






Confident in the Crowd: Bayesian Inference to Improve Data Labelling in Crowdsourcing
作者
Pierce Burke and Richard Kleiny School of Computer Science and Applied Mathematics, University of the Witwatersrand, Johannesburg, South Africa Email: pburke1172@gmail.com, yrichard.klein@wits.ac.za
摘要
随着人们对机器学习和大数据问题的兴趣增加,对大量标记数据的需求也随之增加。然而,让专家给所有这些数据贴上标签往往是不可行的,这导致许多从业者采用众包解决方案。本文提出了在降低成本的同时提高标签质量的新技术。分配标签的天真方法是采用多数投票法,然而,在数据标签的上下文中,这并不总是理想的,因为数据标签并不同样可靠。取而代之的是,人们可以根据过去的表现,通过某种加权投票的方式,给予某些贴标人更高的优先权。本文研究了使用更复杂的方法,如贝叶斯推断,来测量标签的性能以及每个标签的可信度。我们提出的方法遵循一个迭代改进算法,该算法尝试使用最少的工人数量来获得所需的推断标签的置信度。本文利用模拟工人探讨了模拟二分类问题,并对提出的方法进行了验证。我们的方法在成本和准确性上都优于标准的投票方法,同时在群体内部出现分歧时保持更高的可靠性。
关键词:众包,最大可能,贝叶斯推断,跨等级协议,共识
1 介绍
大量的数据已经成为科学中许多不同领域不可分割的一部分,然而,数据本身并不总是有意义的,而且往往需要附加标签。由于数据的规模,通常不可能全部由一个人甚至一个小团队标记。出于这个原因,许多机器学习从业者正转向众包平台,以获得低成本的数据标签。众包已经被证明可以解决许多不同领域的问题[1]。Foody等人在一篇论文中展示了一个现实世界中众包何时有用的例子。[2] 他们在地理图像上使用志愿者标签来确定某些地区的土地覆盖率。ImageNET是一个由1400多万个标记图像组成的图像数据集,用于训练计算机视觉模型。ImageNET的很大一部分是通过一个名为Amazon Mechanical Turk的在线平台外包给在线员工的。
为了确保标签的质量不受单个工人能力的影响,要求多个工人为数据提供标签是有益的[4]。这就引出了这样一个问题:聚集这些工人标签以确定真正的标签的最佳方式是什么。从一组标签中确定真值标签的最常用方法之一是多数投票获得[4],[5]。虽然这种方法经常在许多场景中使用,但它暴露了一个问题,即必须使用许多工人来确保标签的质量不会受到不可靠工人的危害。
另一种试图解决不可靠工人问题的方法是基于某种可靠性度量对工人进行加权。确定新工人可靠性的一种常见方法是,给出一个我们已经知道真值的测试问题,并将其答案与我们知道的真值进行比较[6]。这种方法不能解释工人的可靠性可能发生的变化,也不能解释他们的“测试”问题不符合他们的特点。相反,一个更好的方法是不断地学习和更新关于工人的新信息。本文将探讨三种可能的方法来解决这些问题。第一种是加权多数投票方案,将工人的历史准确性作为他们回答的权重。另外两种方法是概率方法,根据工人的历史准确性,估计工人给出正确标签的概率。研究了最大似然和贝叶斯推断模型。工人的历史准确性是通过将他们的回答与大众的一致回答进行比较来判断的。
不同的方法是根据它们对二分类任务的正确标签预测的准确性来判断的。
本文的结构如下:第2节包括相关工作和在该领域提出的其他一些方法;第3节介绍了我们使用的方法和设计选择的公式,第4节介绍了结果。第5节总结了我们的发现,并介绍了未来的工作。
2 背景及相关工作
为了提高给定任务的标签质量,已经做了很多工作。在Jung和Lease[7]提出的一种方法中,使用了一个z-score度量来过滤不可靠的工人。在Kumar和Lease[8]提出的另一篇论文中,他们比较了单标签法、多数票的多标签法和朴素贝叶斯的多标签法,以提高标签的准确性。然而,本文假设系统知道工人的准确度。Tarasov等人[9] 研究了一种动态评估评工人可靠性的方法,特别是回归任务,他们认为该方法可以应用于不同类型的问题,如多分类。该方法认为该问题可以归结为一个多武装匪徒(multi-armed bandit)问题,需要在挖掘现有工人新工人技能和之间做出选择。也有一些论文将工人或标签建模为具有潜在变量的概率分布。然后使用期望最大化[10]–[12]优化分布参数。Raykar等人[10] 通过对工人的能力施加先验值来使用贝叶斯模型。然而,他们并没有使用完全的贝叶斯推断,而是从后验模型中获取一个点估计。在Foody等人提出的一篇论文中[2] 他们使用一种潜在的类别分析方法来估计工人所给标签的质量。
3 研究方法
A. Data
- 工人:本文中所有的工人和问题都是模拟的。该系统的建立使得每个工人都有一个唯一的正确回答给定问题的概率,这些概率中的每一个都是从正态分布中抽取的,任何小于零或大于一的样本都被舍入到零,并且一个来确保这是一个有效的概率。这些工人被认为属于三类人中的一类:相反、正常和专家。相反的概率来自平均值为15,标准差为5的正态分布。正常工人的概率是从平均值为60,标准差为15的分布中得出的,假设这个集合是最大的,同时工人能力之间的差异也是最大的。这就导致了这样一种情况:一些工人可以成为“隐藏”在集合中的专家。专家的概率来自平均值为85,标准差为5的正态分布。不同的模型并不知道这些潜在的可能性。系统知道专家库中的工人,但成本较高。询问专家的成本是询问工人成本的五倍,工人被视为单位成本——尽管这个超参数可以根据不同情况进行调整。
- 问题:为了模拟问题中的不同难度,为每个问题添加一个“难度”值。较高的难度等级将降低正常/专家工人获得正确答案的概率,并降低相反工人获得错误答案的概率。这是基于这样一种假设:敌对的员工试图通过回答他们认为不正确的事情来产生误导性的结果。硬问题的概率上限为50%,因为这表示工人完全在猜测。用于模拟问题集的难度值集是从具有不同均值和标准差15的正态分布中提取的。
- 可用工作人员:为了模拟人员的不同可用性,整个工作人员池并非始终可用。相反,系统将为每个问题接收随机生成的可用工作人员子集,他们可以在标签上查询这些工作人员中的任何一个进行分类。如果每一个问题都有完整的工人集,那么包含一个偶尔使用非最优工人的方法将是有益的,以确保我们探索所有工人的能力。
B. 多数投票
第一种方法是普通多数票。对于每个问题,一组可用的工人被要求给出一个标签,然后通过选择出现最多的标签来组合回答。为了避免平票的可能性,只询问了奇数名工人。
C. 加权多数投票
加权多数投票法试图提高准确性,通过更好的工人加权更高。每个工人的权重是根据工人先前达成的一致回答计算的。根据一组预测和工人权重计算标签L,可通过以下公式给出:
L
=
s
g
n
(
∑
i
v
i
∗
w
i
)
.
(1)
L=sgn(\sum_i v_i*w_i).\tag{1}
L=sgn(i∑vi∗wi).(1)
其中
v
i
∈
[
0
,
1
]
v_i\in[0,1]
vi∈[0,1]表示第
i
i
i个工人的权值,
w
i
∈
−
1
;
1
w_i\in{-1;1}
wi∈−1;1表示第
i
i
i个工人的预测,sgn是符号函数。(1)将返回-1或1的标签L。我们通过估算工人的准确度来计算
v
i
v_i
vi,这是基于他们对一致回答的认同程度。对于给定的工人
i
i
i,相应的权重可以计算为:
v
i
=
c
i
N
i
,
(2)
v_i=\frac{c_i}{N_i},\tag{2}
vi=Nici,(2)
其中
c
i
c_i
ci表示工人
i
i
i同意先前一致回答的工人的问题数,
N
i
N_i
Ni表示我已回答的工作人员的问题总数。
D. 期望最大化算法
在前一种方法中,我们的工人的预期精度被用来衡量他们的权重。然而,这可以通过考虑工人给出标签 w i ∈ 0 , 1 w_i\in{0,1} wi∈0,1的可能性扩展到更具概率的方法,前提是真实标签为L=1。为了模拟工人的可能性,我们将使用伯努利分布。然而,工人给出正确分类概率的潜在变量在开始时是未知的。相反,最大似然的参数可以在每次迭代时使用期望最大化(EM)算法来近似。EM算法包括两个步骤,一个是使用当前估计参数计算标签的期望步骤,另一个是基于先前数据和期望步骤添加的新数据点更新参数的最大化步骤。然后,对每个新问题重复这两个步骤,以便系统能够了解更多关于工人的信息,因为每个工人都回答了更多的问题。这个版本的EM与[10]-[12]中使用的方法不同,因为我们的实现使用EM在向工人提出新问题后迭代地了解他们,并且以前的工作优化了一组已经可用的任务标签。
我们有两个假设:
- 工人们是独立的
- 属于每个类别的标签的先验概率是一致的,即 P ( L = 1 ) = P ( L = 0 ) P(L=1)=P(L=0) P(L=1)=P(L=0)。
让
λ
i
\lambda_i
λi为工人
i
i
i将提供正确标签的概率。因此,
P
(
w
i
=
L
)
=
λ
i
1
−
∣
w
i
−
L
∣
(
1
−
λ
i
)
∣
w
i
−
L
∣
,
(3)
P(w_i=L)=\lambda_i^{1-|w_i-L|}(1-\lambda_i)^{|w_i-L|},\tag{3}
P(wi=L)=λi1−∣wi−L∣(1−λi)∣wi−L∣,(3)
则
P
(
w
i
=
1
)
=
λ
i
w
i
(
1
−
λ
i
)
1
−
w
i
,
(4)
P(w_i=1)=\lambda_i^{w_i}(1-\lambda_i)^{1-w_i},\tag{4}
P(wi=1)=λiwi(1−λi)1−wi,(4)
P
(
w
i
=
L
)
=
λ
i
1
−
w
i
(
1
−
λ
i
)
w
i
,
(5)
P(w_i=L)=\lambda_i^{1-w_i}(1-\lambda_i)^{w_i},\tag{5}
P(wi=L)=λi1−wi(1−λi)wi,(5)
其中 w i w_i wi是工人的回答,而 L L L是正确的标签。这假设工人有同样可能提供正确的标签,而不考虑真实的标签。在(4)和(5)中使用单独的伯努利分布可以很容易地放松这一假设。
在多个独立问题上,
λ
i
\lambda_i
λi的最大似然估计为:
λ
i
=
c
i
N
i
,
(2)
\lambda_i=\frac{c_i}{N_i},\tag{2}
λi=Nici,(2)
其中 c i c_i ci表示工人 i i i同意一致意见的工人次数, N i N_i Ni表示工人 i i i回答问题的总数[13]。
这个问题在真正的标签值周围表现出对称性。因此,在不丧失一般性的情况下,我们考虑真实标签为1的问题。
贝叶斯规则产生:
P
(
L
=
1
∣
w
i
.
.
.
I
)
=
P
(
w
i
.
.
.
I
∣
L
=
1
)
P
(
L
=
1
)
∑
k
=
0
1
P
(
w
i
.
.
.
I
∣
L
=
k
)
)
P
(
L
=
k
)
.
(7)
P(L=1|w_{i...I})=\frac{P(w_{i...I}|L=1)P(L=1)}{\sum^1_{k=0}P(w_{i...I}|L=k))P(L=k)}.\tag{7}
P(L=1∣wi...I)=∑k=01P(wi...I∣L=k))P(L=k)P(wi...I∣L=1)P(L=1).(7)
假设1允许工人之间的联合概率变为概率的乘积。
P
(
L
=
1
∣
w
i
.
.
.
I
)
=
∏
i
=
0
I
P
(
w
i
∣
L
=
1
)
P
(
L
=
1
)
∑
k
=
0
1
P
(
w
i
.
.
.
I
∣
L
=
k
)
)
P
(
L
=
k
)
.
(8)
P(L=1|w_{i...I})=\frac{\prod_{i=0}^{I}P(w_i|L=1)P(L=1)}{\sum^1_{k=0}P(w_{i...I}|L=k))P(L=k)}.\tag{8}
P(L=1∣wi...I)=∑k=01P(wi...I∣L=k))P(L=k)∏i=0IP(wi∣L=1)P(L=1).(8)
假设2意味着分子和分母中的先验概率相互抵消。这给出了
P
(
L
=
1
∣
w
i
.
.
.
I
)
=
∏
i
=
0
I
P
(
w
i
∣
L
=
1
)
∏
i
=
0
I
P
(
w
i
∣
L
=
1
)
+
∏
i
=
0
I
P
(
w
i
∣
L
=
0
)
.
(9)
P(L=1|w_{i...I})=\frac{\prod_{i=0}^{I}P(w_i|L=1)}{\prod_{i=0}^{I}P(w_i|L=1)+\prod_{i=0}^{I}P(w_i|L=0)}.\tag{9}
P(L=1∣wi...I)=∏i=0IP(wi∣L=1)+∏i=0IP(wi∣L=0)∏i=0IP(wi∣L=1).(9)
其中 w i w_i wi是工人 i i i提供的标签。
方程(9)给出了计算标签可能性的概率公式。后验允许我们测量与每个标签相关的置信度,并根据我们当前的一组工人提供的标签进行计算。然后,只有当置信度低于某个阈值时,才能使用此置信度通过添加更多的工作者来确定每个问题需要多少个工作者。算法1给出了回答单个问题的过程。
考虑到我们的工人的回答,标签正确的置信度,用
ω
n
\omega_n
ωn表示计算方法:
ω
n
=
∣
P
(
L
=
1
∣
w
i
.
.
.
I
)
−
(
1
−
L
)
∣
,
(10)
\omega_n=|P(L=1|w_{i...I})-(1-L)|,\tag{10}
ωn=∣P(L=1∣wi...I)−(1−L)∣,(10)
其中
w
i
.
.
.
I
w_{i...I}
wi...I是从每个工人返回的所有标签的集合,
L
L
L是系统根据计算的概率选择的标签。上面的公式将计算每个标签的概率与预测标签的接近程度。

算法1:迭代标签改进
这提供了一种方法,通过根据需要添加更多需要的工人而不是使用所有可用的工人来迭代地改进答案。
E. 贝叶斯推断
在上面讨论的最大似然方法中,使用
λ
i
\lambda_i
λi的点估计来对每个工人建模。这可能会导致对基于先前看到的数据的工人技能度量的过度自信。为了减少这种过度拟合对初始数据的影响,可以使用更保守的方法,例如贝叶斯推断。在这种情况下,我们引入了对工人可能性的优先考虑。为了简化概率密度的计算,我们使用β分布,它与伯努利分布共轭[13]。可通过以下方式给出:
P
(
w
i
∣
L
=
1
)
=
∫
1
0
B
e
r
n
w
i
[
λ
i
]
B
e
t
a
λ
i
[
α
i
,
β
i
]
d
λ
i
.
(11)
P(w_i|L=1)=\int_{1}^{0}Bern_{w_i}[\lambda_i]Beta_{\lambda_i}[\alpha_i,\beta_i]d\lambda_i.\tag{11}
P(wi∣L=1)=∫10Bernwi[λi]Betaλi[αi,βi]dλi.(11)
由于贝努利分布和β分布之间的共轭关系(11)可以简化为[13]:
P
(
w
i
∣
L
=
1
)
=
Γ
[
α
i
+
β
i
]
Γ
[
α
i
+
w
i
]
Γ
[
1
−
w
i
+
β
i
]
Γ
[
α
i
]
Γ
[
β
i
]
Γ
[
α
i
+
β
i
+
1
]
.
(12)
P(w_i|L=1)=\frac{\Gamma[\alpha_i+\beta_i]\Gamma[\alpha_i+w_i]\Gamma[1-w_i+\beta_i]}{\Gamma[\alpha_i]\Gamma[\beta_i]\Gamma[\alpha_i+\beta_i+1]}.\tag{12}
P(wi∣L=1)=Γ[αi]Γ[βi]Γ[αi+βi+1]Γ[αi+βi]Γ[αi+wi]Γ[1−wi+βi].(12)
将(12)代入(9)给出了真标签的可能性,该真标签可以用与前一种方法相同的方法计算预测标签。
在(12)中, α \alpha α和 β \beta β可以解释为描述 λ i \lambda_i λi上概率分布的先验参数,即工人正确分配标签的概率。这使得系统能够跟踪对每个工人技能的估计的置信度。 α \alpha α相对于 β \beta β越大,Beta分布的期望 λ i \lambda_i λi就越大。
为了使系统能够在工人回答问题时了解更多关于工人的信息,应在每个工人回答更多问题时更新
α
\alpha
α和
β
\beta
β参数。从上述方程式可以看出,第n个问题的
α
\alpha
α和
β
\beta
β分别为
α
+
∑
i
=
1
n
−
1
c
i
\alpha+\sum_{i=1}^{n-1}c_i
α+∑i=1n−1ci和
β
+
∑
i
=
1
n
−
1
(
1
−
c
i
)
\beta+\sum_{i=1}^{n-1}(1-c_i)
β+∑i=1n−1(1−ci),如果工人同意就问题
i
i
i和0达成共识,则
c
i
=
1
c_i=1
ci=1。通过为每个工人存储
α
\alpha
α和
β
\beta
β,并在他们回答每个问题后更新,这可以转换为更新规则。
α
n
+
1
=
α
n
+
c
n
(13)
\alpha_{n+1}=\alpha_n+c_n\tag{13}
αn+1=αn+cn(13)
β
n
+
1
=
β
n
+
1
−
c
n
(14)
\beta_{n+1}=\beta_n+1-c_n\tag{14}
βn+1=βn+1−cn(14)
同样,我们假设问题是对称的,即不管真正的标签是0还是1,工人的技能都是一样的。之所以做出这种假设,是因为我们试图对没有类比其他类更难标记的一般情况进行建模。如果不是这样,则应为每个案例分别建模先前的参数。
该方法与最大似然情形下的期望最大化方法相同,只是更新了Beta分布的先验参数,而不是 λ i \lambda_i λi的点估计。
F. 带置信度更新的贝叶斯推理
可以通过改变(13)和(14)中
α
\alpha
α和
β
\beta
β 参数的更新规则来调整上述方法。更新不使用二进制值1或0进行更新,而是可以包含有关系统在该标签中的置信度的信息。这允许对存在大量分歧或不确定性的标签进行小的调整,也允许根据具有高度信心的标签进行大的调整。更新规则随后变为:
α
n
+
1
=
α
n
+
ω
n
c
n
(13)
\alpha_{n+1}=\alpha_n+\omega_nc_n\tag{13}
αn+1=αn+ωncn(13)
β
n
+
1
=
β
n
+
ω
n
(
1
−
c
n
)
(14)
\beta_{n+1}=\beta_n+\omega_n(1-c_n)\tag{14}
βn+1=βn+ωn(1−cn)(14)
其中 ω n \omega_n ωn在(10)中给出.
4 实验
在本节中,我们将讨论一些我们从测试中获得的结果。从这里开始,这些方法将表示为MV代表多数票,加权代表多数票,EM代表最大似然法,BAY代表标准贝叶斯推理法,CONF代表带置信更新规则的贝叶斯推理法。实验中测量的成本与每个问题使用了多少工人有关。使用一个工人的成本是1,使用一个已知的专家的成本是5。图中的阴影区域表示不同实验之间结果的差异。
A. 问题的数量
在这个实验中,我们测试了当工人被问到更多的问题时,不同的方法是如何发展的。置信阈值固定为0.9,工人人数固定为35,工人优先级固定为0.6(对于贝叶斯方法,我们将β分布平均值设置为0.6)。这意味着系统期望工人对于难度值为0的问题的平均精确度为0.6。
从图1可以看出,所提出的方法在成本和准确性上都优于多数投票方法。多数票执行的平均准确率为71%,平均每个问题的成本为21。加权多数投票使成本大致相同时的准确率提高到78%。这两种方法的成本存在差异的原因是多数票只使用奇数工人,而加权多数票方法将使用所有工人。与加权多数投票相比,概率方法有更大的改进,最差的一个表现得更好,最好的一个平均提高了10%。然而,概率方法比常规投票方法提供的一个主要优点是改进的平均成本。从同一个数字可以看出,随着工人被问到更多的问题,概率方法的成本有下降的趋势,这可以归因于这样一个事实:这些模型随着被问到更多的问题而了解更多的工人,并且他们有一种方式来判断他们对自己的答案有多自信。在三种概率方法中,两种贝叶斯推理模型的平均代价都高于最大似然法,这说明它们对工人的信念更为保守,而置信更新规则法最为保守。这种保守态度导致他们在每个问题上都会问更多的工人,以达到信任阈值。由于最大似然法的保守性较低,其结果存在较大的方差。这可以通过较大的阴影区域看到。
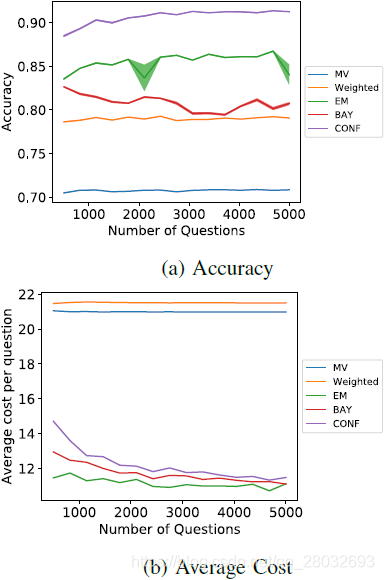
图1:试题数量测试
B. 置信阈值
针对这一测试,探讨了不同置信阈值对概率方法的影响。每个模型的任务是回答2000个问题,其余参数与上一次测试相同。
在图2中可以看出,当置信阈值设置为0.5时,概率方法的性能甚至比多数票和加权多数票差。置信度值为0.5意味着每个标签对于我们的工人标签来说都是一样的。这就使得概率方法可以获取初始工作集给它们的任何标签。当β分布的
α
\alpha
α和
β
\beta
β参数相对变化很小时,带置信更新的贝叶斯推断显示了低置信阈值的最低结果。从图中可以得到一个有趣的结果:当置信阈值接近1时,两个贝叶斯推理模型的准确度趋于对方。这很可能是因为随着平均置信度的增加,这两种方法的参数更新规则变得更加相似。如果我们看看置信度始终为1的极端情况,那么更新规则将是等价的。提高置信阈值对所需成本产生了重大影响,最大似然法要求的成本高于多数票和加权多数票。从这些结果可以看出,对于需要较低置信度的任务,使用标准贝叶斯推理更新规则或最大似然模型更为有利,当需要较高置信度时,切换到置信度更新规则更为有利。

图2:置信阈值检验
C. 难度
本实验比较了问题难度对每种方法的准确性和成本的影响。在我们的系统中,我们通过增加或减少工人返回正确标签的概率来模拟问题的不同难度。当难度为负时,返回正确答案的概率将增加,如果为正,则返回正确答案的概率将降低(如果工人是恶意的,则返回正确答案的概率将相反)。标准工人的概率变化不会低于50%,而恶意工人的概率变化不会高于50%。这个测试的难度在-15和15之间变化,分别代表更容易和更难的问题。
从图3可以看出,当每个问题的平均难度增加时,所有方法都变得不太准确。然而,值得注意的是,对于这两种贝叶斯推理方法来说,由于它们不会很快失去准确性,因此对难度的增加更具鲁棒性。这可能是因为更难的问题迫使系统使用更多的工人来保持所需的置信度。概率方法意识到系统中存在更多分歧的能力,使概率方法比投票方法更具优势。它允许模型控制需要使用多少工人来保持信心,这允许在问题更容易时使用更便宜的标签,并在标签存在更多不确定性时权衡低成本和更高精度。在这里加入信心可以在更大范围的困难上提供更可靠的标签。我们可以看到,对于更简单的问题,5种方法的表现是相似的,但随着问题变得更难,概率方法和投票方法之间的区别变得很明显。

图3:平均难度测试
D. 对抗性工人
在本实验中,研究了增加对抗性工作人员的效果。恶意的数量从0到40不等,其中40名正常工人和5名专家也在工人队伍中。
在图4中,我们可以看到不同的方法对那些积极试图破坏系统的工人的反应。最大似然法和带置信更新规则的贝叶斯推理即使当工作池由大约35%的敌对工作人员组成时,也能保持其准确性。这5种方法中最糟糕的是加权多数票,随着对手数量的增加,加权多数票迅速下降,当对手占系统的30%左右时,加权多数票的准确率低于多数票模型。投票方法成本的增加可以归因于增加更多的对手而增加了员工人数。值得注意的是,随着对手数量的增加,概率方法在多个测试运行中的结果方差大大增加。这表明这些方法中的标签质量变得更加不稳定,尽管它们通常仍然优于投票方法。
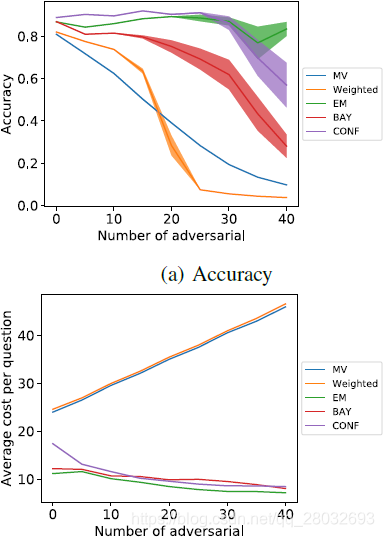
图4:对抗性测试
5 结论和今后的工作
众包在许多数据驱动领域是一个非常宝贵的工具。由于工人协议之间的差异,我们常常必须为每个任务使用多个工人。大多数人的投票结果最差,因为他们所探索的所有方法都只在最容易的问题上保持了与其他方法相竞争的准确性。加权多数投票法虽然在一定程度上提高了投票效率,但仍存在着多数投票成本过高的问题。
在三种概率方法中,具有置信更新规则的贝叶斯推理具有最高的平均精度,但平均代价略高。不同的方法平均成本趋于收敛,因为更多的问题被问到,使得贝叶斯推理与置信更新规则有用的情况下,我们一贯使用相同的工人集来回答问题。在其他情况下,当工人只被用于一小部分问题时,期望最大化方法以其较低的平均成本将更为有益。
未来的工作应该集中在测试真实世界数据的方法上,放松对问题的一些限制,比如工人和问题的独立性,并将系统扩展到非二元分类问题。
参考文献
[1] D. C. Brabham, “Crowdsourcing as a model for problem solving: An introduction and cases,” Convergence, vol. 14, no. 1, pp. 75–90, 2008.
[2] G. M. Foody, L. See, S. Fritz, M. Van der Velde, C. Perger, C. Schill, and D. S. Boyd, “Assessing the accuracy of volunteered geographic information arising from multiple contributors to an internet based collaborative project,” Transactions in GIS, vol. 17, no. 6, pp. 847–860, 2013.
[3] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition. Ieee, 2009, pp. 248–255.
[4] V. S. Sheng, F. Provost, and P. G. Ipeirotis, “Get another label? improving data quality and data mining using multiple, noisy labelers,” in Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2008, pp. 614–622.
[5] R. Snow, B. O’Connor, D. Jurafsky, and A. Y. Ng, “Cheap and fast— but is it good?: evaluating non-expert annotations for natural language tasks,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2008, pp. 254–263.
[6] J. Le, A. Edmonds, V. Hester, and L. Biewald, “Ensuring quality in crowdsourced search relevance evaluation: The effects of training question distribution,” in SIGIR 2010 Workshop on Crowdsourcing for Search Evaluation, vol. 2126, 2010, pp. 22–32.
[7] H. J. Jung and M. Lease, “Improving consensus accuracy via z-score and weighted voting,” in Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, 2011.
[8] A. Kumar and M. Lease, “Modeling annotator accuracies for supervised learning,” in Proceedings of the Workshop on Crowdsourcing for Search and Data Mining (CSDM) at the Fourth ACM International Conference on Web Search and Data Mining (WSDM), 2011, pp. 19–22.
[9] A. Tarasov, S. J. Delany, and B. Mac Namee, “Dynamic estimation of worker reliability in crowd-sourcing for regression tasks: Making it work,” Expert Systems with Applications, vol. 41, no. 14, pp. 6190–6210, 2014.
[10] V. C. Raykar, S. Yu, L. H. Zhao, G. H. Valadez, C. Florin, L. Bogoni, and L. Moy, “Learning from crowds,” Journal of Machine Learning Research, vol. 11, no. Apr, pp. 1297–1322, 2010.
[11] J. Whitehill, T.-f. Wu, J. Bergsma, J. R. Movellan, and P. L. Ruvolo, “Whose vote should count more: Optimal integration of labels from labelers of unknown expertise,” in Advances in Neural Information Processing Systems, 2009, pp. 2035–2043.
[12] W. Tang and M. Lease, “Semi-supervised consensus labeling for crowdsourcing,” in SIGIR 2011 Workshop on Crowdsourcing for Information Retrieval (CIR), 2011, pp. 1–6.
[13] S. Prince, Computer Vision: Models Learning and Inference. Cambridge University Press, 2012.














 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









