






摘要
有监督神经机器翻译(NMT)中的主要任务是学会从一组平行句子对中生成以源语言输入为条件的目标语言句子,从而产生能够泛化未知样例的模型。但是,通常观察到该模型的泛化性能与训练中使用的平行数据数量高度相关。尽管数据增强被广泛用于丰富训练数据,但是使用离散操作的常规方法无法生成多样化且语义不变的训练样本。在本文中,我们提出了一个新的数据增强框架,称为连续语义增强(Continuous Semantic Augmentation,SANMT),该框架通过使用能够覆盖丰富语言表达的相邻语义区域,来增强每一条训练样例。我们在涉及各种语言对的丰富资源和低资源两项配置上进行了广泛的实验,包括WMT14 English→{German,French},NIST Chinese→English和多个低资源IWSLT翻译任务。提供的经验证据表明,CSANMT与现有的增强技术相比,达到了新的性能水平,从而大幅度的改善了SOTA。
1.介绍
神经机器翻译(NMT)是自然语言处理中的核心主题之一,其旨在以源语言输入为条件,来生成目标语言中的单词序列。在常见的有监督环境中,训练目标是使用平行数据学习从源空间到目标空间的变换
X
↦
Y
:
f
(
y
∣
x
;
Θ
)
\mathcal X\mapsto \mathcal Y:f(\textbf y|\textbf x;\Theta)
X↦Y:f(y∣x;Θ)。通过这种方式,NMT模型有望在大规模训练数据的帮助下泛化未知样例,但是这对资源有限的场景构成了巨大的挑战。
为了解决这个问题,已经提出了各种方法来利用丰富的未标注数据以增强有限的标注数据。例如,反向翻译(BT)利用目标侧的单语言数据来合成大型伪平行数据,该数据与机器翻译任务中的真实平行语料库进一步合并。另一项研究是引入对抗性输入,以沿着小扰动方向来将提高NMT模型的泛化性。尽管这些方法导致了翻译质量的显着提升,但我们认为,在离散空间中增强观察到的训练数据本质上具有两个主要局限性。
首先,在离散空间中增强训练样例会缺乏多样性。我们仍然以BT为例,它通常使用集束搜索或贪心搜索来为每个目标单语句子生成源句子。以上两种搜索策略都是确定具有最大后验(MAP)的输出,因此在不确定情况下倾向于最频繁出现的句子。 Edunov et al. (2018) 提出了一种从输出分布的采样策略来减轻此问题,但是该方法通常会产生质量低的合成数据。尽管某些扩展可以通过多种语言形式增加每个训练样例,但它们仍然无法涵盖相同语义下的足够多变体。
其次,在离散空间中的增强文本很难保留其最初的语义。在自然语言处理的上下文中,诸如添加,丢弃,打乱顺序或替换原始句子中的单词之类的离散操作通常会导致语义发生重大变化。为了解决这个问题,Gao et al. (2019) 和Cheng et al. (2020) 是将单词替换为在相同上下文中使用语言模型预测的其他单词。尽管这种方法有效,但这些技术仅限于单词级的操作,并且无法执行整个句子转换,例如通过重新描述原始句子而产生另一句话,以使它们具有相同的含义。
在本文中,我们提出了Continuous Semantic Augmentation (CSANMT),这是NMT中新的数据增强框架,以减轻上述两方面的局限性。CSANMT的原理是从语义保留的连续空间中生成多样化的训练数据。具体而言:
(1)我们首先通过tangential contrast训练一个语义编码器,其鼓励每个训练样例在连续空间中提供一个邻接语义区域,并将该区域的切线视为语义等效的关键状态。这是由于最近的工作表明,连续空间中的矢量很容易涵盖具有相同含义的合适变体。
(2)然后,我们引入Mixed Gaussian Recurrent Chain (MGRC)算法,以采样来自邻接语义区域的向量簇。
(3)最终通过broadcasting integration network,以将每个采样的向量带入解码器,这时与模型架构无关的方法。因此,将离散句子转换到连续空间可以有效地增强训练数据空间,从而提高NMT模型的泛化能力。
我们在各种机器翻译任务上评估了该框架,包括WMT14 English-German/French,NIST Chinese-English和多个IWSLT任务。具体而言,CSANMT在WMT14 English-German任务中以30.94 BLEU得分在增强技术中达到了新的SOTA。此外,我们的方法可以使用仅25%的训练数据的基线模型来实现可比的性能。这表明CSANMT在低资源情况下具有巨大的潜力,可以实现良好的结果。
2.框架
Problem Definition。假设
X
\mathcal X
X和
Y
\mathcal Y
Y是两个数据空间,分别涵盖了源和目标语言中所有可能的单词序列。我们将
(
x
,
y
)
∈
(
X
,
Y
)
(\textbf x,\textbf y)∈(\mathcal X,\mathcal Y)
(x,y)∈(X,Y)表示为两个具有相同含义的句子,其中
x
=
{
x
1
,
x
2
,
.
.
.
,
x
T
}
\textbf x=\{x_1,x_2,...,x_T\}
x={x1,x2,...,xT}是带有
T
T
T个字符的源句子,
y
=
{
y
1
,
y
2
,
.
.
.
,
y
T
′
}
\textbf y=\{y_1,y_2,...,y_{T'}\}
y={y1,y2,...,yT′}是带有
T
′
T'
T′个字符的目标句子。一个sequence-to-sequence模型通常应用于神经机器翻译,该模型旨在使用平行数据学习从源空间到目标空间的变换
X
↦
Y
:
f
(
y
∣
x
;
Θ
)
\mathcal X\mapsto \mathcal Y:f(\textbf y|\textbf x;\Theta)
X↦Y:f(y∣x;Θ)。正式地,给定一组观察到的句子对
C
=
{
(
x
(
n
)
,
y
(
n
)
)
}
n
=
1
N
\mathcal C=\{(\textbf x^{(n)},\textbf y^{(n)})\}^N_{n=1}
C={(x(n),y(n))}n=1N,训练目标是最大化如下对数似然:
J
m
l
e
(
Θ
)
=
E
(
x
,
y
)
∼
C
(
l
o
g
P
(
y
∣
x
;
Θ
)
)
.
(1)
J_{mle}(\Theta)=\mathbb E_{(\textbf x,\textbf y)\sim \mathcal C}(log~P(\textbf y|\textbf x;\Theta)).\tag{1}
Jmle(Θ)=E(x,y)∼C(log P(y∣x;Θ)).(1)
其中,对数概率被分解为:
l
o
g
P
(
y
∣
x
;
Θ
)
=
∑
t
=
1
T
′
l
o
g
P
(
y
t
∣
y
<
t
,
x
;
Θ
)
log~P(\textbf y|\textbf x;\Theta)=\sum^{T'}_{t=1}log~P(y_t|\textbf y_{\lt t},\textbf x;\Theta)
log P(y∣x;Θ)=∑t=1T′log P(yt∣y<t,x;Θ),且
Θ
\Theta
Θ时可训练参数集。
但是,在神经机器翻译的常见有监督环境中存在一个主要问题,即训练样例的数量非常有限,因为获取平行数据的成本很高。 这使得很难学到一个很好地能够泛化未知数据的NMT模型。传统的数据增强方法通过在无标注数据上应用离散操作来生成更多的训练样本,例如反向翻译或用另一个单词随机替换一个单词,这通常会遇到语义偏差和缺乏多样性的问题。
2.1 Continuous Semantic Augmentation
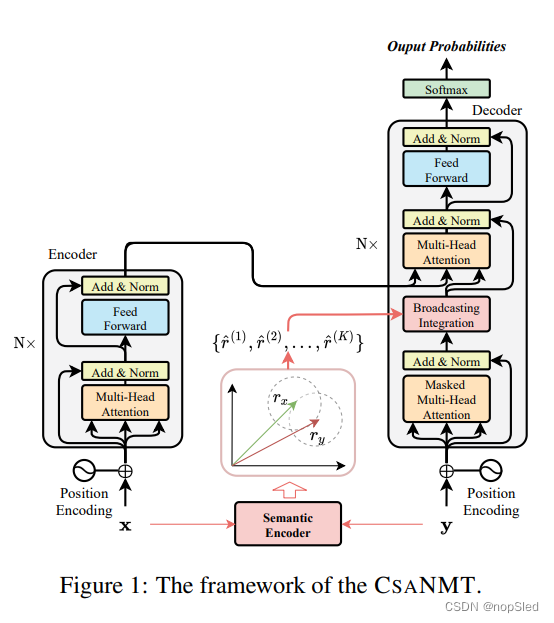
我们为神经机器翻译提出了一种新的数据增强框架,称为连续语义增强(CSANMT),以更好地泛化模型对未知样例的翻译能力。我们采用Transformer模型作为backbone,框架如图1所示。在此结构中,额外的语义编码器分别将源句
x
\textbf x
x和目标句
y
\textbf y
y转换为实值矢量
r
x
=
ψ
(
x
;
Θ
′
)
r_x=ψ(\textbf x;\Theta')
rx=ψ(x;Θ′)和
r
y
=
ψ
(
y
;
Θ
′
)
r_y=ψ(\textbf y;\Theta')
ry=ψ(y;Θ′),其中
ψ
(
⋅
;
Θ
′
)
ψ(·;\Theta')
ψ(⋅;Θ′)是由
Θ
′
\Theta'
Θ′参数化的语义编码器的forward函数。
Definition 1。神经机器翻译的源和目标语言之间有一个通用的语义空间,这是由语义编码器构建的。它将forward函数
ψ
(
⋅
;
Θ
′
)
ψ(·;\Theta')
ψ(⋅;Θ′)定义为离散句子到连续向量的映射,且满足:
∀
(
x
,
y
)
∈
(
X
,
Y
)
:
r
x
=
r
y
∀(\textbf x,\textbf y)∈(\mathcal X,\mathcal Y):r_x=r_y
∀(x,y)∈(X,Y):rx=ry。 此外,语义空间中的邻接语义区域
ν
(
r
x
,
r
y
)
ν(r_x,r_y)
ν(rx,ry)描述了以每个句子对
(
x
,
y
)
(\textbf x,\textbf y)
(x,y)为中心的足够多的字面表达变体。
在我们的场景下,我们首先从邻接语义区域采样一系列向量(由
R
\mathcal R
R表示),以增强当前训练样例,即
R
=
{
r
^
(
1
)
,
r
^
(
2
)
,
.
.
.
,
r
^
(
K
)
}
\mathcal R=\{\hat r^{(1)},\hat r^{(2)},...,\hat r^{(K)}\}
R={r^(1),r^(2),...,r^(K)},其中
r
^
(
k
)
〜
ν
(
r
x
,
r
y
)
\hat r^{(k)}〜ν(r_x,r_y)
r^(k)〜ν(rx,ry)。
K
K
K是确定采样向量数目的超参数。然后,通过broadcasting integration network将每个样本
r
^
(
k
)
\hat r^{(k)}
r^(k)集成到生成过程中:
o
^
t
=
W
1
r
^
(
k
)
+
W
2
o
t
+
b
,
(2)
\hat o_t=W_1\hat r^{(k)}+W_2o_t+b,\tag{2}
o^t=W1r^(k)+W2ot+b,(2)
其中
o
t
o_t
ot是self-attention模块在位置
t
t
t的输出。最终,等式(1)中的训练目标能被改进为:
J
m
l
e
(
Θ
)
=
E
(
x
,
y
)
∼
C
,
r
^
(
k
)
∈
R
(
l
o
g
P
(
y
∣
x
,
r
^
(
k
)
,
Θ
)
)
.
(3)
J_{mle}(\Theta)=\mathbb E_{(\textbf x,\textbf y)\sim \mathcal C,\hat r^{(k)}\in \mathcal R}(log~P(\textbf y|\textbf x,\hat r^{(k)},\Theta)).\tag{3}
Jmle(Θ)=E(x,y)∼C,r^(k)∈R(log P(y∣x,r^(k),Θ)).(3)
通过使用来自邻接语义区域的多样化样本来增强训练样例
(
x
,
y
)
(\textbf x,\textbf y)
(x,y),该模型被期望能够泛化更多的未知样例。为此,我们必须考虑这两个问题:(1)如何优化语义编码器,以便为每个训练对都能产生一个有意义的邻接语义区域。(2)如何以有效且高效的方式从邻接语义区域获取样本。在本节的其余部分中,我们分别介绍了这两个问题的解决方案。
2.1.1 Tangential Contrastive Learning
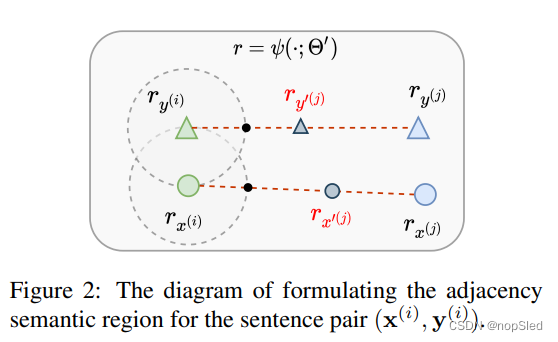
我们从分析邻接语义区域的几何解释开始,示意图如图2所示。令
(
x
(
i
)
,
y
(
i
)
)
(\textbf x^{(i)},\textbf y^{(i)})
(x(i),y(i))和
(
x
(
j
)
,
y
(
j
)
)
(\textbf x^{(j)},\textbf y^{(j)})
(x(j),y(j))是从训练语料库中随机采样的两个样例。对于
(
x
(
i
)
,
y
(
i
)
)
(\textbf x^{(i)},\textbf y^{(i)})
(x(i),y(i)),邻接语义区域
ν
(
r
x
(
i
)
,
r
y
(
i
)
)
ν(r_{x^{(i)}},r_{y^{(i)}})
ν(rx(i),ry(i))被定义为分别以
r
x
(
i
)
r_{x^{(i)}}
rx(i)和
r
y
(
i
)
r_{y^{(i)}}
ry(i)为中心的两个闭合球的并集。两个球的半径均为
d
=
∣
∣
r
x
(
i
)
−
r
y
(
i
)
∣
∣
2
d=||r_{x^{(i)}}-r_{y^{(i)}}||_2
d=∣∣rx(i)−ry(i)∣∣2,它也被看作是确定语义等效性的松弛变量。基本的解释是,与
r
x
(
i
)
r_{x^{(i)}}
rx(i)(或
r
y
(
i
)
r_{y^{(i)}}
ry(i))距离不超过
d
d
d的向量在语义上与
r
x
(
i
)
r_{x^{(i)}}
rx(i)(或
r
y
(
i
)
r_{y^{(i)}}
ry(i))是等效的。为了使
ν
(
r
x
(
i
)
,
r
y
(
i
)
)
ν(r_{x^{(i)}},r_{y^{(i)}})
ν(rx(i),ry(i))符合解释,我们采用了与 (Zheng et al., 2019; Wei et al., 2021) 中类似的方法,使用 tangential contrast 来优化语义编码器 。
具体而言,我们通过在同一训练batch中应用当前样例与其他样例之间的凸插值来构建负样本。切线点(即边界上的点)被视为语义相等的临界状态。训练目标被定义为:
J
c
t
l
(
Θ
′
)
=
E
(
x
(
i
)
,
y
(
i
)
)
∼
B
(
l
o
g
e
s
(
r
x
(
i
)
,
r
y
(
i
)
)
e
s
(
r
x
(
i
)
,
r
y
(
i
)
)
+
ξ
)
,
ξ
=
∑
j
&
j
≠
i
∣
B
∣
(
e
s
(
r
y
(
i
)
,
r
y
′
(
j
)
)
+
e
s
(
r
x
(
i
)
,
r
x
′
(
j
)
)
)
,
(4)
J_{ctl}(\Theta')=\mathbb E_{(\textbf x^{(i)},\textbf y^{(i)})\sim \mathcal B}\bigg(log\frac{e^{s(r_{x^{(i)}},r_{y^{(i)}})}}{e^{s(r_{x^{(i)}},r_{y^{(i)}})}+\xi}\bigg),\\ \xi=\sum^{|B|}_{j\&j\ne i}(e^{s(r_{y^{(i)}},r_{y^{'(j)}})}+e^{s(r_{x^{(i)}},r_{x^{'(j)}})}),\tag{4}
Jctl(Θ′)=E(x(i),y(i))∼B(loges(rx(i),ry(i))+ξes(rx(i),ry(i))),ξ=j&j=i∑∣B∣(es(ry(i),ry′(j))+es(rx(i),rx′(j))),(4)
其中
B
\mathcal B
B表示从训练语料
C
\mathcal C
C随机选择的句子对batch,而
s
(
⋅
)
s(·)
s(⋅)是计算两个向量之间余弦相似性的得分函数。负样本
r
x
′
(
j
)
r_{x^{'(j)}}
rx′(j)和
r
y
′
(
j
)
r_{y^{'(j)}}
ry′(j)被设计为以下插值:
r
x
′
(
j
)
=
r
x
(
i
)
+
λ
x
(
r
x
(
j
)
−
r
x
(
i
)
)
,
λ
x
∈
(
d
d
x
′
,
1
]
,
r
y
′
(
j
)
=
r
y
(
i
)
+
λ
y
(
r
y
(
j
)
−
r
y
(
i
)
)
,
λ
y
∈
(
d
d
y
′
,
1
]
,
(5)
r_{x^{'(j)}}=r_{x^{(i)}}+\lambda_x(r_{x^{(j)}}-r_{x^{(i)}}),\lambda_x\in (\frac{d}{d'_x},1],\\ r_{y^{'(j)}}=r_{y^{(i)}}+\lambda_y(r_{y^{(j)}}-r_{y^{(i)}}),\lambda_y\in (\frac{d}{d'_y},1],\tag{5}
rx′(j)=rx(i)+λx(rx(j)−rx(i)),λx∈(dx′d,1],ry′(j)=ry(i)+λy(ry(j)−ry(i)),λy∈(dy′d,1],(5)
其中
d
x
′
=
∣
∣
r
x
(
i
)
−
r
x
(
j
)
∣
∣
2
d'_x=||r_{x^{(i)}}-r_{x^{(j)}}||_2
dx′=∣∣rx(i)−rx(j)∣∣2和
d
y
′
=
∣
∣
r
y
(
i
)
−
r
y
(
j
)
∣
∣
2
d'_y=||r_{y^{(i)}}-r_{y^{(j)}}||_2
dy′=∣∣ry(i)−ry(j)∣∣2。当
d
x
′
d'_x
dx′和
d
y
′
d'_y
dy′分别大于
d
d
d时,就使用等式(5)中的两个方程式进行计算,否则令
r
x
′
(
J
)
=
r
x
(
J
)
r_{x^{'(J)}}=r_{x^{(J)}}
rx′(J)=rx(J)和
r
y
′
(
J
)
=
r
y
(
J
)
r_{y^{'(J)}}=r_{y^{(J)}}
ry′(J)=ry(J)。基于此设计,可以通过在同一训练batch中插入各种实例来完全确定第
l
l
l个训练实例的邻接语义区域。我们采用与Wei et al. (2021) 相同的方法,在训练过程中自适应调整
λ
x
λ_x
λx(或
λ
y
λ_y
λy)的值,请参考原始论文以获取详细信息。
2.1.2 MGRC Sampling
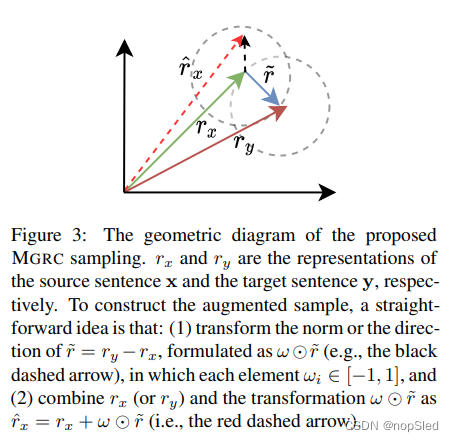
为了从训练样例
(
x
,
y
)
(\textbf x,\textbf y)
(x,y)的邻接语义区域中获得增强数据,我们引入了Mixed Gaussian Recurrent Chain(MGRC)算法,以设计高效的采样策略。如图3所示,我们首先根据预定义的缩放向量
ω
ω
ω来对偏差向量
r
~
=
r
y
−
r
x
\tilde r=r_y-r_x
r~=ry−rx进行变换,即
ω
⊙
r
~
ω\odot \tilde r
ω⊙r~,其中
⊙
\odot
⊙表示逐元素乘操作。然后,我们构建了一个新的样本
r
^
=
r
+
ω
⊙
r
~
\hat r=r+ω\odot \tilde r
r^=r+ω⊙r~,以用于增强当前样例,其中
r
r
r为
r
x
r_x
rx或
r
y
r_y
ry。因此,采样策略的目标变成找到一组缩放向量,即
ω
∈
{
ω
(
1
)
,
ω
(
2
)
,
.
.
.
,
ω
(
k
)
}
ω∈\{ω^{(1)},ω^{(2)},...,ω^{(k)}\}
ω∈{ω(1),ω(2),...,ω(k)}。直观上,我们可以假设
ω
ω
ω遵循具有均匀或高斯形式的分布,尽管后者在我们的经验中表现出更好的结果。正式地,我们设计了混合高斯分布,如下所示:
ω
(
k
)
∼
p
(
ω
∣
ω
(
1
)
,
ω
(
2
)
,
.
.
.
,
ω
(
k
−
1
)
)
,
p
=
η
N
(
0
,
d
i
a
g
(
W
r
2
)
)
+
(
1.0
−
η
)
N
(
1
k
−
1
∑
i
=
1
k
−
1
ω
(
i
)
,
1
)
.
(6)
ω^{(k)}\sim p(ω|ω^{(1)},ω^{(2)},...,ω^{(k-1)}),\\ p=\eta \mathcal N(\textbf 0,diag(\mathcal W^2_r))+(1.0-\eta)\mathcal N(\frac{1}{k-1}\sum^{k-1}_{i=1}ω^{(i)},\textbf 1).\tag{6}
ω(k)∼p(ω∣ω(1),ω(2),...,ω(k−1)),p=ηN(0,diag(Wr2))+(1.0−η)N(k−11i=1∑k−1ω(i),1).(6)
该框架对循环链和拒绝采样机制进行了统一。具体而言,我们首先将
r
~
\tilde r
r~中每个维度的重要性归一化为
W
r
=
∣
r
~
∣
−
m
i
n
(
∣
r
~
∣
)
m
a
x
(
∣
r
~
∣
)
−
m
i
n
(
∣
r
~
∣
)
\mathcal W_r=\frac{|\tilde r|-min(|\tilde r|)}{max(|\tilde r|)-min(|\tilde r|)}
Wr=max(∣r~∣)−min(∣r~∣)∣r~∣−min(∣r~∣),
∣
⋅
∣
|·|
∣⋅∣操作计算向量中每个元素的绝对值,这意味着元素的值越大,其信息越多。因此,
N
(
0
,
d
i
a
g
(
W
r
2
)
)
\mathcal N(\textbf 0,diag(\mathcal W^2_r))
N(0,diag(Wr2))将采样范围限制为邻接语义区域这一子空间,并且拒绝从信息量少的维度进行采样。此外,
N
(
1
k
−
1
∑
i
=
1
k
−
1
ω
(
i
)
,
1
)
\mathcal N(\frac{1}{k-1}\sum^{k-1}_{i=1}ω^{(i)},\textbf 1)
N(k−11∑i=1k−1ω(i),1)模拟了一个循环链,该链会生成一系列合理向量的序列,其中当前一个依赖于先前的矢量。该设计的原因是,我们期望等式(6)中的
p
p
p可以随着样本数量的增加而成为一个固定分布,这描述了每个训练样例的多样性不是无限的事实。
η
η
η是一个超参数,平衡了上述两种高斯形式的重要性。算法1总结了整个采样过程。

2.2 Training and Inference
我们方法中的训练目标是等式(3)中
J
m
l
e
(
Θ
)
J_{mle}(\Theta)
Jmle(Θ)和等式(4)中
J
c
t
l
(
Θ
′
)
J_{ctl}(\Theta')
Jctl(Θ′)的组合。实际上,我们引入了一个两阶段的训练过程。首先,我们使用特定于任务的数据从头开始训练语义编码器,即
Θ
′
∗
=
a
r
g
m
a
x
Θ
′
J
c
t
l
(
Θ
′
)
\Theta'^*=argmax_{\Theta'}J_{ctl}(\Theta')
Θ′∗=argmaxΘ′Jctl(Θ′)。其次,我们通过最大化对数似然来优化编码器-解码器模型(即
Θ
∗
=
a
r
g
m
a
x
Θ
J
m
l
e
(
Θ
)
\Theta^*=argmax_{\Theta}J_{mle}(\Theta)
Θ∗=argmaxΘJmle(Θ)),并同时以较小的学习率微调语义编码器。
在推理期间,目标单词序列是自回归产生的,该结构与vanilla Transformer几乎相同。一个主要区别在于,我们的方法涉及输入序列的语义向量:
y
t
∗
=
a
r
g
m
a
x
y
t
P
(
⋅
∣
y
<
t
,
x
,
r
x
;
Θ
)
y^∗_t =argmax_{y_t}P(·|\textbf y_{<t},\textbf x,r_x;\Theta)
yt∗=argmaxytP(⋅∣y<t,x,rx;Θ),其中
r
x
=
ψ
(
x
;
Θ
′
)
r_x=ψ(\textbf x;\Theta')
rx=ψ(x;Θ′)。 该模块是模型无关,即插即用的。

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









