







 本文探讨了构建task-oriented对话系统面临的挑战,包括数据稀缺问题。研究对比了强化学习和seq2seq模型的方法,并提出了一种结合两者的策略。论文介绍了一个利用LSTM和CNN的框架,通过整合业务信息和历史对话,降低对训练数据的依赖,减少了模板设计的复杂性。
本文探讨了构建task-oriented对话系统面临的挑战,包括数据稀缺问题。研究对比了强化学习和seq2seq模型的方法,并提出了一种结合两者的策略。论文介绍了一个利用LSTM和CNN的框架,通过整合业务信息和历史对话,降低对训练数据的依赖,减少了模板设计的复杂性。
关键词
end2end, task-oriented dialogue system
来源
arXiv 2016.04.15
问题
当前构建一个诸如宾馆预订或技术支持服务的 task-oriented 的对话系统很难,主要是因为难以获取训练数据。现有两种方式解决问题:
- 将这个问题看做是 partially observable Markov Decision Process (POMDP),利用强化学习在线与真实用户交互。但是语言理解和语言生成模块仍然需要语料去训练。而且为了让 RL 能运作起来,state 和 action space 必须小心设计,这就限制了模型的表达能力。同时 rewad function 很难设计,运行时也难以衡量
- 利用 seq2seq 来做,这又需要大量语料训练。同时,这类模型无法做到与数据库交互以及整合其他有用的信息,从而生成实用的相应。
本文提出了平衡两种方法的策略。
文章思路
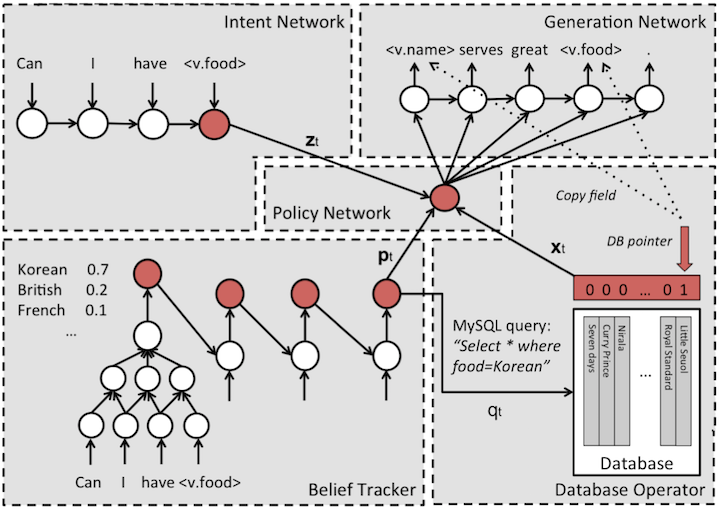
-
模型分为五个模块 Intent Network
- 这个部分可以看做为seq2seq的encoder部分,将用户的输入encode 成一个向量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









