






常见offset管理方法介绍
1 checkpoints
Spark Streaming的checkpoints是最基本的存储状态信息的方式,一般是保存在HDFS中。但是最大的问题是如果streaming程序升级的话,checkpoints的数据无法使用,所以几乎没人使用。
2 Zookeeper
Spark Streaming任务在启动时会去Zookeeper中读取每个分区的offsets。如果有新的分区出现,那么他的offset将会设置在最开始的位置。在每批数据处理完之后,用户需要可以选择存储已处理数据的一个offset或者最后一个offset来保存。这种办法需要消费者频繁的去与Zookeeper进行交互,如果期间 Zookeeper 集群发生变化,那 Kafka 集群的吞吐量也跟着受影响。
3 一些外部数据库(HBase,Redis等)
可以借助一些可靠的外部数据库,比如HBase,Redis保存offset信息,Spark Streaming可以通过读取这些外部数据库,获取最新的消费信息。
4 kafka
Apache Spark 2.1.x以及spark-streaming-kafka-0-10使用新的的消费者API即异步提交API。你可以在你确保你处理后的数据已经妥善保存之后使用commitAsync API(异步提交API来向Kafka提交offsets。新的消费者API会以消费者组id作为唯一标识来提交offsets。
Kafka版本0.10.1.1,已默认将消费的offset迁入到了Kafka一个名为__consumer_offsets的Topic中。所以我们读写offset的对象正是这个topic,实际上,一切都已经封装好了,直接调用相关API即可。
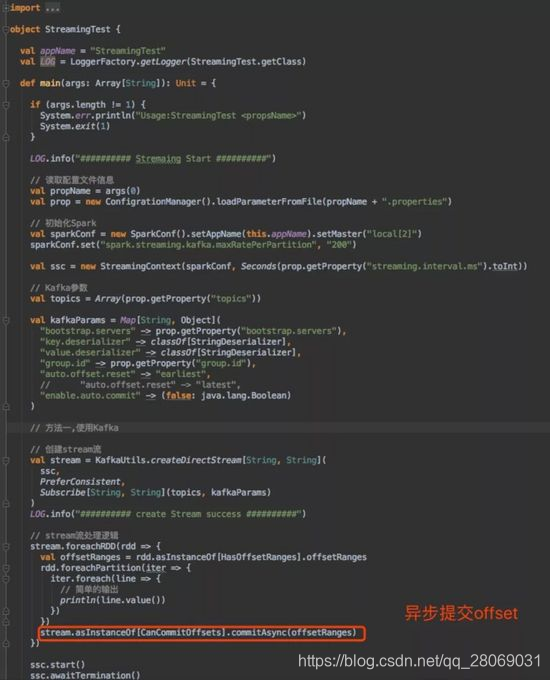
重点三个步骤:
1)设置不自动提交,kafka参数:“enable.auto.commit” -> (false);
2)消费前先获取偏移量范围:
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges;
3)消费完后更新offset:
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges);














 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









