







 文章探讨了大规模语言模型的最新进展,通过分析不同架构、训练策略和数据集,提出新方法增强模型的训练稳定性和泛化能力。重点讨论了分词方案(如WordPiece)、注意力机制(自注意力和交叉注意力)以及优化器的影响。研究表明,所提出的方法在翻译、摘要生成等任务上表现出色。
文章探讨了大规模语言模型的最新进展,通过分析不同架构、训练策略和数据集,提出新方法增强模型的训练稳定性和泛化能力。重点讨论了分词方案(如WordPiece)、注意力机制(自注意力和交叉注意力)以及优化器的影响。研究表明,所提出的方法在翻译、摘要生成等任务上表现出色。
概述
这篇文章的研究背景是大规模语言模型的发展和广泛应用。研究人员意识到通过深度学习技术和神经网络架构的进步,可以创建出具有接近人类水平表现的大规模语言模型。
过去的方法包括改进现有架构和训练策略、增加上下文长度、使用高质量的训练数据以及增加训练时间来提高性能。然而,这些方法存在一些问题,比如训练的不稳定性和泛化能力的限制。本文的方法是通过综合分析不同大规模语言模型的架构、训练策略、训练数据集和性能评估,从而提出一种新的研究方法和技术来改善训练稳定性和泛化能力。
本文提出的研究方法是通过详细分析大规模语言模型的构建模块和概念,包括自回归模型和编码解码器等,来获得对大规模语言模型的全面了解。基于这些基本概念,本文综合介绍了大规模语言模型的架构、重要特性和功能,并总结了开发先进的大规模语言模型的关键架构和训练策略。
本文的方法在多项任务上取得了良好的性能,包括翻译、摘要生成、信息检索和对话交互等。这些方法的性能支持了它们的目标,即提高大规模语言模型的训练稳定性和泛化能力。
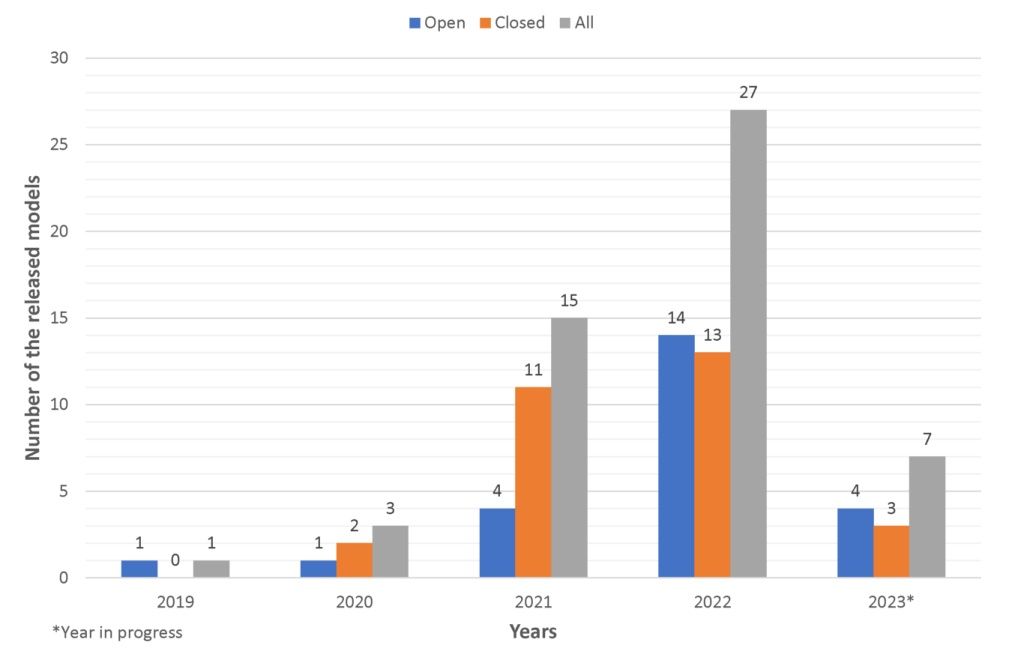
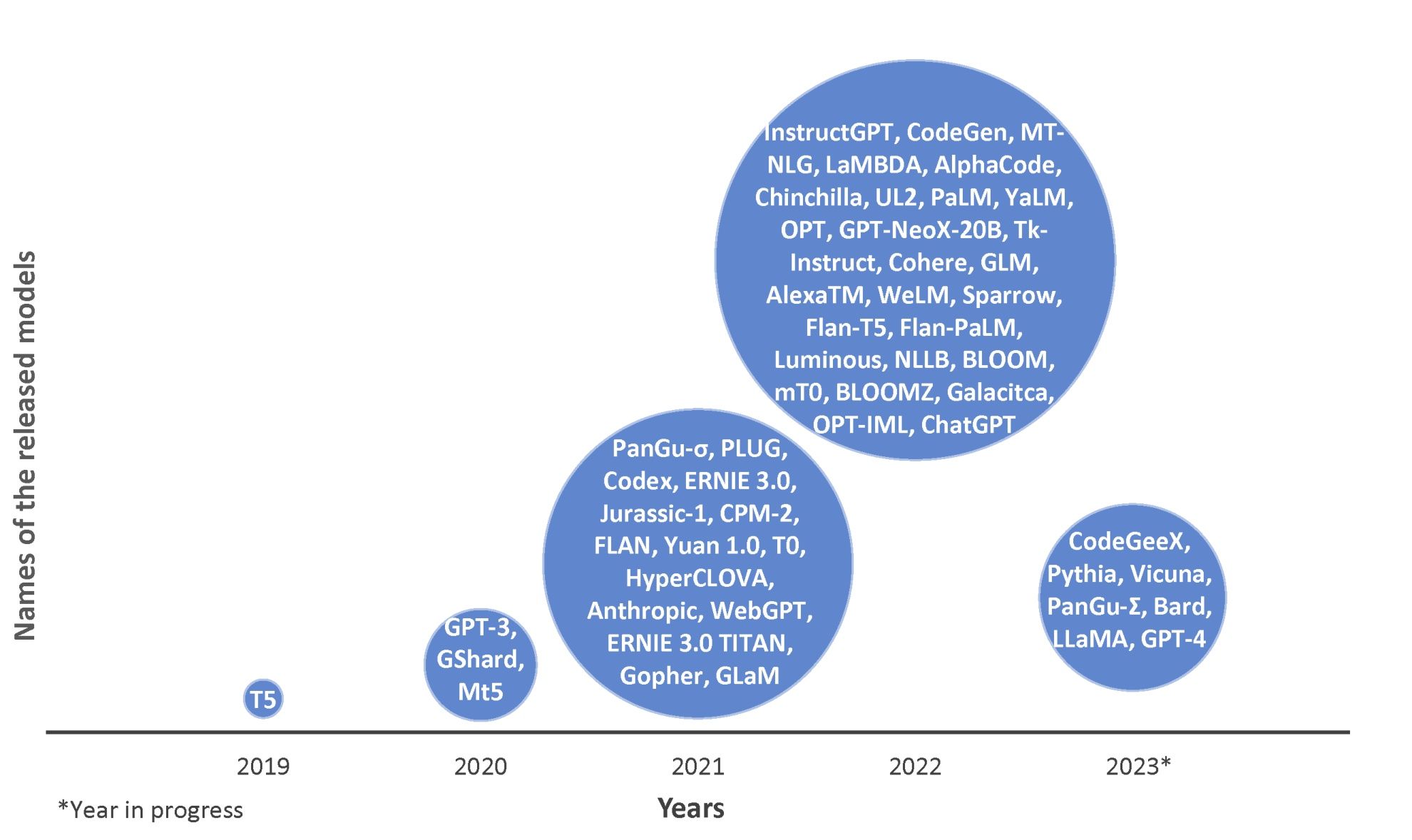
重要问题探讨
1. 在语言模型中,不同的分词方案会对模型的性能产生怎样的影响?作者是否提到了哪种分词方案在该领域应用最广泛?为什么选择这种分词方案?
在文章中,作者提到了三种常见的分词方案:WordPiece、BP
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









