







1、分布式文件系统
超级大型电脑=分布式文件系统

2、HDFS架构设计详述
2.1、HDFS1架构说明
- 定义:是一个主从式架构,主节点只有一个NameNode,从节点有多个DataNode
- NameNode:管理元数据信息,主要包括文件与Block块,Block块与DataNode主机的关系
- DataNode:以文件块形式存储数据(Hadoop1默认64M),每个文件块默认3个副本

-
注意事项:NameNode为了快速响应用户的操作请求,所以把所有文件相关元数据加载到内存中
-
HDFS1架构缺陷
- 单点故障:NameNode发生故障,那整个集群就会无法运行;
- 内存受限:
2.2、HDFS1单点故障解决方案 - HDFS2架构方案
- 解决方案:加一台NameNode,但是怎么加且看如下?
2.2.1、问题1:如何保持两个NameNode元数据一致?
- 解决方式:JournalNode集群

- 架构原理:采用JournalNNode集群进行元数据管理,JournalNNode集群本身没有单点故障问题
- NameNode(active):往集群中写入元数据信息
- Name(standby):读取集群数据
JournalNNode节点:
hadoop<200 3
hadoop>200 5
2.2.2、问题2:NameNode(active)挂了,如何自动切换到Name(standby)
- 解决方案:Zookeeper集群

- 架构原理:ZKFC负责检测NameNode的心跳,一旦挂掉就会将锁给到备用机
2.3、HDFS1内存受限解决方案 - HDFS3
- 解决方案:NameNode采用联邦制,支持多个NameNode。

-
架构原理:元数据文件在多组高可用NameNode存储,每组NameNode存储的元数据文件不同
-
应用场景
- 服务器<1000台,采取主备策略
- 服务器>1000台,采用联邦策略
3、HDFS支持亿级流量原理
3.1、亿级流量概述
NameNode管理了元数据,用户所有操作请求都要操作NameNode,大一点的平台一天运行需要几十万上百万的的任务,一个任务就有很多请求,所有NameNode的请求都打到NameNode这儿(更新目录树),对于NameNode就是亿级数据。
- 请求类型:创建文件,上传文件,读取文件等
3.2、原理&问题概述
①格式化HDFS,在磁盘上生成fsimage文件

②启动NameNode,将fsimage文件加载到内存中

③用户写数据将文件上传到集群,文件元数据信息增加到NameNode内存中,同时将操作会写入磁盘中的edit.log,之后将内存fsimage数据同步到磁盘的fsimage文件上

- 问题:内存的读写速度比磁盘要快,磁盘读写性能成为瓶颈
3.3、Editlog写机制之分段加锁&双缓冲机制
- 业务场景:在HA下,客户端的每一条事务都会首先写入缓冲区,然后近可能马上写入磁盘Editlog和journalNode(保证可靠性),即HDFS应该尽可能保证客户端写的写操作返回成功时,磁盘和JournalNode中Editlog中有该记录。

(1) 因为将记录互斥写入内存,等待时间较短,并且在写磁盘和网络时,不需要持有锁,不影响其他线程的互斥写内存。
(2)在某线程写磁盘和网络时,其他线程只要判断出其对应的事务已经在被写出了,则可以直接返回。
(3)两次获取到的锁是同一把锁,都是加在对象(FSEditLog)上的锁。第一次竞争锁为了互斥写缓冲,第二次竞争锁为了交换缓冲。
(4)通过上述的双缓冲和对线程2阶段加锁,大大提高了性能,并且可以保证返回成功时,该事务已在被写入磁盘和网络;类似于使用一个缓冲区来ack整个缓冲区中的事务,而不是对事务一个接一个ack。
3.4、Checkpoint机制概述
- 业务场景:NameNode宕机挂掉/重启之后,内存中的fsimage文件消失
- 重启后:重新加载磁盘中的fsimage文件,合并editlog文件到内存中

- SecondNameNode机制:合并NameNode的编辑日志,加快NameNode启动速度
- 作用:定时拉取NameNode的edit日志,与fsimage进行合并,并将合并编辑的文件传到NameNode上进行文件替换

4、基础平台版本选型
4.1、HDFS1.x版本主要特性
(1)已被淘汰
(2)Mapreduce同时处理逻辑运算和资源调度,耦合性比较大
4.2、HDFS2.7版本主要特性
(1)增加Yarn
Yarn负责 资源的调度,MapReduce
(2)主从NameNode
4.3、HDFS3.x版本主要特性
(1)联邦制
多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在hadoop 2.0中已经支持。
(2)纠删码
可以将3倍副本占据的空间压缩到1.5倍,并保持3倍副本的容错。由于在读取数据的时候需要进行额外的计算,用于存储使用不频繁的数据
5、PB级离线存储平台资源评估与架构设计
- 设计目标:以一个行业独角兽公司为例,1000台以内的服务器hold住背景下。
5.1、平台架构选型
(1)联邦 VS 主备选型原则
- 联邦:1000台以上:选择联邦制,即Hadoop3.x版本
- 优点:解决内存受限问题
- 主备:1000台以下:选择主备,即选择Hadoop2.7版本
- 优点:解决单点故障问题
(2)存储平台架构设计选型
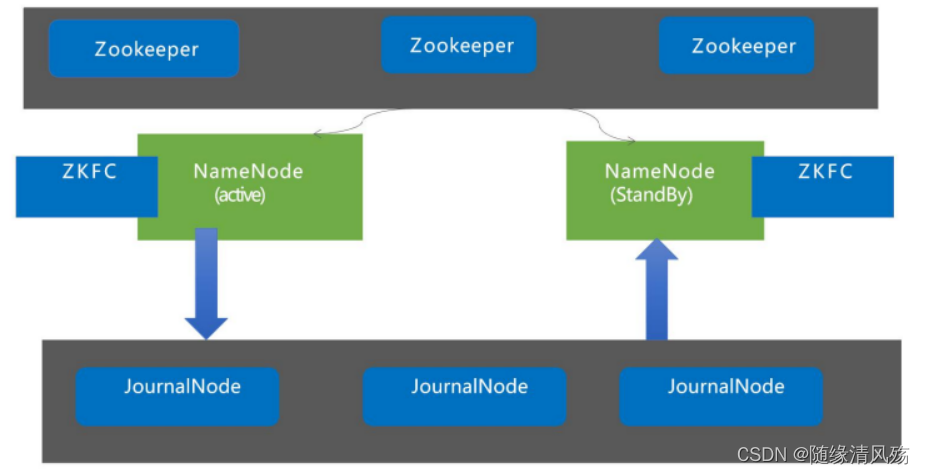
-
Zookeeper高可用:1000台以下建议五台,机器少则三台兜底
- 为什么:对HDFS的作用是XXX,重要度比较高
-
JournalNode高可用:1000台以下建议五台,500台以下建议三台。
- 为什么:本身架构设计优秀不太容易出问题,对HDFS作用是XXXX,重要性比较低。
-
HDFS高可用:NameNode两台
-
HDFS存储节点:DataNode数量根据具体情况评估。
5.2、网络设计
(1)机架网络硬件设计
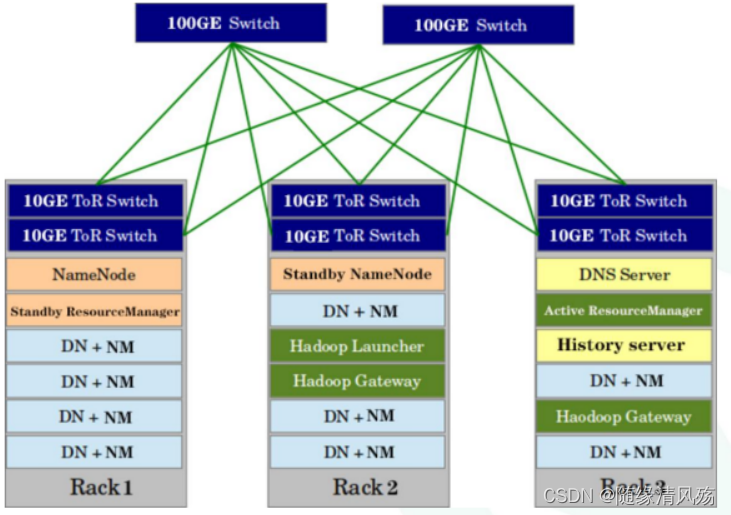
- Rack:表示是一个机架,同一个交换机下的服务器术语一个机架。
- 汇总交换机:两台,保证高可用
- 机架交换机:两台,保证高可用
- 机架网卡:两个,保证高可用
- 机架电源:两个,保证高可用
- HDFS设计:NameNode和Standby NameNode放在不同机架上
(2)机架网络感知设计
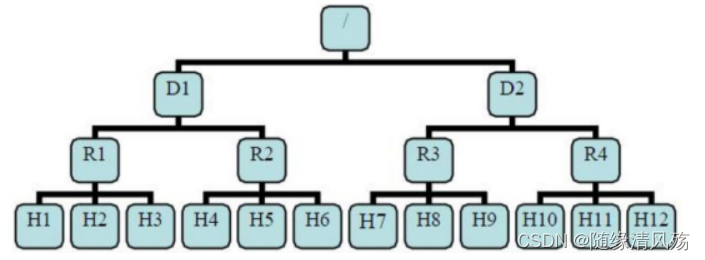
机架感知:自动连接hadoop集群中每台机器节点所属机架,告知hadoop那台机器属于哪个机柜,这样在hadoop的Namenode启动初始化时,会将这些机器与机柜的对应信息保存在内存中。
-
主要实现两个功能:
-
第一个功能:希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架。
-
第二个功能:为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。
-
(3)机架感知脚本实现
①编写RackAware.py脚本
机架感知需要人为进行配置,编写脚本进行机架感知相关工作,脚本位置(/usr/software/hadoop-2.7.3/sh)可自定义存放,注意要给脚本赋予可执行权限。
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {
"192.168.6.102":"SW6300-1",
"192.168.6.103":"SW6300-2",
"192.168.6.104":"SW6300-3",
}
if __name__=="__main__":
print "/" + rack.get(sys.argv[1],"SW6300-1-2")
- 赋予脚本可执行权限
chmod +777 topology.sh
- 将脚本分发到其他节点
xsync RackAware.py
③将脚本配置到hadoop的core-site.xml中
<!--配置机架感知脚本-->
<property>
<name>topology.script.file.name</name>
<value>/opt/module/hadoop-3.1.3/sh/topology.sh</value>
</property>
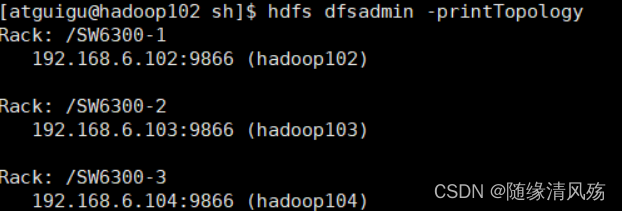
④重启后检查配置是否生效
hdfs dfsadmin -printTopology
- 查询结果
5.3、硬件选型
(1)CPU:推荐4路32核,主频至少2-2.5GHz。
(2)内存:推荐64~256GB,按照公司预算进行。
(3)磁盘:每台服务器分为系统盘和数据盘两组,系统盘2T*2(Raid1),数据盘2-10T左右(SSD、SAS)。
- 为什么数据盘不更高?比如30T或50T?
- 1、磁盘读写频率高,数据盘容易损坏,恢复数据量大导致恢复时间长
- 2、数据盘大随之而然数据量大导致读写速度慢,相同情况下分盘进行并行度读写也会速度较慢
- 固态硬盘和机械硬盘的选择?
- 重点看预算,预算选固态硬盘,预算选机械硬盘
(4)网卡:万兆网卡(光纤卡),或者更高
(5)电源:均配置冗余电源,有条件的可以具备发电能力。
(6)厂商选择:可选IBM、惠普、戴尔、浪潮…,根据公司采购利益选择。
5.4、Namenode和DataNode的JVM内存设置
(1)Namenode内存设置
将NameNode运行在一台独立的服务器上,要设置NameNode堆内存大小,可通过hadoop配置文件hadoop-env.sh中添加如下内容实现:
#用于Java heapsize的最大内存使用量
export HADOOP_HEAPSIZE_MAX=越大越好
#用于Java heapsize的最小内存使用量
export HADOOP_HEAPSIZE_MIN=越大越好
#注意事项;默认情况下,Hadoop将让JVM决定使用多少内存,默认数值单位为M。这个值可以被每个守护进程的_OPTS 变量覆写。例:设置HADOOP_HEAPSIZE_MAX=1g 和 HADOOP_NAMENODE_OPTS="-Xmx5g" ,此NameNode将配置具有5GB堆。
- NameNode JVM换算公式
在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1kw个小文件,每个文件占用一个block,则namenode需要2G空间。如果存储1亿个文件,则namenode需要20G空间。这样namenode内存容量严重制约了集群的扩展。
- 配置实战案例:master的机器总内存为16G,设置为16G*80%≈12GB
export HADOOP_NAMENODE_OPTS="-Xmx12g"
-
经验值1:NameNode堆内存大小设置为物理内存的80%,因为要加载元数据到内存中。
-
经验值2:1000台左右集群,每台服务器的磁盘为20*1T,每块硬盘使用率为80%~85%之间,NameNode的堆内存大小设置为128G左右能搞定。
-
经验值3:如果NameNode内存占用高,首先考虑进行小文件管理优化,之后再考虑加内存。
(2)DataNode内存设置
可通过hadoop配置文件hadoop-env.sh中添加如下内容实现:
export HDFS_DATANODE_HEAPSIZE=4096
#Datanode进程的JVM配置
export HDFS_DATANODE_OPTS="-Xms${HDFS_DATANODE_HEAPSIZE}m -Xmx${HDFS_DATANODE_HEAPSIZE}m"
- 配置实战案例:node的机器总内存为8G,设置4GB
export HDFS_DATANODE_HEAPSIZE=4096
- 经验值1:DataNode堆内存大小设置为4GB以上。4~8GB即可,将更多内存留给Yarn
5.5、HDFS的关键参数设置
(1)dfs.replication
此参数用来设置文件副本数,通常设为3,不推荐修改。这个参数可用来保障HDFS数据安全,副本数越多,越浪费磁盘存储空间,但数据安全性越高
(2)dfs.block.size
此参数用来设置HDFS中数据块的大小,默认为128M,所以,存储到HDFS的数据最好都大于128M或者是128的整 数倍,这是最理想的情况,对于数据量较大的集群,可设为256MB或者512MB。数据块设置太小,会增加 NameNode的压力。数据块设置过大会增加定位数据的时间。 (3)dfs.datanode.data.dir
这个参数是设置HDFS数据块的存储路径,配置的值应当是分布在各个独立磁盘上的目录,这样可以充分利用节点 的IO读写能力,提高HDFS读写性能。
(4)dfs.datanode.max.transfer.threads
这个值是配置datanode可同时处理的最大文件数量,推荐将这个值调大,最大值可以配置为6553。
5.6、存储资源预估(重点)
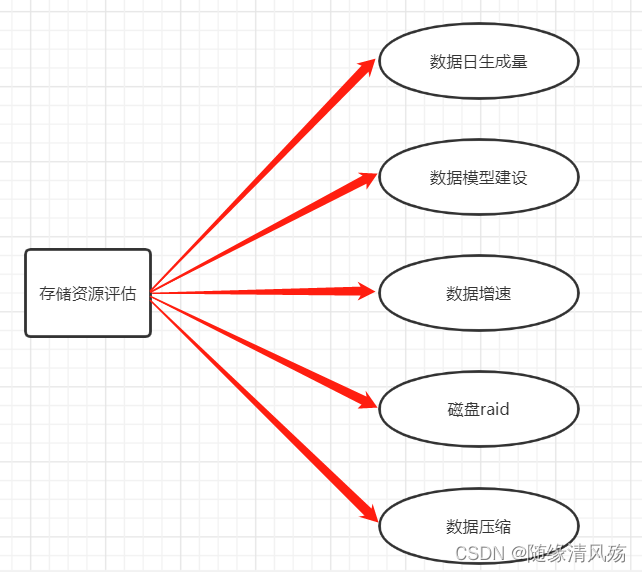
(1)每天9T,副本数为3,一年需要的存储资源:9 * 3 * 365 = 9855T
(2)数据需要进行加工(建模):9855 * 3 = 29565T
(3)数据增速是每年50%,29565 * (1.5)= 44347T
(4) 磁盘只能存到80%,故需要55434T的存储空间
(5)压缩比,按50%估算,故需要存储27717T 机器配置:32cpu core, 128G内存,11 * 7T
故:27717/77 = 359台服务

















 3047
3047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











