






Truth Inference, Is the problem solved?
(文献阅读和理解,欢迎评论区一起讨论和分享)
abstract
众包解决计算机中的问题:情感分析和实体解析。
- 实体解析又称为实体匹配,是指从给定的两张关系表中找出所有代表相同实体的元组。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-thOjzI7e-1667897579630)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221025174940284.png)]
众包的开放性,会导致低质量的答案,所以采用冗余的方法,根据多个答案推断出正确答案。
目前的真值推理算法并没有统一框架,所以难以选择合适的算法,通过五个真实数据集进行了17种算法的调研。
###introduction
现有的公共众包平台:
Amazon Mechanical Turk(AMT)【2】
CrowdFLower【12】
众包数据库:
CrowdDB【20】
Deco【39】
Qurk【37】
众多相关算法研究:
Join、Max、Top-K、Group-by
相关背景
- Majority Voting(多数投票,MV)
- 局限在于把所有工人都视为平等的。现实中工人的素质和专业水平是参差不齐的。所以针对mv算法能够捕捉每个工人的素质是很重要的。更好的推断真相,更多的相信高素质工人的答案。
- 由于工作情况未知,所以难评估,针对这种问题,一般使用黄金任务来评估员工质量。
- 第一种是资格考试,在完成任务之前进行一组黄金任务,素质评判据此来得分。
- 第二种是隐藏测试,黄金任务混杂在任务中,其素质根据隐藏的黄金任务来判断。
- 黄金任务存在的问题:
- 资格考试的话工人需要无偿回答额外任务,不愿意。
- 隐藏测试,支付额外任务是浪费。
- 这两种技术可能不会提高质量。
- 数据挖掘和数据库社区针对该问题进行了一系列算法构建,不过算法没有在同一实验标准下比较,本文根据任务类型、任务建模、工作者建模和推断技术来判断。
主要贡献
- 对17种算法进行概述,总结了一个框架,不同角度对算法进行了深入的分析和总结,帮助理解和掌握真值推理算法。
- 五个大小不同的真实数据集上进行实验比较,公布了代码和数据集(然而链接失效了),提供了实验结果,为各种场景下选择适当的方法提供了指导。
- 发现truth inference问题没有完全解决,提出局限性和展望。
###2 Problem Definition
Definition 1: Task
任务集T种包含n个任务,每个任务要求员工去回答。
T = { t 1 , t 2 , … , t n } T = \{t_1, t_2,\ldots,t_n\} T={t1,t2,…,tn}
有三种类型
-
**决策任务 **
- 工人决定T or F
- 例子如下:从表1中找到引用相同现实世界实体的产品对。六个决策任务,
T
=
{
r
1
=
r
2
,
…
,
r
2
=
r
4
}
T=\{r_1=r_2, \ldots,r_2=r_4\}
T={r1=r2,…,r2=r4}
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QHEuEtl9-1667897579631)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221021174426847.png)]
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XIgKx1aQ-1667897579632)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221021180931971.png)]
-
单选(多选)任务
-
例如情绪分析中(单选)
- 积极、中立、消极
-
图像标记中,给定图像的一组候选标记,它要求工作人员选择图像包含的标记。(多选)
-
多项选择很容易转换为决策任务【60,38】
- 例如:**一个图像标记任务(多项选择),每个转换后的决策任务都询问图像中是否包含一个标签。**因此,决策任务中的方法可以直接扩展到多项选择任务的处理。
-
单选任务的研究:【34,16,15,53,41,61,35,30,27,46,5】
-
-
数字任务
- 询问珠穆朗玛峰的高度,输入的是number,且有固定顺序
-
其他(开放的任务、质量更难控制)
- 语言翻译
- 收集数据(名人的名字等)
Definition 2 Woker
工人
W
=
{
w
1
,
w
2
,
…
,
w
n
}
W=\{w_1,w_2,\ldots, w_n\}
W={w1,w2,…,wn},
w
i
w^i
wi表示完成任务ti的工人集合,
T
w
T^w
Tw表示已完成任务w的工人集合
Definition 3 Answer
答案 V = { V i w } V=\{V_i^w\} V={Viw},每个任务 t i t_i ti都可以用w中的一个工人子集来回答。设 V i w V_i^w Viw表示工人w对任务ti的回答V,中包含所有任务中收集的工人的回答。
Definition 4 Truth
truth 答案 v i ∗ v_i^* vi∗ 就是每个任务 t i t_i ti都有一个真实的答案。真值推理问题就是基于v为每个任务 t i t_i ti推断出真理 v i ∗ v^*_i vi∗
Definition 5 Truth Inference In Crowdsourcing
众包中真值推理就是给定工人的答案V,然后推断出每个 t i t_i ti的真值 v i ∗ v_i^* vi∗
所有参数值介绍
3 解决方案框架
- MV方法
- 根据表二的结果知道,如果按照MV的话结果并不太好,给与w3较高信任的话会得到更好答案。
- 实际上由于工人素质不一
- 有的是专家或普通工人
- 有的是垃圾邮件制造者(为了骗钱而随机回答任务)
- 有的是恶意工作者(故意给出错误的答案)
- 实际上由于工人素质不一
- 提出了对工人素质建模的一系列方法【16,15,53,51,41,33,26,61,62,19,35,30,46,27,5,34】,都需要事先给任务贴上真实的标签,而且需要回答“额外”任务。
- 为了解决上一条中的问题,已有的文献有【16,15,53,51,41,33,26,61,62,19,35,30,46,27,5,34】根据V来估计素质。
- 根据表二的结果知道,如果按照MV的话结果并不太好,给与w3较高信任的话会得到更好答案。
- 通过捕捉素质,高质量员工给出答案很可能是真理。如果经常正确回答任务,会被分配到高质量工作,通过这种迭代,共同推出工人素质和任务的真实性。
- 通过捕捉该关系,算法1显示了现在所用的一般方法。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7vSTA6rD-1667897579632)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221021182332381.png)]
- 步骤:
- 推测真值(员工回答和素质推断,还有针对不同任务的建模)
- 评估工人质量(建模)
- 根据工人的回答和每个人物的真值来评估工人质量
- 收敛
- 两个迭代一直运行到收敛(质量和任务真实性两组参数是否低于阈值)
- PM方法的例子
- PM方法【31,5】,为每个工人w建模 q w q^w qw,值越大越好。一开始都相同,然后执行两步:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eZaTAE2F-1667897579633)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221021182938155.png)]
- 通过此能得出正向结果( q w 3 = 16.09 q^{w_3}=16.09 qw3=16.09)
4 重要因素
现有研究按照以下两个因素进行分类:任务建模、工人建模
任务建模
- 现有研究【16,15,53,51,41,33,26,61,62,19,35,30,46,27,5,34】如何模拟任务(任务难度、潜在主题)
-
任务难度
- 与大多数现有的研究不同的是,这些研究假设一个工作者有完成不同任务的相同能力
- 最近研究【53,35】假设每个任务都有难度级别,对其建模
-
潜在主题
- 每个任务建模为一个带有K值的向量,利用任务得不同主题来进行编号。
- 任务模型——》如果工人对相关主题有较高素养,那么正确回答概率就高。
-
思考:
- 任务难度的话可以针对任务类型进行任务难度建模
- 主题的话感觉可以按照九种类型进行划分
-
####工人建模
- 现有工作模拟工人素质(工人概率、多样化技能)
-
工人概率
- 工人 w w w的概率用 q w q^w qw来表示(0~1之间), q w q^w qw越高,回答能力越强。在现有工作中【16,26,33,5】已经应用。
-
混淆矩阵
-
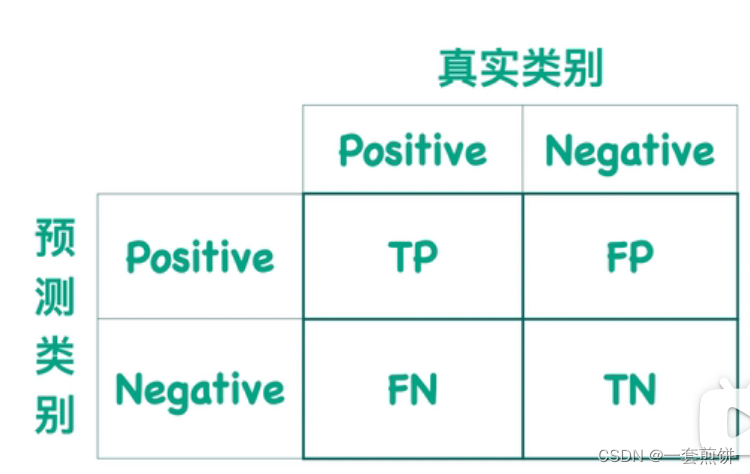
- 用于模拟工人在回答单一选择任务时的质量。
- 举个例子:对于一个决策任务让工人去选择T或F,然后这个混淆矩阵对于w来说就是KaTeX parse error: \tag works only in display equations, q 1 , 2 w = 0.2 q^w_{1,2} = 0.2 q1,2w=0.2就意味着任务的答案是T,w回答F的概率是0.2
-
-
工人偏差和工人方差
- 偏差和方差用于处理数字任务,偏差捕捉了工作者可能低估或高估任务真相的影响,方差捕捉了偏差周围的误差变化。
- 例如给一组人的照片,让估计人的身高。工人 T w → 0 T_w\rightarrow 0 Tw→0意味着更高的准确,$\sigma \rightarrow 0 $意味着误差小。
-
自信心
- 回答大量任务,评估质量有自信。赋予完成大量任务的员工更高的品质。
-
多样的技能
- 工人对不同主题有不同程度的专业知识。现有模型捕捉了完成不同工作的素质。对w的质量建模,即 q w = [ q 1 w , q 2 w , … , q n w ] q^w = [q_1^w, q_2^w,\ldots,q_n^w] qw=[q1w,q2w,…,qnw], q i w q_i^w qiw代表w对任务 t i t_i ti的质量。最近的研究是 q w = [ q 1 w , q 2 w , … , q n w , q K w ] q^w = [q_1^w, q_2^w,\ldots,q_n^w, q_K^w] qw=[q1w,q2w,…,qnw,qKw],其中K是预先定义的,表示的是潜在主题的数量。假设每个人物都与这K个主题或其中一个主题有关,如果w在该任务相关主题有较高的质量,就很可能正确回答任务。
-
5 真值推理算法
- 现有的工作通常采用算法1中的框架,根据所用技术可被分为:直接计算、优化方法、概率图模型法三大类。
直接计算
- 基本方法是没有工作和任务建模。对于任务决策任务和单选任务,MV将w给的答案作为真值推理的判断条件。对于数字任务,均值和中位数是两种基本方法。将w回答的均值和中位数作为任务的真相。
优化方法
- 基本思想是设置一个自定义的优化函数,捕捉w素质和任务真值的关系,然后推导出迭代方法,将参数集合起来计算。现有的研究主要是在于工人素质建模不同,以及优化函数不同。
工人概率
- PM模型将工人素质建模为单一值,优化函数为:
q
w
q^w
qw为所有w素质集合,
v
i
∗
v_i^*
vi∗为所有真理的集合。
v
i
w
v_i^w
viw和
v
i
∗
v_i^*
vi∗越接近,d越小,w的答案越接近真实值。同时PM也有一种迭代方法,每次迭代都采用第三节的两个步骤。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eLRf8T05-1667897579633)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023181325694.png)]
工人概率和信心
- CATD【30】同时考虑了工人概率和信心。
- 通过w回答任务越多,w的质量越高,从而构建一个函数,认为给出接近真值答案并回答大量任务的w应该是一个高质量的 q w q^w qw,采用迭代方法直至收敛。
多样技能
- Minimax【61】使用极小和极大的思想。模拟w的不同任务中的不同技能,专注于选择(单标签)任务。
- $\pi_i^w = [\pi_{i,1}^w, \pi_{i,2}w,\ldots,\pi_{i,n}w] , , ,\pi_{i,j}^w 代表 w 用第 j 个选项回答任务 代表w用第j个选项回答任务 代表w用第j个选项回答任务t_i$的概率。
- 在此基础上,考虑任务和工作者两个约束条件来定义目标函数。对于 t i t_i ti,选择收集概率的答案的数量等于生成概率的和。对于w,假设真值是第j个,收集到第k个选择答案的数量等于相应产生的概率的总和。【61】设计了迭代来推断两组参数。
####概率图形化模型(PGM)
- 是一种表示随机变量(节点)之间的条件依赖结构(边表示)的图。
- 图1显示了现有工程中采用的一般PGM。每个节点代表一个变量。有两个盘子,分别用于工人和任务,其中每个盘子都表示重复的变量。 α , β , V i w \alpha, \beta, V_i^w α,β,Viw是已知的, q w 和 V i ∗ q^w和V_i^* qw和Vi∗是未知的,需要计算的。有向边模拟了子节点与其相关父节点之间的条件依赖。即子节点遵循由父节点获取的值为条件的概率分布。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mBn1WHyJ-1667897579634)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023183928296.png)]
- 使用PGM的每种方法。根据w模型不同,方法也不同,分为三类
- 工人概率
- ZC:利用概率推理和众包技术进行大规模实体链接【16】
- 采用上图PGM,简化不考虑鲜艳,假设所有任务都是决策任务,工人质量被建模为 q w q^w qw,决策任务中,ZC试图让工人答案出现的概率最大化,成为似可性:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ypva3qTG-1667897579634)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023184734875.png)]
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-euPQdQPq-1667897579634)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023184901375.png)]
- 由于非凸,很难优化,ZC利用EM框架【17】迭代更新近似其最优值。
- ZC的扩展有:GLAD、KOS、VI-BP、VI-MF
- 任务模型
- GLAD拓展了ZC,不是假设每个任务都是相同的,而是对每个任务 t i t_i ti的难度 d i d_i di进行建模。将工人答案建模,将其集成到方程1中,使用梯度下降来求最优。
- 调优方法
- KOS、VI-BP、VI-MF在优化目标中拓展了ZC。ZC是点估计,KOS和VI-BP利用贝叶斯来计算 q w q^w qw的积分,目标是估计真值 v i ∗ v_i^* vi∗
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vn9AyRPB-1667897579635)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023190555871.png)]
- 方程2是很难直接计算的,现有研究是寻求VI(变分推理 Variational Inference)技术来逼近。KOS提出了一个更通用的模型,称为VI-bp
- ZC:利用概率推理和众包技术进行大规模实体链接【16】
- 混淆矩阵(D&S及其扩展)
- D&S专注于单标签任务,为w建模,D&S尝试优化 a r g m a x q w argmax_{q^w} argmaxqw函数,并用用**EM框架【17】**来迭代两步骤。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fPl35NWW-1667897579635)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023190836386.png)]
- D&S【15】将工作者建模为混淆矩阵,还有一些拓展如,LFC、LFC N,BCC和CBCC
- 先验知识:LFC拓展D&S,把先验纳入w模型中
- 任务类型:LFC_N处理数字任务,与决策和单一不同,它假设w的答案遵循 V i w N ˜ ( v i ∗ , σ w 2 ) V_i^w \~N(v_i^*,\sigma_w^2) ViwN˜(vi∗,σw2),较小的 σ w \sigma_w σw意味着真值接近。
- 优化方法:BCC【27】和D&S的优化目标不同,目标是使后关节概率最大化。图1中优化了所有未知变量的后关节概率。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Iu5d6tMD-1667897579637)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023191956973.png)]
- 优化上公式,使用Gibbs Sampling迭代推断两组参数直到收敛, q w q^w qw被建模为混淆矩阵。
- CBCC将BCC拓展到支持社区,其基本思想是,每个工人属于一个社区,每个社区有一个代表性的混淆矩阵,同一社区的工人共享非常相似的混淆矩阵。
- 多样化技能:多样化和其他
- 一些研究【51,19,35,59】对工人技能建模,同时添加K向量,捕捉w和K个潜在主题的技能的关系。[35]将模型的过程和真值推断结合一起,利用知识库开发员工多样化技能。
- 工人概率
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-03sRpwtB-1667897579638)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023192435853.png)]
6 实验
- 真实数据评估17种现有方法(表4),CPU 2.4GHz,内存60GB用Python实现实验
实验设置
数据集
- 五个具有代表性数据集(根据三个标准)
- (1)任务规模大;
- (2)每个任务收到多个答案;
- (3)所有数据集涵盖不同的任务类型
- 统计数据:
- tasks: 任务数量n
- |V|: 收集的答案
- |V|/n:每个任务的平均答案数量
- truth: 真相
- |W|: 工人
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x0DwxN6l-1667897579639)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023193144850.png)]
-
eg:对于数据集D_Product,它包含8,315个任务,从176个工作者中收集了24,945个答案,每个任务平均被回答3次
-
决策任务数据集
- D_Product:
- 每个任务都包含两个产品(带有描述)和两个选择(T, F),它要求工作人员识别“两个产品相同”的声明是真(“T”)还是假(“F”)。一个例子任务是“索尼相机携带lcsmx100和索尼LCS-MX100摄像机是一样的吗?”
- D_PosSent
- 数据集中的每个任务都包含一条与某家公司相关的推文(例如,“苹果最近的产品太棒了!”),并要求工作人员识别该推文是否对该公司有积极的情绪。工人们对每项任务给出“是”或“不是”的回答。
- AMT[2]中,我们通过选择20个任务手动创建资格测试,每个工人在回答我们的任务之前都应该回答资格测试。
- D_Product:
-
单选任务数据集:
- S_Rel
- 每个任务都包含一个主题和一份文档,它要求工作人员从“高度相关”、“相关”、“不相关”和“断开链接”四个选项中选择一个来选择主题的相关性。
- S_Adult
- 每个任务包含一个网站,要求工作人员从四个选项中选择一个来确定该网站的成人级别:“G”(一般观众)、“PG”(家长指导)、“R”(限制)和“X”(色情)。
- S_Rel
-
数字任务数据集:
- N_Emotion
- 数据集中的每个任务都包含一个文本和一个范围[−100,100],它要求每个工作人员在这个范围内选择一个分数,表示文本的情绪程度(例如,愤怒)。分数越高,表示这种情绪的程度越高。
- N_Emotion
指标
- 决策任务
- Accuray: 我们使用准确性作为度量,它被定义为正确推断出真相的任务的比例。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R6fWvjNm-1667897579640)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023194716540.png)]
- F1-Score:在实体解析中,我们更关心实体(即选择T),因此,通常使用典型的度量f1得分,定义为精度和召回率的调和平均值:(D_product中T:F=0.12:0.88,这是个例):
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XTARjsIM-1667897579641)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023194955529.png)]
- Accuray: 我们使用准确性作为度量,它被定义为正确推断出真相的任务的比例。
- 单选任务:
- 使用Accuracy度量(还是公式3)
- 数字任务:
- 我们使用两个指标,MAE(平均绝对误差)和RMSE(均方根误差)(RMSE对交大误差给予较高惩罚)
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vOvdaqEc-1667897579642)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023195134177.png)]
- 我们使用两个指标,MAE(平均绝对误差)和RMSE(均方根误差)(RMSE对交大误差给予较高惩罚)
- Attention:
- 对于Accuracy和F1-Score,值是[0, 1]中,越高越好
众包数据质量(三个问题来判断)
- 众包数据是否一致?(不同的工作人员对同一项任务的回答是否相同?)
- 有很多冗余的工人吗?(每个员工都要完成很多任务吗?)
- 工作人员提供高质量的数据吗?(每个工人的回答是否与事实一致?)
数据一致性
-
决策&单标签任务
- 每个任务都包含固定数量的选择,对于任务 t i t_i ti,设 n i , j n_{i,j} ni,j表示第j个选项的答案个数。为了捕捉工作人员答案的集中程度,我们首先计算每个任务收集的答案分布上的熵,然后定义数据一致性©为平均熵。C越低、工作者的答案越一致。
- 为每个数据集计算C。4个数据集的C值分别为0.38、0.85、0.82和0.39。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nhxVGeCV-1667897579643)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023200320417.png)]
-
数字任务
- 个任务的答案都有固有的顺序,为了捕捉工人答案的一致性,对于一个任务
t
i
t_i
ti,我们首先计算所有收集的答案的中值
v
i
v_i
vi(统计中的一个健壮度量,它对异常值不敏感);那么一致性©定义为与中位数相比的平均偏差,C越低,答案越一致。N_Emotion,C是20.44
-
- 个任务的答案都有固有的顺序,为了捕捉工人答案的一致性,对于一个任务
t
i
t_i
ti,我们首先计算所有收集的答案的中值
v
i
v_i
vi(统计中的一个健壮度量,它对异常值不敏感);那么一致性©定义为与中位数相比的平均偏差,C越低,答案越一致。N_Emotion,C是20.44
-
summary:众包数据是不一致的,这激发了开发方法可以解决众包中的真相推断
工人冗余
- 对于每个worker,我们将其冗余定义为该worker应答的任务数量。我们在每个数据集中记录每个工作者的冗余,然后在图2中绘制工作者冗余的直方图。具体来说,在每个数据集中,我们改变任务的数量(k),并记录回答k个任务的工人的数量。从图2中我们可以看到,工人冗余符合长尾现象,即大多数工人回答少数任务,只有少数工人回答大量任务。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SWjwJLNB-1667897579644)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023202647870.png)]
- summary:真实众包平台中众包数据的工作者冗余符合长尾现象。
工人质量
- 在图3中,对于每个数据集,显示了每个工人的质量,基于工人的回答与任务的真实性进行比较计算
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EQpUoWgM-1667897579644)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023202659414.png)]
- 决策&单标签任务
- 计算每个工人w的准确性,即被正确回答的任务的比例,公式为: Σ t i ∈ T w { v i w = v i ∗ } ∣ T w ∣ ∈ [ 0 , 1 ] \frac{\Sigma t_i\in T^w\{v_i^w=v_i^*\}}{|T^w|}\in[0,1] ∣Tw∣Σti∈Tw{viw=vi∗}∈[0,1],值越大质量越高。
- 对于每个数据集,我们计算每个工人的相应精度,并绘制每个工人的直方图。对于不同的数据集,工人精度直方图的形状是不同的。D_Product和D_PosSent是较高,S_Adult准确率中等,S_Rel准确率较低。每个数据集中所有工人的平均准确率分别为0.79、0.79、0.53和0.65。
- 数字任务:
- 由图3(e)知,平均RMSE为28.9
- summary:在同一数据集中,工人的素质各不相同,因此有必要识别值得信任的工人。
####众包的真值推理
-
本节比较现有方法【34、16、15、53、51、41、26、33、61、30、27、46、31、5】的性能。基于以下观点:
-
不同方法的性能如何?
- 如果我们只知道工人的答案(即V),哪种方法表现最好?此外,对于一个方法,随着更多的工作者的答案,真理推断质量如何变化?
-
资格测试的效果如何?
- 如果我们假设一个worker在回答真正的任务之前已经执行了一些黄金任务,并根据该worker对黄金任务的回答表现初始化该worker的质量(算法1中的第1行),这是否会提高每种方法的质量?
-
隐藏测试的效果是什么?
- 如果我们将一组黄金任务混合在实际任务中,那么每种方法在真理推断方面能获得多少好处?
-
不同的任务类型、任务模型、工作者模型和推断技术的影响是什么?
- 哪些因素有利于推断真相?
-
分辨差数据冗余
-
对于数据冗余,我们将其定义为为每个任务收集的答案的数量。改变数据冗余度,对于每个特定的r,我们从每个任务收集的3个答案中随机选择r,并使用所选的答案构造一个数据集。(即对所有n个任务的答案数量为r·n的数据集)。在构造的数据集上运行每种方法,并记录基于每种方法的推断真理与基础真理比较的准确性。我们重复每个实验30次,报告平均质量。
-
决策任务使用F1-score,单标签任务用精度指标-Accuracy,数字任务使用MAE、RMSE指标
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wiJTxUHt-1667897579645)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023204516012.png)]
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5N48euZ7-1667897579645)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221023204527742.png)]
-
不同方法在不同数据集中的质量:
- 决策任务
- r属于【1,3】时,方法的质量随着r增加而增加
- Accuracy对于各种方法差异不明显,F1-Score指标表现得更好,其中四种方法表现比较好(D&S, BCC,CBCC, LFC)
- 任务模型方面,引入任务难度(GLAD)或者潜在主题(Minimax)对质量影响并不显著。
- **工作者模型方面,**具有混淆矩阵的四种方法(D&S, BCC,CBCC, LFC)性能明显优越其他方法。
- 原因是:抓住了T和F(详细的再参悟参悟把)
- BCC方法:r=1, F1-Score = 0。但当数据完整时,BCC在Accuracy上表现最好,D&S方法在F1-Score方法上表现最好。
- 单选任务:针对十种专门处理但标签任务的方法进行比较,得出结果:
- S_Rel上,一般来说,方法质量随r的增加而增加。在S_Adult上, r ∈ [ 1 , 5 ] r \in [1,5] r∈[1,5]方法质量增加,当 r > = 5 r >= 5 r>=5,方法质量保持稳定。
- 质量方面:在S_Rel上,D&S, BCC 和 LFC三种质量>=60%的方法优于其他方法。S_Adult上,不同方法性能相似。
- S_Rel上,当r≥4时,CATD和ZC方法的质量下降,可能是由于它们对低质量工作者的答案比较敏感。
- 单标签任务的方法质量低于决策任务,这是由于工人不善于回答多项选择任务,且单标签任务的方法对素质较低的工人敏感。
- 数字任务:五种方法CATD, PM, LFC N, Mean和Median
- 一般情况下,几乎所有方法的误差都随着r的增加而减小
- 基线方法的均值表现最好
- 数值任务的方法没有很好地处理,只有3种方法(即CATD、PM、LFC N)是专门为数值任务设计的。
- 决策任务
-
不同方法的效率:
- MV、Mean、Median可直接推断出真理
- (ZC、GLAD、D&S、Minimax、BCC、CBCC、LFC、CA TD、PM、Multi、KOS、VIBP、VI-MF、LFC N)遵循算法1,迭代到阈值,时间复杂度为O(c · t),其中c为要收敛的迭代次数,t为每次迭代的时间。
- 非迭代方法(MV, Mean和Median)在1s内完成。对于迭代法,(1)ZC, D&S, LFC,CA TD, PM, LFC N可在15s内完成,效率较高。
- BCC、CBCC、Multi、KOS、VI-MF等方法耗时大于15s,但完成时间小于3min。
- GLAD、Minimax、VI-BP等方法,完成时间长达100min,速度较慢。
-
Summary:
- 当数据冗余度r较小时,质量显著提高,当冗余度达到一定 r ^ \hat{r} r^ > r 后,质量保持稳定。
- 没有一种方法在所有被测试的数据集上始终表现最好。
- 在决策和单标签任务中,三种方法(D&S, BCC, LFC)在数据完整的情况下表现优于其他方法
- 在数字任务中,已有的研究没有很好地解决这一问题,其中基线方法均值在N种情绪中表现最好。
- 在任务模型方面,任务中的任务难度(GLAD)和潜在主题(Multi)建模方法在质量上表现不显著
- 在工人模型方面,一般来说,混淆矩阵在质量上优于工人概率;而其他的工人模型(例如,多样化的技能,工人偏见,差异和信心)并没有带来显著的好处。
- 在推理技术方面,从有效性上看,优化和PGM方法比直接计算方法更有效。在效率方面,直接计算比优化和PGM更有效。
资格考试的效果
- D_PosSent: AMT要求每个工人在第一次来的时候被要求回答20个已知基本事实(资格测试)的任务(黄金任务)。在其他四个公共数据集中,用于资格测试的数据没有公开(或在大多数情况下不使用)。
- bootstrap抽样。通过资格测试可以初始化工人素质的方法只有8种(ZC、GLAD、D&S、LFC、CA TD、PM、VI-MF和LFC N),每个实验重复100次。我们用合格检验表示** c ~ \tilde{c} c~为平均质量**;c为未经合格检验的质量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HKRh0mog-1667897579646)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221101155110140.png)]
-
决策任务和单标签任务
-
数据冗余度小的数据集(如D_Product)需要通过资格测试才能很好地初始化工人的素质,而其他数据集则可以在无监督的情况下正确检测每个工人的素质。
-
收益(∆)往往很小,有时∆< 0,因为几乎所有的方法都采用迭代的方法,并近似于目标值,因此初始化不充分可能导致糟糕的局部最优。
-
-
数字任务
- N_Emotion, CATD、PM和LFC N中的任何方法都不能从中受益,其中所有方法的误差MAE和RMSE都有所增加
-
Summary
- (1)有些方法可以从资格检验中获得边际效益。
- (2)在数值任务中,大多数方法无法获益,仍有改进的空间。
- (3)有些方法很难纳入资格测试。
隐藏测试的效果
- Summary:
- (1)一般情况下,黄金任务的比例(p%)越大,不同方法的质量越好。
- (2)不同的方法对不同的数据集有不同的改进。
- (3)只有9种方法是容易合并黄金任务的。(ZC、GLAD、D&S、Minimax、LFC、CA TD、PM、VI-MF和LFC N)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AfoYuqfo-1667897579646)(C:\Users\Karl_Cheng_CISL\AppData\Roaming\Typora\typora-user-images\image-20221101164344326.png)]
真值推理中的不同因素分析
- 任务类型
- 单标签任务的方法对低质量的工人更敏感。
- 字任务,这些方法还没有得到很好的研究,甚至在数据集N_Emotion中,基线方法Mean也优于其他方法。
- 任务模型
- 只有GLAD和Minimax两种方法(表4)考虑了具体的任务模型(分别是任务难度和潜在主题)。它们并没有显示出质量的提高。此外,它们通常需要很长时间才能收敛。
- 工人模型
- 一般来说,具有混淆矩阵的方法(D&S, BCC, CBCC, LFC, VI-BP, VIMF)比具有工作者概率的方法(ZC, GLAD, CA TD, PM, KOS)表现更好。
- 对于混淆矩阵,D&S、BCC、LFC方法比其他方法(CBCC、VI-BP、VI-MF)更健壮,因为它们的技术可以更准确地推断工人的质量。
- 推理技术
- 分别从质量、效率和可解释性三个方面对该技术进行了分析。
- (1)从质量上看,优化法和PGM法比直接计算法考虑的参数更多。
- (2)在效率方面,优化方法和PGM方法的效率低于直接计算方法。
- (3)在可解释性方面,Optimization更容易理解。
- 分别从质量、效率和可解释性三个方面对该技术进行了分析。
7 Conclusion & Future Directions
- 总结了一个框架(算法1),并分析了这些方法中的任务类型、任务模型、工作者模型和推理技术。
- 建议:
- 决策&单标签任务
- 如果一个人有足够的工人的答案(例如,冗余超过20),并且想要一个非常简单的实现,获得合理的结果,那么我们推荐基线方法,即MV;
- 如果你想要一个开销很小的实现,但获得非常好的结果,那么我们推荐经典的方法D&S[15],它在实践中是健壮的;
- 如果你想尝试一些D&S的扩展,那么BCC[27]和LFC[41]都是不错的选择;
- 如果想要学习更多的推理技术并结合各种任务/工作者模型,我们推荐PGM方法Multi[51]和Optimization方法Minimax[61]。
- 数字任务
- 如果一个人有足够的工人的答案,我们推荐基线方法(即,平均值)
- 任务类型
- 在决策和单标签任务中,推荐D&S[15]和LFC[41],这两种方法相对来说效果和效率更高。
- 在数值任务中,我们推荐Mean和LFC_N[41],数值任务仍有改进的空间。
- 任务设计
- 为了高效地收集高质量的众包数据,设计具有友好的用户界面(UI)和可行的价格的任务是非常重要的。
- 数据冗余
- 小冗余时,质量显著提高,大冗余时,质量保持稳定
- 资格测试
- 并不是所有的方法都能从鉴定试验中受益,有些方法的质量甚至下降。
- 隐藏测试
- 尽管大多数方法都可以从中受益,但改进在不同的数据集和方法中有所不同。
- 任务分配
- 不同的任务分配策略所收集到的答案如何影响真理推断的质量是很有趣的。
- 合并更丰富的功能
- 在本文中,我们只考虑收集到的任务答案;然而,我们没有包含更丰富的信息,例如,任务中的上下文(每个任务的文本描述或图像任务中的像素)。这些在已有的研究[19,35,54,43]中已经提到。
- 基准
- 数据库研究中,已经有了各种基准,它们提供了一个标准化的度量来评估不同方法的性能。在众包领域,虽然已经有了一些公共数据集[13],但可用的基准很少。在众包中制定基准和评价措施是很重要的。
- 决策&单标签任务
















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











