl启动
[root@tcloud ~]# systemctl start clickhouse-server.service
[root@tcloud ~]# systemctl status clickhouse-server.service















 3238
3238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











