






摘要
神经机翻译(NMT)模型在许多翻译基准上达到了最先进的性能。作为NMT中的活跃研究领域,通过迁移teacher模型在每个训练样例上的知识,知识蒸馏被广泛应用来提高模型的性能。然而,以前的工作很少讨论作为迁移teacher知识媒介的不同样本之间的影响和关系。在本文中,我们设计了一种新的协议,可以通过比较各种样本的内容来有效地分析样本的不同影响。基于上述协议,我们进行广泛的实验,并发现teacher的知识并不是越多越好。对特定样本的知识甚至可能会损害知识蒸馏的整体性能。最后,为了解决这些问题,我们提出了两种简单但有效的策略,即batch-level和global-level选择,以挑选适当的样本进行蒸馏。我们在两种大型机器翻译任务(WMT’14 English-German和WMT’19 Chinese-English)上评估了我们的方法。实验结果表明,我们的方法在Transformer基线上分别提高了+1.28和+0.89的BLEU分。(https://github.com/LeslieOverfitting/selective_distillation)
1.介绍
通过使用序列到序列模型,机器翻译任务已经取得了很大的进步。最近,在机器翻译中提出了一些知识蒸馏方法,通过从teacher模型迁移知识来帮助改善模型性能。基于teacher信息的粒度,这些方法可分为两类:单词级和序列级。在这些工作的研究中,模型在无差别的情况下最小化样本中每一个单词或句子和teacher模型的输出差距,来学习teacher知识。
尽管实验结果很有效果,但是先前的研究主要集中在寻找迁移的方法,而很少调查这些单词/句子(即样本)中的哪些能够作为迁移教师知识的媒介来参与知识蒸馏。对于这些样本仍然有若干未解决的问题:样本中的哪个部分能对知识蒸馏更有效?直观上,我们可能会认为较长的句子难以翻译,并且可能带有更多的teacher知识。但是还有更多这些标准,可以识别这些重要的或合适的样本进行蒸馏吗?此外,这些样本之间的关系是什么?他们都在朝相同的方向指导student模型吗?通过调查teacher知识的媒介,我们可以寻找最有效的KD方法。
因此,在本文中,我们的目标是调查所有样本中的影响和差异。但是,分析它们中的每一个是不现实的。因此,我们通过新的标准(例如,句子长度或单词交叉熵)将样本划分为两个部分,并提出一种新的分析协议,来研究性能之间的差距。通过广泛的经验实验,来分析最合适的样本以进行知识迁移。我们发现不同的样本在迁移知识方面有所不同。更有趣的是,对于一些部分,特别是student模型的字交叉熵,其中使用一半知识的模型甚至显示了比使用所有蒸馏知识的模型更好的性能。这种现象揭示了两个部分的蒸馏多带来的增益不能单纯累加,甚至还会伤害整体性能。因此,KD方法需要更复杂的选择性策略。
接下来,基于单词交叉熵(Word CE,我们发现这是最有区分性的标准),我们提出了两个简单但有效的方法来解决所观察到的现象。我们首先提出了一种batch-level选择策略,可以在当前batch分布中选择具有很高Word CE的单词。进一步地,为了能从局部(batch)分布到全局分布,我们使用global-level的FIFO队列来近似最佳全局选择策略,该策略缓存了几个步骤的Word CE分布。我们在两种大型机器翻译任务(WMT’14 English-German和WMT’19 Chinese-English)上评估了我们的方法。实验结果表明,我们的方法在Transformer基线上分别提高了+1.28和+0.89的BLEU分。
总之,我们的贡献如下:
- 我们提出了一种新的协议,用于分析适用于迁移teacher知识的媒介样本的属性。
- 我们进行广泛的分析,发现一些teacher的知识会损害知识蒸馏的整体效果。
- 我们提出了两种选择性策略:: batch-level选择和global-leve选择。实验结果验证了我们的方法是有效的。
2.相关工作
知识蒸馏方法旨在将teacher模型的知识迁移到student模型。最近,在自然语言处理领域,通过使用teacher模型的输出或隐藏状态,许多知识蒸馏方法已经被用来获取有效的student模型。
对于神经机翻译(NMT),知识蒸馏方法通常侧重于通过teacher模型更好地改善student模型。Kim and Rush (2016) 首先将知识蒸馏应用到NMT,并提出了sequence-level知识蒸馏,让student模型模拟teacher模型生成的序列分布。这种方法被Gordon and Duh (2019)作为一种数据增强和正规化方法。此外,Freitag et al. (2017) 通过使用ensemble模型作为teacher模型提高了蒸馏信息的质量。Gu et al. (2017) 通过从自回归模型学习的蒸馏信息来改善非自回归模型性能。Wu et al. (2020) 提出了一种适用于深度神经网络的分层蒸馏方法。Chen et al. (2020b) 让翻译模型从语言模型中学习,以帮助生成机器翻译质量。
据我们所知,NMT中还没有工作来研究如何选择合适的样本已进行知识蒸馏。少数相关的工作的主要是专注于如何为student模型选择合适的teacher模型来学习。例如,Tan et al. (2019) 让student模型仅从其性能比它好的teacher模型中学习。Wei et al. (2019) 提出了一种在线知识蒸馏方法,让模型从历史checkpoints选择性地学习。与上述方法不同,我们探讨了来自样本方面的有效选择性蒸馏策略,让每个样品决定学习的内容和程度。
3.背景知识
3.1 Neural Machine Translation
给定一个源句
x
=
(
x
1
,
.
.
.
,
x
n
)
\textbf x=(x_1,...,x_n)
x=(x1,...,xn),它对应的真实目标翻译句子为
y
=
(
y
1
∗
,
.
.
.
,
y
m
∗
)
\textbf y=(y^*_1,...,y^*_m)
y=(y1∗,...,ym∗),NMT模型通过计算交叉熵来最小化每个位置的负对数似然。对于目标句子中的第
j
j
j个单词,损失可以定义为:
L
c
e
=
−
∑
k
=
1
∣
V
∣
1
{
y
j
∗
=
k
}
l
o
g
p
(
y
j
=
k
∣
y
<
j
,
x
;
θ
)
,
(1)
\mathcal L_{ce}=-\sum^{|V|}_{k=1}\mathbb{1}\{y^*_j=k\}log~p(y_j=k|\textbf y_{\lt j},\textbf x;\theta),\tag{1}
Lce=−k=1∑∣V∣1{yj∗=k}log p(yj=k∣y<j,x;θ),(1)
其中
∣
V
∣
|V|
∣V∣是目标词汇的大小,
1
1
1是指示韩式,
p
(
⋅
∣
⋅
)
p(·|·)
p(⋅∣⋅)表示由θ参数化的模型的条件概率。
3.2 Word-level Knowledge Distillation
在知识蒸馏中,student模型
S
S
S通过将自己的输出与teacher模型
T
T
T的输出概率匹配来获得额外的监督信号。具体地,word-level知识蒸馏定义了student和teacher的输出分布之间的KL散度。去除常数后,目标被定义为:
L
k
d
=
−
∑
k
=
1
∣
V
∣
q
(
y
j
=
k
∣
y
<
j
,
x
;
θ
T
)
×
l
o
g
p
(
y
j
=
k
∣
y
<
j
,
x
;
θ
S
)
,
(2)
\mathcal L_{kd}=-\sum^{|V|}_{k=1}q(y_j=k|\textbf y_{\lt j},\textbf x;\theta_{T})\times log~p(y_j=k|\textbf y_{\lt j},\textbf x;\theta_S),\tag{2}
Lkd=−k=1∑∣V∣q(yj=k∣y<j,x;θT)×log p(yj=k∣y<j,x;θS),(2)
其中
q
(
⋅
∣
⋅
)
q(·|·)
q(⋅∣⋅)是teacher模型的条件概率。
θ
S
θ_S
θS和
θ
T
θ_T
θT分别是student模型和teacher模型的参数。
然后,总的训练目标是最小化下面两个训练目标的总和:
L
=
L
c
e
+
α
L
k
d
,
(3)
\mathcal L=\mathcal L_{ce}+\alpha \mathcal L_{kd},\tag{3}
L=Lce+αLkd,(3)
其中
α
α
α是平衡两个损失的权重。
4. Are All Words Equally Suitable for KD ?
如前所述,作为传播teacher知识的媒介,真实目标单词可能会极大地影响知识蒸馏的性能。因此,在本节中,我们首先做了一些初步的实验研究,以评估不同单词/句子在知识蒸馏中的重要性。
4.1 Partition of Different Parts
分析样本对蒸馏不同影响的最佳方式是对数据中的每条都进行消融研究,显然,这是不可能的。因此,我们通过使用分区和比较作为近似来提出分析协议,我们认为这可以足以阐明分析结果。特别地,我们利用特定的准则
f
f
f将样本分为两个互补的部分:
S
H
i
g
h
≔
{
y
i
∣
f
(
y
i
)
>
M
e
d
i
a
n
(
f
(
y
)
)
,
y
i
∈
y
}
,
S
L
o
w
≔
{
y
i
∣
f
(
y
i
)
≤
M
e
d
i
a
n
(
f
(
y
)
)
,
y
i
∈
y
}
,
\begin{array}{cl} S_{High}\coloneqq \{y_i|f(y_i)\gt Median(f(\textbf y)),y_i\in \textbf y\},\\ S_{Low}\coloneqq \{y_i|f(y_i)\le Median(f(\textbf y)),y_i\in \textbf y\}, \end{array}
SHigh:={yi∣f(yi)>Median(f(y)),yi∈y},SLow:={yi∣f(yi)≤Median(f(y)),yi∈y},
然后,分析
S
H
i
g
h
S_{High}
SHigh和
S
L
o
w
S_{Low}
SLow之间的不同影响。其中每个部分都是单词/句子的50%。准则来自三个不同的方面:数据属性,student模型和teacher模型。详细描述如下:
- Data Property。由于长句子和稀有词对于翻译更具挑战性,其相应的teacher知识可能会更有益于student模型。因此,我们以句子长度和词频作为准则。
- Student Model。对于student模型,我们关心student模型是否认为这些单词/句子太复杂。因此,我们使用Word CE(单词的交叉熵),sentence CE(句子中所有单词交叉熵的平均值),以及每个目标单词对应嵌入的标准差作为准则。
- Teacher Model。对于teacher模型,我们猜测teahcer的预测置信度可能对知识迁移至关重要。因此,我们使用真实标签的预测概率( P g o l d e n P_{golden} Pgolden)和预测分布的熵作为我们的准则。
4.2 Analytic Results
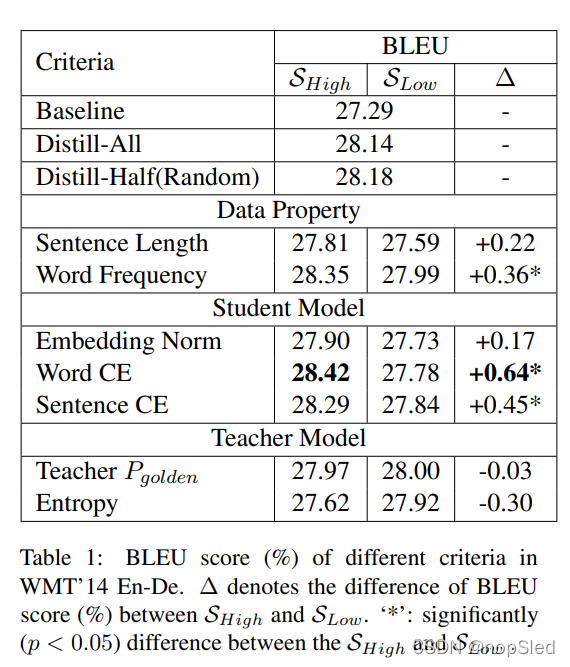
表1显示了我们在不同准则上的结果。我们还增加了Transformer基线,Distill-All(用所有单词蒸馏)和Distill-Hal(随机选择50%单词蒸馏)进行性能比较。
Impact of Different Parts。从表中,我们观察到
S
H
i
g
h
S_{High}
SHigh和
S
L
o
w
S_{Low}
SLow在BLEU分数上具有明显差距,这表明传播教师知识的媒介之间存在差异。具体地,对于大多数准则,如交叉熵或词频,两个部分之间的差距超过0.35。相比之下,teacher的
P
g
o
l
d
e
n
P_{golden}
Pgolden似乎无法区分KD的知识。我们猜测这是因为无论老师是否相信真实标签,其他软标签可能也会包含有用的信息。此外,我们发现student的熵是区分KD数据的足够良好的准则,这和以前的dark knowledge研究类似。最后,我们发现使用Word CE准则的KD是最好的,它在训练阶段享有适应性,能够表示是否学生认为该样本难以学习。
总之,我们认为最合适的样本应该具有以下性质:更高的Word CE,更高的Sentence CE,更高的Word Frequency,这可能有利于未来的有效KD方法研究。
Impact of All and Halves。更有趣的是,与 Distill-All 相比(即
S
H
i
g
h
\mathcal S_{High}
SHigh和
S
L
o
w
\mathcal S_{Low}
SLow的组合),基于Word CE,Sentence CE和Word Frequency准则划分的
S
H
i
g
h
\mathcal S_{High}
SHigh的BLEU评分超过了Distill-All。因此产生了下面两个结论:
(1)在这些分区中,
S
H
i
g
h
\mathcal S_{High}
SHigh在KD性能改进中具有较大贡献。
(2)用于迁移teacher知识的数量不是越多越好。
S
L
o
w
\mathcal S_{Low}
SLow中的蒸馏知识无法直接与
S
H
i
g
h
\mathcal S_{High}
SHigh组合,甚至会伤害
S
H
i
g
h
\mathcal S_{High}
SHigh的性能。
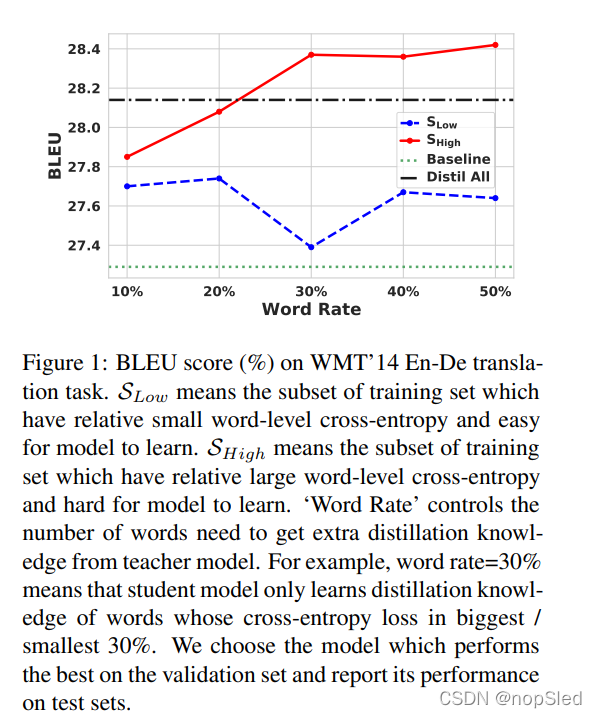
Impact of the Amount of Knowledge。鉴于蒸馏知识对Word CE最敏感,我们对Word CE进行了额外的分析。图1显示了改变
S
H
i
g
h
\mathcal S_{High}
SHigh和
S
L
o
w
\mathcal S_{Low}
SLow中的知识量的结果。一致的现象是,在使用相同数量的教师知识时,
S
H
i
g
h
\mathcal S_{High}
SHigh比
S
L
o
w
\mathcal S_{Low}
SLow更好。这些结果表明,我们应该更多的关注
S
H
i
g
h
\mathcal S_{High}
SHigh。此外,我们注意到在增加
S
H
i
g
h
\mathcal S_{High}
SHigh中的知识时,模型性能也会增加。我们得出结论,Word CE是可以用于区分知识,并且只有
S
H
i
g
h
\mathcal S_{High}
SHigh是能够迁移教师中更有用的知识。
在本节末尾,我们可以概述以下几点:
- 为了找出用于迁移知识的最合适的媒介,我们采用了一种新的分区和比较方法,可以轻松地用于未来的研究。
- 知识蒸馏多带来的性能提升会应知识媒介的不同而发生巨大变化。
- 在所有准则中,知识蒸馏对Word CE是最敏感的。使用具有较高Word CE的单词进行蒸馏比使用Word CE较低的单词更可靠。
- 在这些分区中, S L o w \mathcal S_{Low} SLow中的蒸馏知识无法直接与 S H i g h \mathcal S_{High} SHigh组合,甚至会伤害 S H i g h \mathcal S_{High} SHigh的性能。
5.Selective Knowledge Distillation for NMT

如上所述,蒸馏数据中存在会损害知识蒸馏性能的不适合的样本。在本节中,我们通过使用两个简单但有效的策略以选择样本,从而解决这个问题。
在第4节中,我们发现Word CE是最有区分性的准则。因此,我们继续使用Word CE作为我们方法的衡量标准。由于词交叉熵是直接衡量teacher模型与真实标签之间差距的方式,因此,将下面的内容中,我们将具有相对较大交叉熵的单词作为困难的单词,以及具有相对较小交叉熵的单词作为简单的单词。
然后,我们只需要定义哪些单词的交叉熵是“相对较大”的。在这里,我们介绍了两个基于CE的选择性策略:
Batch-level Selection (BLS)。给定由具有
M
M
M个目标单词的句子对组成的mini-batch
B
B
B,我们将当前批次中的所有单词按照他们的Word CE以降序排序,并选择所有单词中的前百分之
r
r
r来蒸馏teahcer知识。形式化地,令
A
\mathcal A
A表示Word CE的集合,其中包含batch B中的每个单词的Word CE。我们将
S
H
a
r
d
=
t
o
p
_
r
%
(
A
)
\mathcal S_{Hard}=top\_r\%(\mathcal A)
SHard=top_r%(A)定义为batch中的Word CE在前
r
%
r\%
r%单词的集合,而
S
E
a
s
y
\mathcal S_{Easy}
SEasy是它的剩余部分。
对于
S
H
a
r
d
\mathcal S_{Hard}
SHard中的这些单词,我们令他们从teacher模型的蒸馏信息获得额外的监督信号。因此,公式3中的知识蒸馏目标可以重新定义为:
L
k
d
=
{
−
∑
k
=
1
∣
V
∣
q
(
y
k
)
⋅
l
o
g
p
(
y
k
)
,
y
∈
S
H
a
r
d
0
,
y
∈
S
E
a
s
y
\mathcal L_{kd}=\begin{cases} -\sum^{|V|}_{k=1}q(y_k)\cdot log~p(y_k), & y\in \mathcal S_{Hard}\\ 0, & y\in \mathcal S_{Easy} \end{cases}
Lkd={−∑k=1∣V∣q(yk)⋅log p(yk),0,y∈SHardy∈SEasy
为了清楚起见,我们简化了
p
p
p和
q
q
q的表示。
Global-level Selection (GLS)。受mini-batch中单词数量的限制,Batch-level Selection只能反映当前batch中单词的CE分布,并且不能很好地代表模型的真实全局CE分布。此外,BLS使我们的相对难度测量容易受到每个局部batch组成的影响。获取全局CE分步的最佳方法是在模型每次更新后,遍历所有训练集中的单词并计算其CE。然而,这带来了强大的计算成本,并且在训练过程并不现实。
因此,作为最佳方式的代理,我们通过先进先出(FIFO)全局队列
Q
\mathcal Q
Q,来将Batch-level Selection扩展到Global-level Selection。在每个训练步骤中,我们将batch单词的CE推入
Q
\mathcal Q
Q并弹出队列中的“最旧”单词的CE以平衡队列的大小。然后,我们对队列中的所有CE值进行排序并计算每个单词的排名位置。由于队列的存储比mini-batch大得多,以便我们可以用更多的单词评估当前批次的CE,这会降低由BLS引起的CE分布的波动。算法1详细说明整个过程。

















 2336
2336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









