






 研究者提出Split-NER,一种通过将NER任务拆分为spandetection和spanclassification的问答分类方法,有效提高NER性能,减少训练时间。通过加入CharacterSequenceFeature和OrthographicPatternFeature,模型在多个数据集上表现优于传统模型,尤其在领域特定术语的准确性上有显著提升。
研究者提出Split-NER,一种通过将NER任务拆分为spandetection和spanclassification的问答分类方法,有效提高NER性能,减少训练时间。通过加入CharacterSequenceFeature和OrthographicPatternFeature,模型在多个数据集上表现优于传统模型,尤其在领域特定术语的准确性上有显著提升。
文章标题:Split-NER: Named Entity Recognition via Two Question-Answering-based
Classifications
论文地址:https://pan.baidu.com/s/1BbmSTvHPIPW4tvUmS92oug?pwd=55v2
提取码:55v2
1.总体介绍
最近NER任务被视为是一种span predication的任务并且有一种趋势即将这种任务化为一种QA任务。因此本文提出了一种基于问答分类的命名实体识别(NER)的创新方法,即Split-NER系统,其在多个数据集上优于其他模型,同时显著缩短了训练时间。
该系统将NER任务分为两个逻辑子任务:(1)span detection(2)span classification。这种处理方法能够分别对两个子任务进行优化,从而提高NER的效率与准确性。
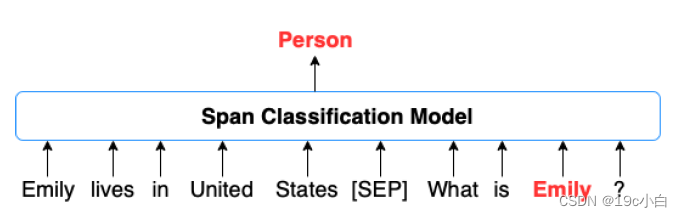
该系统整体流程如下图所示:
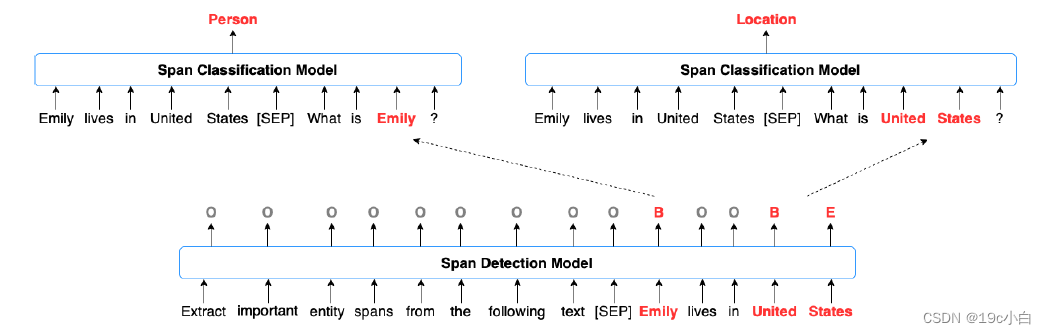
系统的整体框架
下方模型[SEP]前的句子为自行设计的提问语句,再将需要进行实体识别的sentence接在后面,将其输入系统,检测出每个span。再将sentence与每个span分别输入上方的模型并加上提问语句。来识别出该实体的类型。
优点:
1.先前模型span detection是需要重复检测所有可能,该模型改为线性检测。
2.先前模型span classification是需要对多个类型进行多次提问,该模型只需要提问一次。
2.模型设计
2.1 span detection
span detection是通过基于问答的分类方法实现的,使用了BERT-base模型架构。该模型使用BIOE方案对每个标记进行分类,并输出一个由起始和结束索引组成的提及跨度列表 〈s,e〉,其中 s,e ∈ [1,n]。Span Detection Model是无实体类型的,可以识别文本中的所有提及跨度。该模型的通用问题是“Extract important entity spans from the following text”。
由于将该任务划分为两个子任务,所以有一个很重要的问题就是误差传播。即在上一个子任务出现的错误会影响下一个子任务的准确性。在这个任务上表现为边界的错误检测。我们发现,边界的错误检测主要出现在领域特定的属于中并且这些特定属于如化学式在通常在字符级别上有着一些相似的特征。
举例来说,如果我们考虑医学领域,其中可能包含诸如"cardiovascular"(心血管的)和"cardiopulmonary"(心肺的)这样的术语。在字符级别上,它们都以"cardio"开头,这是它们的共同模式。这种共同模式可以帮助研究人员或自然语言处理系统更好地理解这些术语,并将它们分类到医学领域中。
因此我们添加Character Sequence Feature和Orthographic Pattern Feature来构建模型。
Character Sequence Feature
该特征的提取使用了五个卷积神经网络(CNNs)来学习每个标记的字符级表示,以及16个过滤器和50个输入通道。CNN的卷积核大小从1到5用于提取不同长度的特征。先将词汇转换成词向量,
并通过卷积后通过全连接层获得一个 768维向量的字符表示。其模型结构如下图所示:
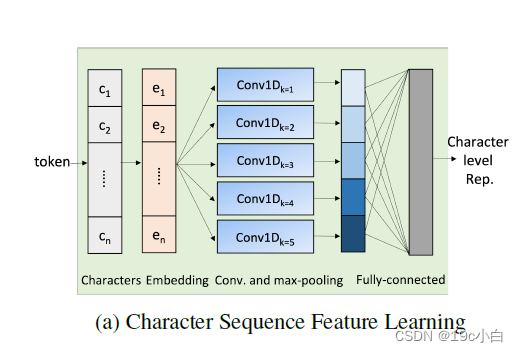
字符级特征提取器
Orthographic Pattern Feature
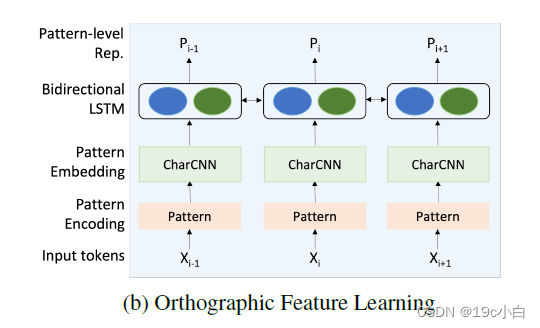
正字法模式特征,即在文本中关于字符形态和视觉特征的特性或模式。该系统使用了一种基于模式的方法来捕捉特定领域术语的语法和形态学特征。它将所有大写字母的标记映射到单个字符U,所有小写字母的标记映射到L,所有数字标记映射到D。如果一个标记包含大写字母、小写字母和数字的混合,那么将每个小写字母字符映射到l,大写字母映射到u,数字映射到d。特殊字符保留,BERT的特殊标记"[CLS]"和"[SEP]"分别映射到C和S。这些特征被证明可以提高命名实体识别的准确性。编码之后进入一个与上文相似的三层CNN中,卷积核从1到3而后再送入一个双向LSTM中获取token的模式级嵌入。模型结构如图所示:
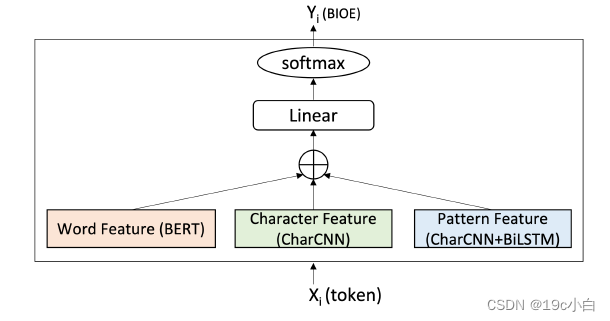
最后将两个特征与bert连接起来提供给分类器层。
2.2 span classification
如最开始的图片所示,其输入为相应的句子与句子中所检测到的span,分别将每个span送入该模型进行识别,并得到答案。
文中并未给出该模型的结构图,据其所说,其先结构一层bert,后将该序列嵌入池化并送入全连接层转换未实体类型的概率分布。(应该是使用了softmax)
3.实验结果
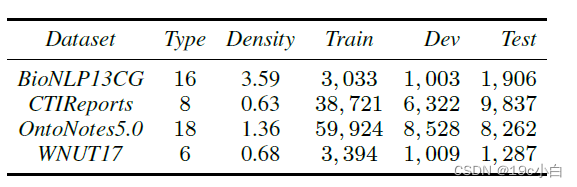
使用的数据集,CTIReports是网络安全的私有数据集,其他为公共数据集。
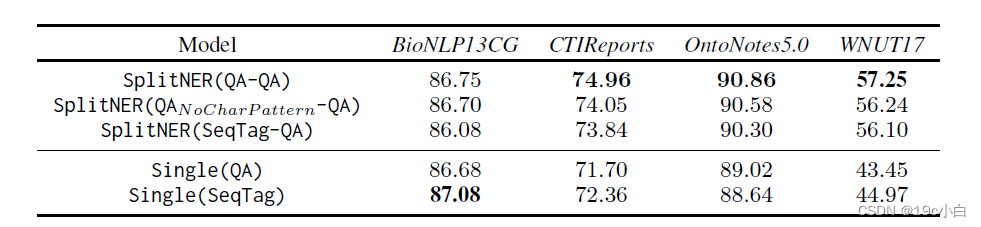
识别的准确率:
训练时间和推断时间
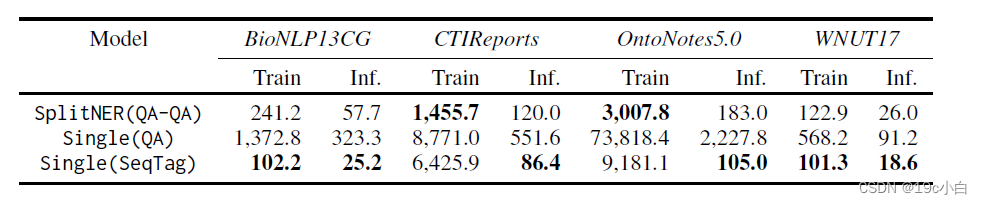
从中可以看出这种模型兼顾了效率和准确性。
在实验中他也测试了不加入char feature和pattern feature的模型,发现其准确性有所下降。

















 3288
3288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









