







pandas 有些功能用起来就和SQL一样,前面有说过类似JOIN的操作
橘猫吃不胖:pandas回顾小结(三)-合并与拼接zhuanlan.zhihu.com

聚合也是SQL中很常用的操作
DataFrame.groupby(
by=None,
axis=0,
level=None,
as_index=True,
sort=True,
group_keys=True,
squeeze=<object object>,
observed=False,
dropna=True)
我们传入要聚合的字段,返回的是DataFrameGroupBy对象
-
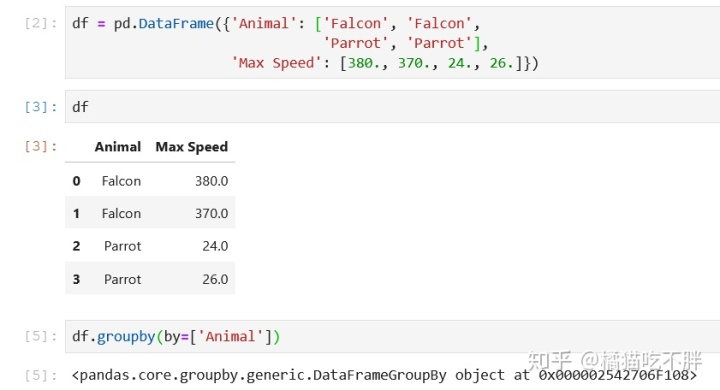
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon', -
'Parrot', 'Parrot'], -
'Max Speed': [380., 370., 24., 26.]}) -
df.groupby(by=['Animal'])
-
gp = df.groupby(by=['Animal']) -
gp.groups -
gp.indices
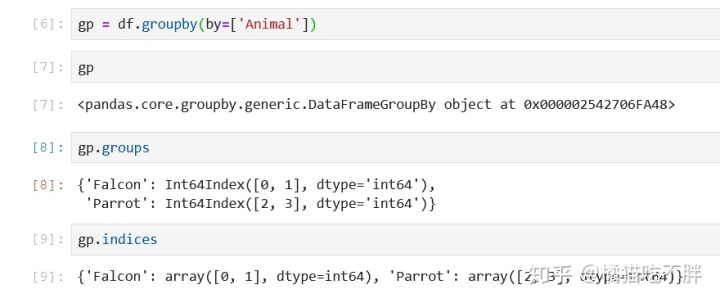
groupby之后,数据会被分组,按照指定字段的分组,这里就按照不同动物进行了分组
如果会SQL,这里理解会很容易,比如,我们想要看不同动物的最高速度
我们其实想知道每个分组里的最大值是多少
-
gp.max() -
gp.min()

这样其实就是我们想要的数据了
对多个字段进行聚合
-
df = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar', -
'foo', 'bar', 'foo', 'foo'], -
'B': ['one', 'one', 'two', 'three', -
'two', 'two', 'one', 'three'], -
'C': np.random.randint(10), -
'D': np.random.randint(8)}) -
df.groupby(by=['A','B']).sum()
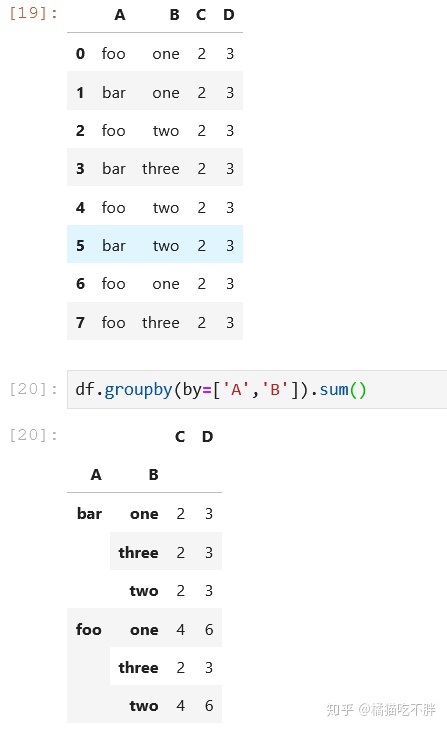
这里,默认对所有的列都做了聚合操作
可以只对C列进行操作
df.groupby(['B','A'])['C'].sum()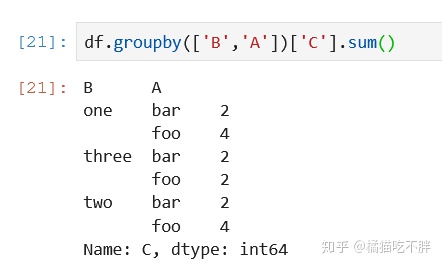
DataFrameGroupBy对象是可以遍历的
-
gp = df.groupby(['B','A'])['C'] -
for name, group in gp: -
print(name) -
print(group)
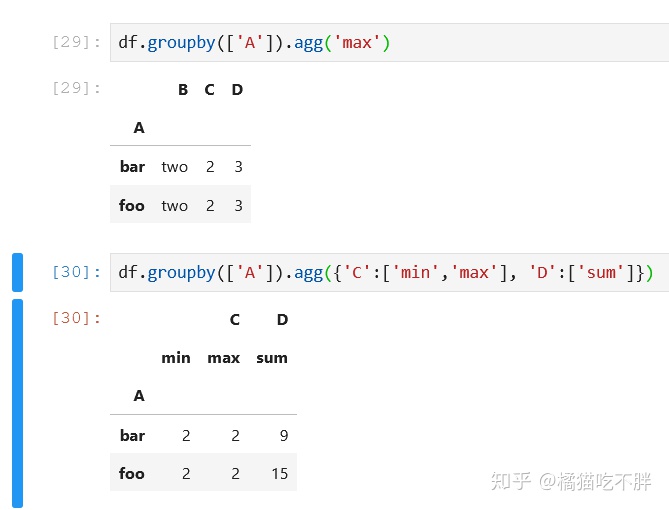
有时候,我们相对不同的字段,使用不同的聚合函数
这里需要用到agg函数
DataFrame.agg(
func=None,
axis=0,
*args,
**kwargs)
-
df.groupby(['A']).agg('max') -
df.groupby(['A']).agg({'C':['min','max'], 'D':['sum']})
上面,我们使用了聚合函数,现在,来一个综合的小栗子
已知,数据集,如下所示:
-
df = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar', -
'foo', 'bar', 'foo', 'foo'], -
'B': ['one', 'one', 'two', 'three', -
'two', 'two', 'one', 'three'], -
'C': np.random.randint(10), -
'D': np.random.randint(8)})

现在,我们要添加C_total列,表示对A列聚合,C列的和,就是group by A ,sum(C)
-
gc = df.groupby(['A']).agg({'C':'sum'}).add_suffix('_total') -
df.merge(gc, left_on='A', right_index=True)

这里先聚合后,使用 add_suffix,添加了后缀,然后使用merge函数,将两个DataFrame连接起来















 5911
5911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









