







摘要
在本文中,我们建立了一个自动诊断的对话系统。我们首先通过从在线医学论坛的患者自我描述以及患者和医生之间的对话数据中提取症状来收集数据集。然后,我们提出了一个面向任务的对话系统框架,以自动为患者进行诊断,并且可以和患者交谈来收集不在已有报告中的其他症状。在我们数据集中的实验结果表明,从对话中提取的其他症状可以极大地提高疾病识别的准确性,我们的对话系统能够自动收集这些症状并做出更好的诊断。
1.介绍
近年来,使用电子病例(EHR)来进行自动表格识别一直是热门的话题。研究人员探索了各种机器学习方法,以识别有多种类型信息(数值数据和纯文本)的患者的症状和疾病。实验结果证明了在检测心力衰竭,2型糖尿病,自闭症谱系障碍,感染检测等的有效性。当前,大多数尝试都集中在某些特定类型的疾病上,并且很难将模型从一种疾病转移到另一种疾病。
最近,由于其巨大潜力和商业价值,有关面向任务的对话系统(DS)的研究引起了不同领域的越来越多的关注,包括票务预订,在线购物和餐厅搜索。我们认为,在医疗领域中应用DS具有降低从患者收集数据成本的巨大潜力。
但是,在疾病识别中应用DS和其他领域存在差距。基本上有两个主要挑战:首先,缺乏有标签的医学对话数据集。其次,没有用于疾病识别的DS框架。通过解决这两个问题,我们采首先建立了一个对话系统,以促进信息自动收集和医疗领域的诊断。本论文的贡献有两个方面:
- 我们对由两部分组成的医疗数据集进行了标注,一个是患者的自我描述,另一个是患者和医生之间的对话数据。
- 我们为医疗DS提出了一个基于强化学习的框架。我们数据集中的实验结果表明,我们的对话系统能够通过对话从患者那里收集症状,并提高自动诊断的准确性。
2.Dataset for Medical DS

我们的数据集是从中国在线医疗社区(百度健康)的儿科部门收集的。它是一个流行的网站,能提供用户在线查询医生。通常,患者会提供一份自我描述,以介绍其基本条件。然后,医生将初始化对话以收集更多信息,并根据自我描述和对话数据进行诊断。表1中显示了一个示例。正如我们所看到的,医生可以在自我描述之外的对话中获得其他症状。对于每个患者,我们还可以将医生的最终诊断作为标签。为了清楚起见,我们将自我描述中的症状称为显式症状,而来自会话数据的症状是隐式症状。
我们选择四种类型的疾病进行标注,包括上呼吸道感染,儿童功能性消化不良,婴儿腹泻和儿童支气管炎。我们邀请三位标注人员(具有医学背景)来标注自我描述和对话数据中的所有症状短语。标注过程分为两个步骤,即症状提取和症状规整。

Symptom Extraction。我们采用BIO((begin-in-out)方案进行症状识别(图1)。每个中文字符都被分配给“B”,“I”或“O”的标签。同样,每个提取的症状表达都用True或False标记,表明患者是否患有这种症状。为了提高标注人员之间的标注一致性,我们分别为自我描述和对话数据创建两个准则。每份数据至少有两个标注者标注。第三个标注者将进一步判断不一致的地方。两个标注者之间的Cohen’s kappa系数分别为自我描述71%和对话67%。

Symptom Normalization。在症状表达被识别出来后,医学专家将每个症状表达与SNOMED CT上的最相关概念联系起来,以进行标准化。表2显示了一些描述示例中症状的短语以及Snomed CT中的一些相关概念。表3列出了数据集的概述。
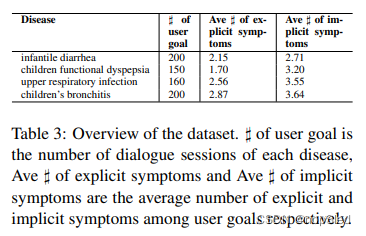
在进行症状提取和规整后,发现了144个独特的症状。为了减少DS的动作空间,仅保留了出现频率大于或等于10的67个症状。然后生成样本,称为用户目标(user goal)。 如我们所知,每个用户目标(见图2)均来自一个现实世界的患者病例。
3.Proposed Framework

面向任务的DS通常包含三个组件,即自然语言理解(NLU),对话管理(DM)和自然语言生成(NLG)。NLU检测到用户的意图以及来自对话语句的槽值对;DM跟踪对话并采取相应的系统动作;给定系统动作,NLG生成对应的自然语言。在这项工作中,我们专注于自动诊断的DM,其包括两个子模块,即对话状态跟踪(DST)和策略学习。NLU和NLG均使用基于模板的模型实现。通常,用户模拟器旨在与对话系统进行交互。我们采用与Li et al. (2017) 相同的设置,来设计我们的医疗DS。在对话开始时,用户模拟器采样了用户目标(请参见图2),而agent则试图为用户诊断。 该系统将通过最大化期望累积奖赏来学习每个时间步骤中选择的最佳响应动作。
3.1 User Simulator
在每个对话的开始,用户模拟器从实验数据集中采样一个用户目标。在每个对话轮次
t
t
t上,用户基于当前的用户状态
s
u
,
t
+
1
s_{u,t+1}
su,t+1来采取动作
a
u
,
t
a_{u,t}
au,t,并基于上一个agent动作
a
t
−
1
a_{t-1}
at−1来转移到下一个用户状态
s
u
,
t
+
1
s_{u,t+1}
su,t+1。实际上,用户状态
s
u
s_u
su被分解为一个议程
A
A
A和一个目标
G
G
G,写为
s
u
=
(
A
,
G
)
s_u=(A,G)
su=(A,G)。在对话过程中,目标
G
G
G用以确保用户行为的一致性。议程
A
A
A包含一个症状及其状态(是否需要进行请求)列表来跟踪对话的进度。
每个对话议程
A
A
A均通过用户动作
a
u
,
1
a_{u,1}
au,1初始化,其中由请求疾病的槽和所有显示症状组成。对于需要在对话过程中由agent请求的症状,用户将会选择三个动作之一进行响应,即
T
r
u
e
True
True(如果对应隐式症状字段为true),
F
a
l
s
e
False
False(如果对应隐式症状字段为false),
n
o
t
_
s
u
r
e
not\_sure
not_sure(如果没有对应的隐式症状字段)。如果agent通知了正确的疾病,那么对话过程将被用户作为成功状态终止,当agent给定一个错误的疾病或者超过最大对话轮次
T
T
T,那么对话过程将被用户作为失败状态终止。
3.2 Dialogue Policy Learning
3.2.1 Markov Decision Process Formulation for Automatic Diagnosis
我们将DS作为马尔可夫决策过程(MDP),并通过强化学习训练对话策略。MDP由状态,动作,奖赏,策略和转移组成。
State
S
S
S。对话状态
s
s
s包含到时刻
t
t
t为止由用户通知的症状,agent请求的症状,用户的上一个动作,agent的上一个动作和轮次信息。对于表示症状的向量,其维度大小等于所有症状的数量,其包含的症状为1,不包含的症状为-1,不确定的症状为-2,未提及的症状为0。 每一个状态
s
∈
S
s∈S
s∈S是这四个向量的拼接。
Actions
A
A
A。动作
a
∈
A
a∈A
a∈A由对话动作(例如,
i
n
f
o
r
m
inform
inform,
r
e
q
u
e
s
t
request
request,
d
e
n
y
deny
deny和
c
o
n
f
i
r
m
confirm
confirm)和槽(即归整的症状或特殊的槽疾病)组成。此外,
t
h
a
n
k
s
thanks
thanks和
c
l
o
s
e
_
d
i
a
l
o
g
u
e
close\_dialogue
close_dialogue也是两个动作。
Transition
T
T
T。从状态
s
t
s_t
st到
s
t
+
1
s_{t+1}
st+1的转移是基于agent动作
a
t
a_t
at,上一个用户动作
a
u
,
t
−
1
a_{u,t-1}
au,t−1和对话轮次
t
t
t。
Reward
R
R
R。奖励
r
t
+
1
=
R
(
s
t
,
a
t
)
r_{t+1}=R(s_t,a_t)
rt+1=R(st,at)是采用动作
a
t
a_t
at后的直接奖励,也称为reinforcement。
Policy
π
π
π。策略描述了agent的行为,该行为将状态
s
t
s_t
st视为输入,并在所有可能的动作
π
(
a
t
∣
s
t
)
π(a_t|s_t)
π(at∣st)上输出概率分布。
3.2.2 Learning with DQN
在本文中,策略是用深度Q网络(DQN)进行参数化的,该策略以状态
s
t
s_t
st作为输入,并输出所有动作
a
a
a上的
Q
(
s
t
,
a
;
θ
)
Q(s_t,a;θ)
Q(st,a;θ)。Q网络可以通过在第
i
i
i次迭代时减少基于当前网络
Q
(
s
,
a
∣
θ
i
)
Q(s,a|\theta_i)
Q(s,a∣θi)计算的
Q
Q
Q值和基于贝尔曼方程
y
i
=
r
+
γ
m
a
x
a
′
Q
(
s
′
,
a
′
∣
θ
i
−
)
y_i=r+\gamma~max_{a'}Q(s',a'|\theta^-_i)
yi=r+γ maxa′Q(s′,a′∣θi−)计算的
Q
Q
Q值之间的均方误差来进行更新,其中
Q
(
s
′
,
a
′
∣
θ
i
−
)
Q(s',a'|\theta^-_i)
Q(s′,a′∣θi−)有具有参数
θ
i
−
\theta^-_i
θi−的目标网络得到。实际上,动作采样通常通过
ϵ
\epsilon
ϵ贪心算法来实现,即以
1
−
ϵ
1-\epsilon
1−ϵ概率按
a
=
a
r
g
m
a
x
a
′
Q
(
s
t
,
a
′
;
θ
)
a=argmax_{a'}Q(s_t,a';\theta)
a=argmaxa′Q(st,a′;θ)进行采样,以
ϵ
\epsilon
ϵ概率进行随机采样,该方法能提升探索率。当训练网络时,我们使用一种称为“经验回放”的技术。我们将agent的在每个时间段的历史数据存储在队列
D
D
D中,其中每个元素表示为
e
t
=
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
e_t=(s_t,a_t,r_t,s_{t+1})
et=(st,at,rt,st+1)。
在仿真期间,当前DQN网络被多次更新(取决于batch大小和经验回放缓冲区大小),而目标DQN网络在当前DQN网络更新期间固定。在每次仿真期结束,目标网络被当前网络替换,并在训练集上评估当前网络。如果当前网络的性能优于所有以前的版本,则缓冲区将被清洗。

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









