






摘要
我们提出了一种独立于语言的新颖方法,通过将GEC任务分为两个子任务来提高语法错误纠正的效率:错误跨度检测(ESD)和错误跨度校正(ESC)。ESD使用有效的序列标注模型来识别语法错误的文本范围。然后,ESC利用seq2seq模型将带有错误跨度注释的句子作为输入,并仅输出这些跨度的校正文本。实验表明,我们的方法在英语和中文GEC基准中的性能均与常规seq2seq方法相当,推理时间不到50%。
1.介绍
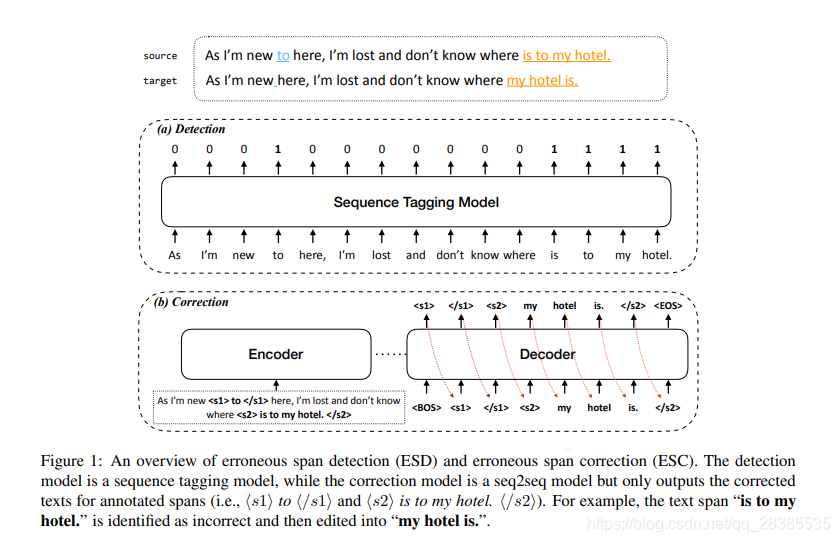
由于近年来可用的错误纠错的并行语句数量不断增加,具有编码器-解码器架构的序列到序列(seq2seq)模型成为GEC的流行解决方案,它采用源(原始)语句作为输入,并输出目标(校正)语句。尽管自回归seq2seq模型有助于纠正各种语法错误并表现良好,但它们对GEC的效率不足。正如之前的工作所指出的那样,seq2seq模型采取大多数解码步骤,以在推理过程中将语法正确的文本范围从源复制到目标,这是主要的效率瓶颈。如果可以节省复制操作的时间,则效率应大大提高。
出于这种动机,我们提出了一种简单而新颖的语言独立方法,通过将该任务分为两个子任务来提高GEC的效率:错误跨度检测(ESD)和错误跨度校正(ESC),如图1所示。如图1(a)所示,我们使用有效的序列标注模型来识别源句中语法错误的文本范围。然后,我们将带有错误跨度注释的句子输入ESC的seq2seq模型。与纠正完整句子的常规seq2seq方法相反,ESC仅纠正错误的跨度(请参见图1(b)),从而大大减少了解码的步数。中英文GEC基准测试表明,我们的方法与基于最新transformer的seq2seq模型相当,推理时间不到50%。此外,我们的方法为控制校正提供了更大的灵活性,从而使我们能够在各种应用场景中精确调整。
2.相关工作
最近,已经提出了许多改善GEC性能的方法。但是,除了那些添加合成错误数据和Wikipedia修订日志以外,大多数方法会导致延迟增加。例如,语言模型和从右到左(R2L)评分不仅需要花费时间来重新评分,而且还会在推理过程中放慢集束大小以校正模型 ; 多轮(迭代)解码需要重复运行模型; BERT-fuse为模型融合增加了额外的计算量。
与对GEC性能的广泛研究相反,直到最近几年,很少有工作致力于提高GEC模型的效率。工作的一个分支是依赖语言的方法,例如PIE和GECToR。 他们预测一系列字符级别的编辑操作,包括许多手动设计的特定于语言的操作,例如更改动词形式(例如
V
B
Z
→
V
B
D
VBZ→VBD
VBZ→VBD)和介词(例如
i
n
→
o
n
in→on
in→on)。但是,它们很难适应其他语言。 另一个分支是独立于语言的模型,例如LaserTagger。他们从训练数据中学到了编辑操作的词汇,因此可以使用任何语言。但是,它们的性能不如seq2seq。我们的方法结合了两个分支的优势,并且与最新的seq2seq方法相比,具有高效的推理能力。
3.错误跨度检测
为了识别不正确的跨度,我们使用二进制序列标注模型,其中标签0表示字符在正确的跨度中;标签1表示字符的语法不正确,需要编辑,如图1(a)所示。我们在训练数据中跨源句子和目标句子对齐标记。通过字符对齐,我们可以识别已编辑的文本范围,从而可以将原始句子中已编辑的文本范围注释为错误的范围。
4.错误跨度纠错
使用ESD,我们可以识别句子中语法错误的文本范围。如果发现句子没有错误,我们将不采取进一步措施;否则,我们将注释不正确的跨度,并使用ESC模型对其进行校正,如图1(b)所示。
为避免ESC在推理过程中由于ESD跨度检测错误而误导,我们以类似于SpanBERT的方式随机选择文本跨度,而不是仅在训练数据中根据标注的错误跨度来训练ESC模型。通过这种方式,ESC模型将看到各种各样的跨度注释,并学习如何在训练期间进行校正,从而提高了其鲁棒性:即使在推理过程中检测到的跨度不是十分准确,ESC模型也不会轻易失败。通过GEC训练数据中源句子和目标句子的标记对齐,我们可以生成带有跨度注释和修改后的训练实例,如图1(b)中的ESC示例。
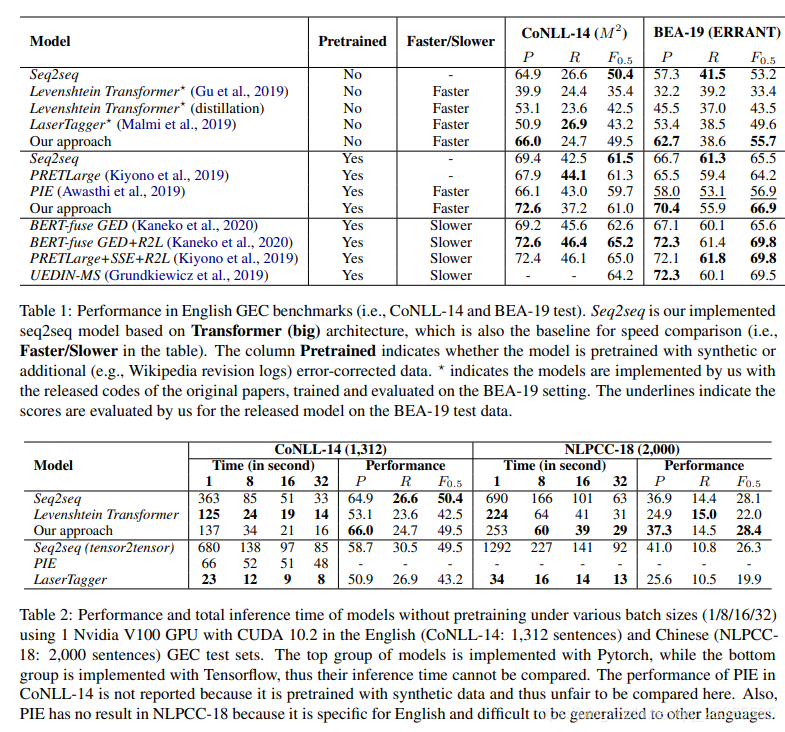
5.实验

















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









