






摘要
MOBA游戏,例如王者荣耀,英雄联盟和Dota2,对AI系统构成很大的挑战,如multi-agent,巨大的状态动作空间,复杂的动作控制等。开发一个能够玩Moba游戏的AI已经吸引了大量研究人员的注意。然而,当将OpenAI仅限制在17个英雄的池中Dota AI扩大英雄池时,现有工作无法处理由agent组合形成的动作空间爆炸,即阵容。因此,没有限制的完整Moba游戏远远不能被任何现有的AI系统掌握。在本文中,我们提出了一个MOBA AI的学习框架,该方法能够使用深度强化学习玩所有的MOBA游戏。具体而言,我们提出将新的学习技巧和现有的学习技巧的组合,包括curriculum self-play学习,策略蒸馏,离线策略适应,多头值估计和蒙特卡罗树搜索,以在一个大的英雄池上训练和玩游戏。王者荣耀是一个受欢迎的MOBA游戏,我们展示了如何构建可以击败顶级电子竞技玩家的超级AI agent。通过对本文中的Moba AI agent进行大规模的性能测试,证明了我们AI的优势。
1.介绍
用于玩游戏的人工智能,也称为游戏AI,已经被持续研究了几十年。我们目睹了AI agent在许多类型游戏上的成功,包括围棋,雅达利系列,第一人称射击(FPS)游戏(如夺旗赛),电子游戏(如任天堂明星大乱斗)以及卡牌游戏(如扑克)等等 。现如今,具有复杂策略的电子游戏吸引了人们的关注,因为它们捕捉了真实世界的性质,例如,2019年,AlphaStar在通用实时策略(RTS)游戏(StarCraft 2)中达到了grandmaster段位。
作为RTS游戏的子类型,多人在线竞技游戏(MOBA)最近也引起了很多关注。由于其游戏机制涉及多个agent进行竞争和合作,并且包含不全面的信息,复杂的动作控制和巨大的状态空间,MOBA被认为是AI研究优选的测试平台。典型的MOBA游戏包括王者荣耀,Dota和英雄联盟。在复杂性方面,一个MOBA游戏(例如王者荣耀),即使具有显着的离散性,也可以具有
1
0
20000
10^{20000}
1020000 数量级的状态和动作空间,而传统的游戏AI测试平台最多是
1
0
360
10^{360}
10360数量级。 MOBA游戏通过使用多个英雄,从而使实时策略进一步复杂化(每个英雄具有独特的技能,旨在拥有不同的游戏机制),特别是在5V5模式中,两支队伍(每支都有5位选手从英雄池中选择的英雄) )相互竞争的情况。
尽管它适用于AI研究,要想掌握了MOBA游戏仍然是当前AI系统一个重大的挑战。目前针对MOBA 5v5游戏最好的工作是OpenAI Five,其使用self-play强化学习(RL)在Dota2中训练agent。然而,OpenAI Five训练受到一个主要的限制,即只能使用17个英雄,然而英雄机制,团队协作和竞争才是MOBA游戏的灵魂。
作为能够玩所有MOBA游戏的最重要的基础,扩增英雄池对self-play强化学习是一个重大的挑战,因为agent相互组合(即阵容),与英雄池大小的数量呈多项式增长。17个英雄池的agent组合为 4,900,896(
C
17
10
×
C
10
5
C^{10}_{17}×C^{5}_{10}
C1710×C105),当增加到40个英雄池时,组合爆炸到 213,610,453,056(
C
40
10
×
C
10
5
C^{10}_{40}×C^{5}_{10}
C4010×C105)。考虑到每个MOBA英雄是独一无二的,即使是经验丰富的人类玩家也具有特定的英雄池,通过随机使用任意英雄的组合来进行学习的现有方法可能会导致“学习崩溃”,这可在OpenAI Five和我们的实验中观察到。例如,OpenAI试图将英雄池扩展到25个英雄,会导致训练变得缓慢而不可接受,同时还降低了AI的性能(可从文献[24]中了解“更多英雄”的细节)。因此,我们需要MOBA AI学习一个方法,这些方法能处理由扩展英雄池引起的可扩展性相关问题。
在本文中,我们提出了一个学习框架,用于支持使用深度强化学习玩所有的MOBA游戏。在 actor-learner 模式下,我们首先构建一个分布式的RL基础架构,以off-policy方式生成训练数据。然后,我们开发一个统一的actor-critic网络架构,以捕捉不同英雄的游戏机制和动作。要处理由游戏情节的多样性造成的策略偏差,我们应用off-policy adaption,与[38]类似。为了管理游戏中的状态动作的不确定值,我们通过分组奖励将多值估计引入MOBA。受自神经网络curriculum learning想法的启发,我们为MOBA游戏multi-agen的t训练设计了课程,我们一开始使游戏简单,然后再逐渐增加学习难度。特别地,我们从固定阵容开始获取teacher模型,我们从中蒸馏策略,最后我们执行合并的训练。我们利用student-driven的策略蒸馏来将知识从简单的任务转移到困难的任务。最后,开始考虑扩展英雄池这一个新的问题,即在游戏开始时进行英雄选择。用于在小英雄池中使用的Minimax算法不可行。为了处理这一点,我们开发基于Monte-Carlo树搜索(MCT)的高效且有效的agent。
请注意,由于在真实游戏中评估AI agent的代价昂贵,目前在文献中仍然缺乏对游戏AI的大规模性能测试。例如,AlphaStar Final和OpenAI Five被进行如下测试:1)分别与专业人士进行了11场比赛和8场比赛;2)分别与公众进行90场和7,257场比赛(所有级别的玩家都可以参加,没有进入条件)。为了提供更大的统计学意义的评估,我们进行了大规模的MOBA AI测试。具体而言,我们使用王者荣耀进行测试,这是一个受欢迎并且经典的typical游戏,这已被广泛用作最近AI的测试平台。在42次与专业选手的比赛中,AI胜率为95.2%,而在与高段位玩家的 642047 场比赛,AI胜率为97.7%。
总而言之,我们的贡献有:
- 我们提出了一种新的 MOBA AI学习框架,以便使用强化学习玩所有的MOBA游戏。
- 我们开展了MOBA AI agent的第一个大规模性能测试。广泛的实验表明,我们的AI可以击败顶级的电子竞技玩家。
2.相关工作
我们的工作属于针对策略类电子游戏的系统级AI开发,因此我们主要讨论沿着这条线的代表工作,主要包括RTS和MOBA游戏。
General RTS games。StarCraft已经多年被作为RTS游戏中用于AI研究的测试平台。现有研究采用的方法包括基于规则的,有监督学习,加强学习及其组合。对于基于规则的方法,代表工作是SAIDA,它是2018年星际争霸AI竞技的冠军(见https://github.com/teamsaida/saida)。对于基于学习的方法,最近,AlphaStar联合有监督学习和multi-agent强化学习,并在StarCraft2中达到了grandmaster段位。与AlphaStar的类似,我们的价值估算(第3.2节)也使用不可见的竞争对手的信息。
MOBA games。最近,为MOBAGame Ai提出了一个名为Tencent HMS的宏观策略模型。具体地,HMS是用于指导agent在游戏期间应该移动到地图上哪一点的功能组件,其不考虑agent动作的执行,即,电子竞技中的微观控制或微观管理,因此HMS不是完整的AI解决方案。最相关的工作是Tencent Solo和OpenAI Five。Ye et al. 对不同MOBA英雄的游戏机制进行了彻底和系统的研究。他们开发了一个RL系统,用于掌握MOBA战斗中agent的微观控制。但是,这个工作没有研究更复杂的multi-agent 5V5游戏的情况,只研究了1V1 solo游戏。另一方面,本工作与 Ye et al. 之间的相似之处包括:动作的建模(价值网络是不同的)和离线策略纠正(Adaption)。2019年,OpenAI提出了一个在Dota2中完5V5游戏的AI,称为OpenAI Five,其具有打败专业人类玩家的能力。OpenAI Five使用了self-paly深度强化学习,并使用近端策略优化(PPO)训练。我们的工作与OpenAI Five的主要区别在于本文的目标是开发能够玩所有MOBA游戏的AI程序。因此,理论上,我们引入了一系列的技术,包括off-policy adaption,curriculum self-play learning,value estimation和tree-search,以解决训练中的可扩展性问题。另一方面,这项工作与OpenAI Five的相似之处包括:用于建模MOBA英雄的动作空间的设计,使用循环神经网络(如LSTM)处理部分可观察状态,以及使用一个共享权重的模型来控制所有的英雄。
3.学习系统
为解决MOBA游戏的复杂性,我们将新的技术和现有的学习技术的组合,例如神经网络架构,分布式系统,强化学习,multi-agent训练, curriculum learning和蒙特卡罗树搜索。虽然我们用王者荣耀作为研究平台,但这些技术也适用于其他MOBA游戏,因为MOBA游戏中的游戏机制是相似的。
3.1 Architecture
MOBA可以被看作具有部分可观测状态的multi-agent Markov游戏。我们AI的核心是使用具有参数
θ
θ
θ的深度神经网络来表示的策略
π
θ
(
a
t
∣
s
t
)
π_θ(a_t|s_t)
πθ(at∣st)。它从游戏中接收先前时刻的状态和动作
s
t
=
o
1
:
t
,
a
1
:
t
−
1
s_t=o_{1:t},a_{1:t-1}
st=o1:t,a1:t−1作为输入,然后选择
a
t
a_t
at作为输出。在网络内部,可观测状态
o
t
o_t
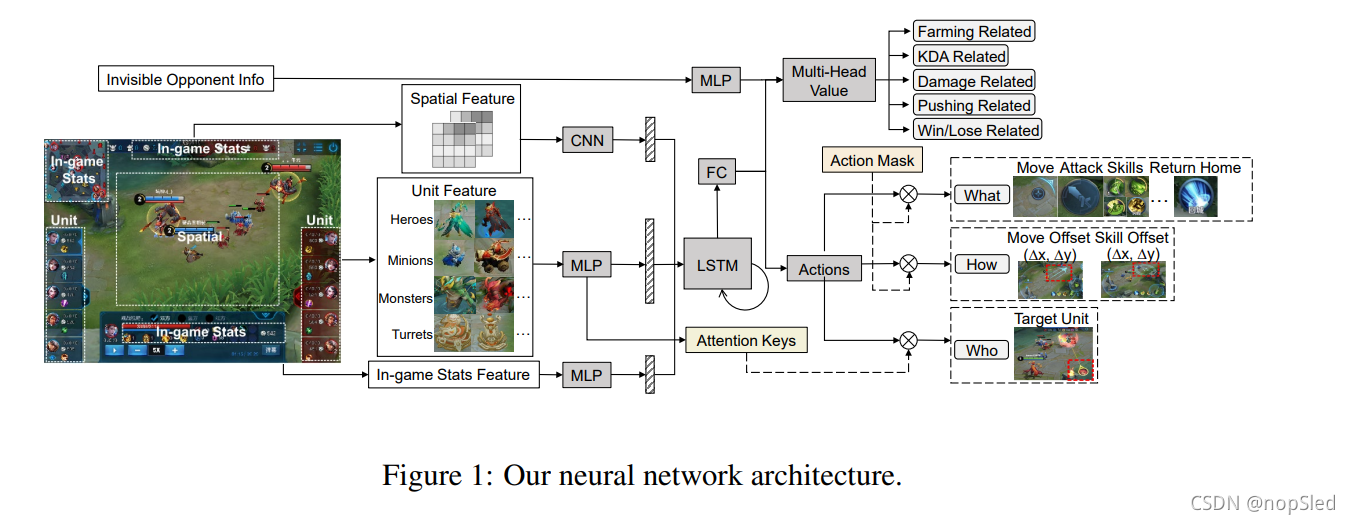
ot通过卷积和全连接层进行编码,并组合成矢量表示序列,然后再由深度序列网络处理这些表示序列,并最终映射到需要选择的动作的概率分布上。网络整体架构如图1所示。
该架构由建模复杂MOBA游戏的通用网络组件组成。为了提供给agent丰富的观测信息,我们提出建模多模态特征,包括特征由标量和空间特征组成的综合列表。标量特征由可观测的单元属性,游戏中的统计信息和对手的不可见信息组成,例如,健康点(HP),技能冷却时间,金币数,英雄等级等。空间特征由从英雄的局部视野中提取的卷积通过组成。为了处理部分可观测性,我们使用LSTM以建模各步骤之间的关系。为了帮助目标选择,我们使用目标注意力,其使用LSTM编码后的向量作为query,以编码的游戏单位作为key。为了消除不必要的RL探索过程,类似于[38],我们设计动作屏蔽机制。为了管理MOBA的动作组合空间,我们提出一个分离的动作目标。具体而言,AI在分离的目标中输出如下预测的动作:1)采取哪些动作,例如移动,攻击,技能释放等;2)动作使用的目标,例如炮塔,敌人英雄或其他人;3)动作使用的范围,例如离散化的移动方向,技能释放方向。
3.2 Reinforcement Learning
我们使用actor-critic方法,其使用策略
π
θ
(
a
t
∣
s
t
)
π_θ(a_t|s_t)
πθ(at∣st)训练一个价值函数
v
θ
(
s
t
)
v_θ(s_t)
vθ(st)。我们使用离线策略进行训练,即,使用经验回放池来异步更新模型。
具有大量英雄池的MOBA游戏被视为强化学习问题时会面临如下几个挑战:(1)由于长期视野,组合动作空间大和动作关联度高,离线政策学习可能是不稳定的;(2)在游戏期间,英雄及其周围环境会随时发生变化,使得难以设计奖赏,估计状态以及动作的价值。
Policy updates。我们假设各动作目标之间是独立的,以简化动作目标之间的相关性,例如,技能释放方向(“HOW”)是以技能类型(“WHAT”)为条件的,其类似于[38,33] 。在我们的大规模分布式环境中,轨迹从各种策略来源采样,这可能与当前策略
π
θ
π_θ
πθ有偏差。 为避免训练不稳定,我们使用 Dual-clip PPO,这是PPO算法的离线策略优化版本。考虑到当
π
θ
(
a
t
(
i
)
∣
s
t
)
≫
π
θ
o
l
d
(
a
t
(
i
)
∣
s
t
)
π_θ(a^{(i)}_t|s_t)\gg π_{θ_{old}}(a^{(i)}_t|s_t)
πθ(at(i)∣st)≫πθold(at(i)∣st),并且
A
^
t
<
0
\hat A_t \lt 0
A^t<0时,由于
r
t
(
θ
)
A
^
t
≪
0
r_t(\theta)\hat A_t\ll 0
rt(θ)A^t≪0,比率
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
o
l
d
(
a
t
∣
s
t
)
r_t(θ)=\frac{π_θ(a_t|s_t)}{π_{old}(a_t|s_t)}
rt(θ)=πold(at∣st)πθ(at∣st)将会引入一个很大且无界的方差。为了解决该问题,当在
A
^
t
<
0
\hat A_t<0
A^t<0时,Dual-clip PPO在目标中引入用于裁剪的超参数
C
C
C:
L
p
o
l
i
c
y
(
θ
)
=
E
^
t
[
m
a
x
(
m
i
n
(
r
t
(
θ
)
A
^
t
,
c
l
i
p
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
^
t
)
,
c
A
^
t
)
]
.
(1)
\mathcal L^{policy}(\theta)=\hat {\mathbb E}_t[max\big (min\big (r_t(\theta)\hat A_t, clip(r_t(\theta),1-\epsilon,1+\epsilon)\hat A_t \big ),c\hat A_t\big )].\tag{1}
Lpolicy(θ)=E^t[max(min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t),cA^t)].(1)
其中
c
>
1
c>1
c>1表示下限,并且
ϵ
\epsilon
ϵ是PPO中的传统裁剪参数。
Value update。为了减少价值估计的方差,类似于[33],我们使用有关游戏状态的完整信息,包括来自策略隐藏状态的观测值,以作为价值函数的输入。请注意,这仅在训练期间执行,因为我们在评估期间仅使用策略网络。为了更准确地估计不断变化的游戏状态的价值,我们将multi-head value (MHV) 引入MOBA中已进行奖赏的分解,这是受Atari的游戏Ms. Pac-Ma启发的。具体而言,我们设计五个奖赏类别作为五个价值头,如图1所示,基于游戏专家的知识和每个头部的累积价值损失。这些价值头和每个头部所包含的奖赏项有:1)) Farming related:金币,经验,法力,击杀小兵数,无动作;2) KDA related:击杀,死亡,助攻,暴君Buff,霸主Buff,视野,最后一次击中;3)Damage related:健康点,英雄伤害量;4)Pushing related:攻击炮塔,攻击敌人的基地l;5)Win/lose related:摧毁敌人的基地。
L
v
a
l
u
e
(
θ
)
=
E
^
t
[
∑
h
e
a
d
k
(
R
t
k
−
V
^
t
k
)
2
]
,
V
^
t
=
∑
h
e
a
d
k
w
k
V
^
t
k
,
(2)
\mathcal L^{value}(\theta)=\hat{\mathbb E}_t[\sum_{head_k}(R^k_t-\hat V^k_t)^2],\quad \hat V_t=\sum_{head_k}w_k\hat V^k_t,\tag{2}
Lvalue(θ)=E^t[headk∑(Rtk−V^tk)2],V^t=headk∑wkV^tk,(2)
其中
R
t
k
R^k_t
Rtk和
V
^
t
k
\hat V^k_t
V^tk分别是第k个头的衰减奖赏总和和价值估计。然后,总的价值估计是各头部价值估计的加权和。
3.3 Multi-agent Training
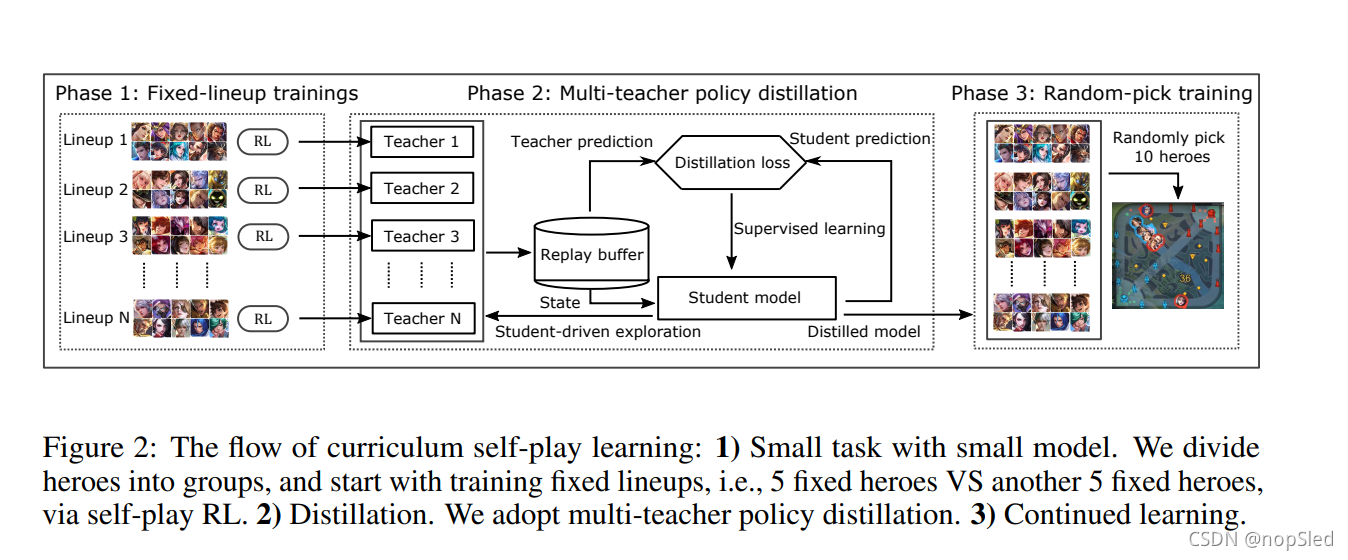
如上所述,英雄池增加会导致产生大量阵容组合。当使用self-play强化学习时,10个agent在玩MOBA游戏时会面临着非静止移动目标问题(non-stationary moving-target)。此外,阵容会随着self-play发生变化,使策略学习更加困难。之前提出的用于训练的无序agent组合会导致模型性能退化。因此,这需要一个范例来指导MOBA的agent学习。
受课程学习思想的启发,即机器学习模型可以在训练样例以有意义的顺序组合而不是无序构建时,性能变得更好,这说明了逐渐递增难度的概念。因此,我们提出了curriculum self-play learning (CSPL)来指导MOBA AI的学习。CSPL包括图2中的三个阶段,正如下面将描述的。在CSPL中判断是否晋级到下一阶段的规则是基于ELO分数的收敛。
(1)阶段1
在第1阶段,我们通过训练固定阵容来开始简单的任务。具体而言,在具有40个英雄的情况下,我们将英雄划分为四组,其中每组10个英雄。然后,为每个组单独执行self-play。10个英雄的分组是基于两个英雄团队胜利率都接近50%来切分。阵容的胜利率可以从大量人类玩家的数据中获得。我们之所以选择平衡的团队,是因为能有效地推动对self-play策略的改进。为训练teachers,我们使用较小的模型,即使用阶段3中最终模型几乎一半的参数,这将在第4.1节中详述。
(1)阶段2
在第2阶段,我们关注如何继承来自于固定阵容self-play所掌握的知识。具体而言,我们使用 multi-teacher policy 蒸馏,即使用阶段1训练的模型作为teacher模型
(
π
)
(π)
(π),这些模型都被合并到单个student模型
(
π
θ
)
(π_θ)
(πθ)中。蒸馏是一个有监督训练的过程,使用等式3中的损失函数,其中
H
×
(
p
(
s
)
∣
∣
q
(
s
)
)
H^×(p(s)||q(s))
H×(p(s)∣∣q(s))表示两个动作分布
−
E
a
∼
p
(
s
)
[
l
o
g
q
(
a
∣
s
)
]
-E_{a\sim p(s)}[log~q(a|s)]
−Ea∼p(s)[log q(a∣s)]之间的香农交叉熵,
q
θ
q_θ
qθ是采样策略,
V
^
(
k
)
(
s
)
\hat V^{(k)}(s)
V^(k)(s)是价值函数,
h
e
a
d
k
head_k
headk表示上一节中提到的第
k
k
k个价值头。
L
d
i
s
t
i
l
l
(
θ
)
=
∑
t
e
a
c
h
e
r
i
E
^
π
θ
[
∑
t
H
×
(
π
i
(
s
t
)
∣
∣
π
θ
(
s
t
)
)
+
∑
h
e
a
d
k
(
V
^
i
k
(
s
t
)
−
V
^
θ
k
(
s
t
)
)
2
]
.
(3)
\mathcal L^{distill}(\theta)=\sum_{teacher_i}\mathbb {\hat E}_{\pi_{\theta}}[\sum_tH^×(\pi_i(s_t)||\pi_{\theta}(s_t))+\sum_{head_k}(\hat V^k_i(s_t)-\hat V^k_{\theta}(s_t))^2].\tag{3}
Ldistill(θ)=teacheri∑E^πθ[t∑H×(πi(st)∣∣πθ(st))+headk∑(V^ik(st)−V^θk(st))2].(3)
使用交叉熵损失和价值预测的均方误差损失,我们对所有teacher的损失进行相加。因此,学生模型从具有固定阵容的teacher蒸馏出策略和价值知识。在蒸馏过程中,student模型在teacher模型训练的固定阵容环境中探索,这种方法称为student-driven 策略蒸馏。探索将输出动作,状态和teacher的预测(用作监督学习的指导信号),并将其重入经验回放缓冲区。
(1)阶段3
在第3阶段,我们使用来自第2阶段的蒸馏模型进行模型初始化,并继续进行训练。
3.4 Learning to draft
通过扩大英雄池带来的新出现的问题是drafting,也称为,英雄选择。在MOBA比赛开始之前,两支队伍开始进行英雄选择,这直接影响了比赛中的策略和匹配结果。给定大的英雄池,例如40个英雄(超过
1
0
11
10^{11}
1011个组合),一种完整的树搜索方法,如OpenAI Five的Minimax算法,其计算代价很大。
为了解决这一点,我们提出了利用Monte-Carlo树搜索(MCT)和神经网络构建的英雄选择agent。MCTS估计每个选择的长期值,以及具有最大选取值的英雄。我们使用的特定MCTS版本是UCT(Upper Confidence bounds Tree)。在选择时,迭代地构建一个搜索树,每个节点表示状态(两个团队选中哪些英雄),每个边表示动作(选择一个未被选中的英雄),生成下一个状态。
搜索树是基于迭代的MCTS的四个步骤来更新,即选择,扩展,模拟和反向传播,在这些步骤中,模拟步骤是最耗时的。为了加速模拟,与[5]不同,我们构建一个价值网络,直接预测当前状态的值,而不是进行低效的随机模拟,以获得反向化的奖赏,这类似于 AlphaGo Zero 。通过基于MCTS的两个英雄选择策略模拟的起草过程来收集价值网络的训练数据。在训练价值网络时,仍然执行Monte-Carlo搜索,直到到达终端状态,即模拟起草过程的结束。请注意,对于像国际象棋等棋盘游戏,终端状态由获胜者决定。但是,英雄选择过程的结束不是MOBA游戏的结束,因次我们无法直接得到游戏结果。要处理此方法,我们首先使用第3.3节中训练的RL模型进行self-paly来构建匹配数据集,然后我们训练一个神经预测器以预测特定阵容的赢率。终端状态的预测胜率用作训练价值网络的监督信号。价值网络的架构和胜率预测器是两个单独的3层MLP。对于胜率预测器,输入特征是阵容中10个英雄的one-hot表示,输出是从0到1的胜率。对于价值网络,输入表示是目前阵容的游戏状态,包括两种队伍选择英雄的one-hot索引,为选择英雄的默认索引以及当前选择队伍的索引。另外,在我们实现中的选择,扩展和反向传播步骤与普通MCT相同。
3.5 Infrastructure
为了解决MOBA agent引入的随机梯度的方差,我们提出可扩展的松耦合的基础架构,以提高数据并行性的效率。具体来说,我们的基础架构遵循经典的Actor-Learner设计模式。我们的策略在Learner上使用GPU培训,而使用CPU在Actor上进行self-paly。 包含观测序列,动作,奖赏等,从Actor到Learner上的局部回放缓冲区采用异步传递。我们也致力于提高系统吞吐量,例如,CPU和GPU之间的传输调解器设计,GPU的IO成本降低,类似于[38]。但与[38]不同,我们进一步开发了GPU侧的集中推理模块,以优化资源利用率,类似于最近一个名为Seed RL的基础架构中的Learner设计。

















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









