




摘要
语言模型越来越多地被用于在各种任务中解决通用问题,但仍局限于在推理期间以token级进行从左到右的决策。这意味着他们无法处理需要进行探索,回溯或者在初始决策时就扮演重要角色的任务。为了克服这些挑战,我们引入了一种语言模型推理框架,“Tree of Thoughts” (ToT),该框架将流行的思维链(CoT)方法泛化到提示语言模型,并可以对文本的连贯单元进行探索,以作为解决问题的中间步骤。ToT允许LM通过考虑多个不同的推理路径和自我评估选择来决定下一步的行动方案,并在必要时进行前向或回溯以做出全局选择,从而执行决策。我们的实验表明,ToT可以显着增强语言模型在需要复杂计划或搜索的三个新任务上解决问题的能力:24点游戏,创意写作和迷你填字游戏。例如,在24点游戏中,带有思维链的GPT-4仅解决了4%的任务,但我们的方法达到了74%的成功率。我们的代码开源地址如下:https://github.com/ysymyth/tree-of-thought-llm。
1.介绍
最初设计用于生成文本的语言模型(LMS)(例如GPT和PaLM)的扩展版本已被越来越多地证明能够执行需要数学,符号,常识性和知识推理各种广泛任务。令人惊讶的是,所有这些进步仍然是以原始自回归机制来生成文本,这是以token级的决策以从左到右的方式进行。如此简单的机制就足以使LM构建一个通用问题求解器吗?如果不是,哪些问题会对当前的范式产生挑战,并且应该有哪些替代机制?
与人类认知相关的文献为回答这些问题提供了一些线索。对“双重过程”模型的研究表明,人类有两种模式可以参与决策:一种快速,自动,无意识的模式(“System 1”)和一种缓慢,思考,有意识的模式(“System 2”)。这两种模式以前已被连接到机器学习中使用的各种数学模型。例如,对人类和其他动物的强化学习的研究探索了模型无关学习或者基于模型计划的情况。LM这种简单的token级选择也让人联想到“System 1”,因此可能会从通过思考的“System 2”计划过程的增强中受益,该过程(1)维持和探索了当前情况的多种选择,而不仅仅是选择一个,(2)评估其当前状态,并主动地前向或回溯以做出更多的全局决策。
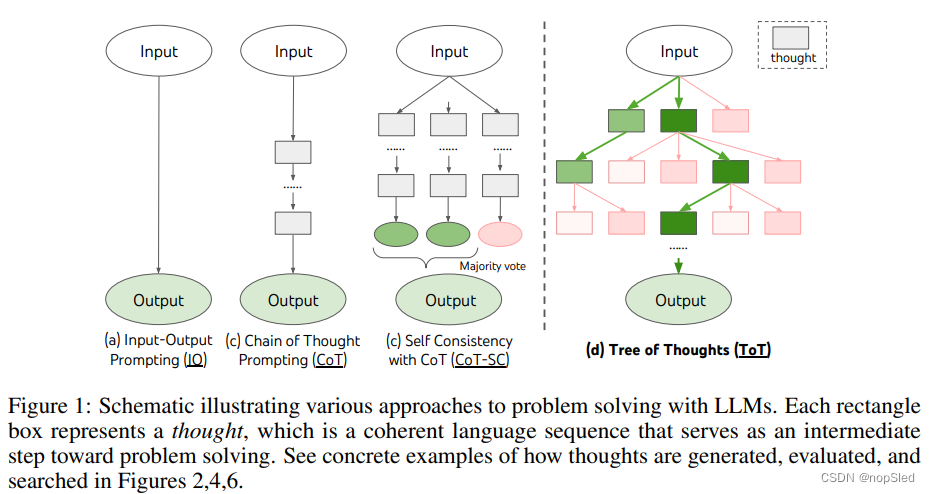
为了设计这样的计划过程,我们回顾了人工智能(和认知科学)的起源,并且受1950年Newell, Shaw和Simon探索的计划过程的启发。Newell及其同事将问题求解表示为在由树建模的组合问题空间上搜索。因此,我们针对使用语言模型解决一般问题提出了思维树(ToT)框架。如图1所示,现有方法(下面详细介绍)采样连续语言序列解决问题,而ToT会主动维护一棵思维树,其中每个思维都是一个连贯的语言序列,是作为解决问题的中间步骤(表1)。 这样的高级语义单元使LM能够通过使用语言来实例化推理过程,并对不同的中间思维进行自我评估,来进行问题求解(图2,4,6)。这种通过LM自我评估和思考,来实现启发式搜索的方法是比较新颖的,因为先前的启发式搜索方法是程序化的或学习的。最后,我们结合了这种基于语言的能力,使用搜索算法(例如广度优先搜索BFS或深度优先搜索DFS)来生成和评估各种思维,从而可以系统性地探索使用前向和回溯。
从经验上讲,我们提出了使用现有SOTA语言模型GPT-4也难以解决的三个任务:24点游戏,创意写作和填字游戏(表1)。 这些任务需要演绎、数学、常识和词汇推理能力,以及一种结合系统进行计划或搜索的方法。我们表明,ToT通过足够通用和灵活地支持不同级别的思考,不同的生成和评估思想的方式以及适应不同问题本质的搜索算法,从而在这三个任务中获得了最优结果。我们还消融分析了这种选择如何通过系统影响模型性能,并讨论了未来训练和使用LM的方向。

2.Background
我们首先将一些使用大语言模型进行问题求解的现有方法进行形式化,我们的方法受这些方法的启发,并且后面将会与这些方法做比较。我们使用
p
θ
p_θ
pθ表示具有参数
θ
θ
θ的预训练的LM,小写字母
x
,
y
,
z
,
s
,
.
.
.
x,y,z,s,...
x,y,z,s,...表示一个语言序列,即
x
=
(
x
[
1
]
,
.
.
.
,
x
[
n
]
)
x=(x[1],...,x[n])
x=(x[1],...,x[n]),其中每个
x
[
i
]
x[i]
x[i]是一个token,因此
p
θ
(
x
)
=
∏
i
=
1
n
p
θ
(
x
[
i
]
∣
x
[
1...
i
]
)
p_θ(x)=\prod^n_{i=1}p_θ(x[i]|x[1...i])
pθ(x)=∏i=1npθ(x[i]∣x[1...i])。我们使用大写字母
S
,
.
.
.
S,...
S,...表示语言序列的集合。
Input-output (IO) prompting。输入输出提示是使用LM:
y
∼
p
θ
(
y
∣
p
r
o
m
p
t
I
O
(
x
)
)
y\sim p_{\theta}(y|prompt_{IO}(x))
y∼pθ(y∣promptIO(x))将问题输入
x
x
x转成输出
y
y
y的最常见方法,其中
p
r
o
m
p
t
I
O
(
x
)
prompt_{IO}(x)
promptIO(x)通过用任务指令和/或few-shot输入输出样例对
x
x
x进行封装。为简单起见,我们将其表示为
p
θ
p
r
o
m
p
t
(
o
u
t
p
u
t
∣
i
n
p
u
t
)
=
p
θ
(
o
u
t
p
u
t
∣
p
r
o
m
p
t
(
i
n
p
u
t
)
)
p^{prompt}_{\theta}(output|input)=p_{\theta}(output|prompt(input))
pθprompt(output∣input)=pθ(output∣prompt(input)),以便可以将IO提示形式化为
y
〜
p
θ
I
O
(
y
∣
x
)
y〜p^{IO}_θ(y|x)
y〜pθIO(y∣x)。
Chain-of-thought (CoT) prompting。思维链(CoT)提示被提出以解决当将输入
x
x
x映射到输出
y
y
y时很困难的情况(例如,
x
x
x是一个数学问题,而
y
y
y是最终的数值答案)。其关键思想是引入一个思维链
z
1
,
⋅
⋅
⋅
,
z
n
z_1,···,z_n
z1,⋅⋅⋅,zn以桥接
x
x
x和
y
y
y,每个
z
i
z_i
zi都是一个连贯的语言序列,其对问题求解是一个有意义的中间步骤(例如
z
i
z_i
zi可以看作是数学问答的中间表达式)。为了使用CoT解决问题,每一步思考
z
i
〜
p
θ
C
o
T
(
z
i
∣
x
,
z
1...
i
−
1
)
z_i〜p^{CoT}_θ(z_i|x,z_{1...i-1})
zi〜pθCoT(zi∣x,z1...i−1)被顺序采样,然后输出
y
〜
p
θ
C
o
T
(
y
∣
x
,
z
1
⋅
⋅
⋅
n
)
y〜p^{CoT}_θ(y|x,z_{1···n})
y〜pθCoT(y∣x,z1⋅⋅⋅n)。在实际使用中,
[
z
1
⋅
⋅
n
,
y
]
〜
p
θ
C
o
T
(
z
1
⋅
⋅
⋅
n
,
y
∣
x
)
[z_{1··n},y]〜p^{CoT}_θ(z_{1···n},y|x)
[z1⋅⋅n,y]〜pθCoT(z1⋅⋅⋅n,y∣x)被作为为连续语言序列采样,并且思想的分解是不清晰的(例如,每个
z
i
z_i
zi可以是一个短语,句子,或段落)。
Self-consistency with CoT (CoT-SC)。CoT-SC是一种集成方法,其采样出
k
k
k个独立同分布的思维链
[
z
1...
n
(
i
)
,
y
(
i
)
]
∼
p
θ
C
o
T
(
z
1...
n
,
y
∣
x
)
[z^{(i)}_{1...n},y^{(i)}]\sim p^{CoT}_{\theta}(z_{1...n},y|x)
[z1...n(i),y(i)]∼pθCoT(z1...n,y∣x),然后返回答案出现频次最高的输出:
y
#
i
∣
y
(
i
)
=
y
y#{i|y^{(i)}=y}
y#i∣y(i)=y。CoT-SC在CoT上有所改善,因为相同问题通常存在不同的思维过程(例如,证明相同定理有不同的方法),并且通过探索一组更丰富的思想,输出决策可以更加忠实。但是,在每个思维链中,没有局部探索不同的思考步骤,并且“答案出现频次最高”这一方式,仅在输出空间受到限制时适用(例如,多选QA)。
3.Tree of Thoughts: Deliberate Problem Solving with LM

对人类如何解决问题的研究表明,人们通过一个组合问题空间进行搜索,这是一棵树,其中节点表示部分解决方案,分支对应于修改它们的操作符。要采用的分支由启发式方法确定,以帮助在问题空间中搜索并引导问题求解器朝正确解决方案前进。这种观点突出了使用现有LM方法解决一般问题的两个关键缺点:1)局部上,他们不会在一个思考过程中探索不同的连续性,即树的不同分支。 2)全局上,它们不包含任何类型的计划,前向或回溯来帮助评估这些不同的选择。而这种启发式引导搜索似乎是解决人类问题的特征。
为了解决这些缺点,我们引入了思维树(ToT),这是一个允许LM通过思考来探索多个推理路径的框架(图1c)。ToT将任何问题都当作在树上进行搜索,其中每个节点是一个状态
s
=
[
x
,
z
1
⋅
⋅
⋅
i
]
s=[x,z_{1···i}]
s=[x,z1⋅⋅⋅i],表示基于输入和当前思维序列的部分解决方案。ToT的特定实例涉及回答四个问题:1.如何将中间过程分解为思维步骤;2.如何从每个状态生成潜在的思维;3.如何启发式评估状态;4.要使用什么搜索算法。
- Thought decomposition。虽然CoT在没有显式分解的情况下采样了连续思想,但ToT利用问题属性来设计和分解中间思考步骤。这取决于不同的问题,如表1所示,一个思维可能是几个单词(填字游戏),方程式(24点游戏)或描述整个写作计划的段落(创意写作)。通常,一个思维应该足够“小”,以便LM可以生成有希望和多样化的样本(例如,生成整本书通常太大了,无法保持连贯),但也要足够“大”,以便LM可以评估其解决问题的可能性(例如,生成一个token通常太小了,无法进行评估)。
- Thought generator
G
(
p
θ
,
s
,
k
)
G(p_θ,s,k)
G(pθ,s,k)。给定一个树的状态
s
=
[
x
,
z
1
⋅
⋅
i
]
s = [x,z1··i]
s=[x,z1⋅⋅i],我们考虑了为下一个思维步骤生成
k
k
k个候选的两种策略:
(a) 通过CoT提示采样多个独立同分布的思维(如图4中的创意写作): z ( j ) ∼ p θ C o T ( z i + 1 ∣ s ) = p θ C o T ( z i + 1 ∣ x , z 1... i ) ( j = 1 , . . . , k ) z^{(j)}\sim p^{CoT}_{\theta}(z_{i+1}|s)=p^{CoT}_{\theta}(z_{i+1}|x,z_{1...i})(j=1,...,k) z(j)∼pθCoT(zi+1∣s)=pθCoT(zi+1∣x,z1...i)(j=1,...,k)。当思维空间丰富时,这种方式更好(即每一个思维都是一个段落),并且独立同分布的样本会导致多样性;
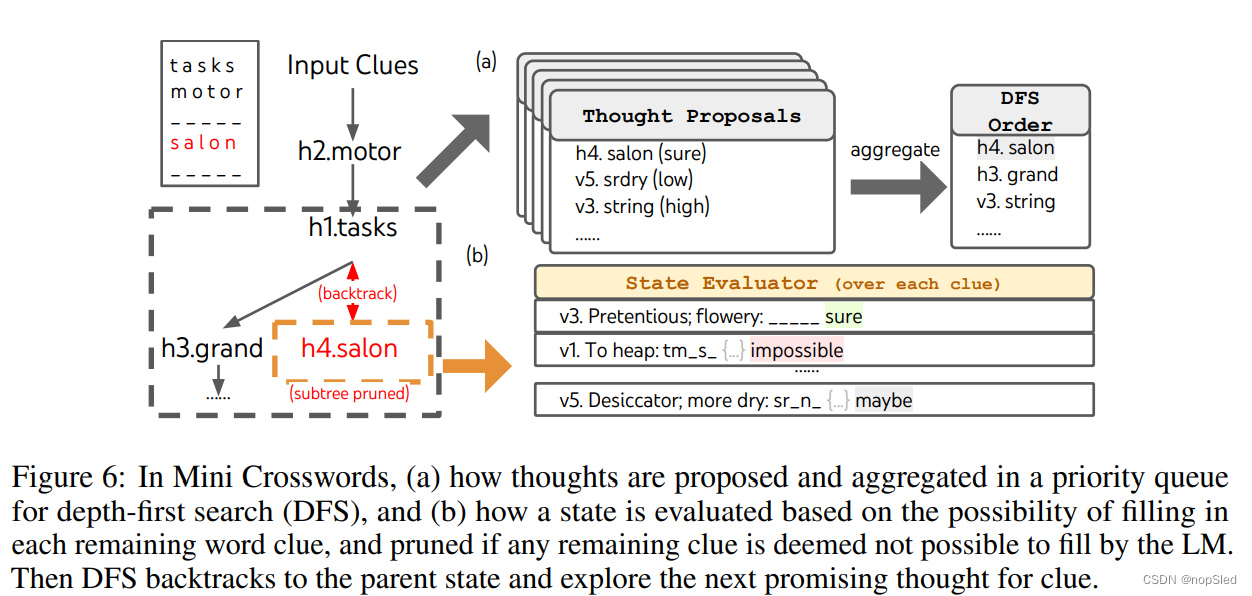
(b) 通过使用propose prompt来顺序获取提示(如图6所示的24字游戏和填字游戏): [ z ( 1 ) , . . . , z ( k ) ] ∼ p θ p r o p o s e ( z i + 1 ( 1... k ) ∣ s ) [z^{(1)},...,z^{(k)}]\sim p^{propose}_{\theta}(z^{(1...k)}_{i+1}|s) [z(1),...,z(k)]∼pθpropose(zi+1(1...k)∣s)。当思维空间有约束时,这种方式更好(即每一个思维是一个单词或一行),因此能在相同上下文情况下避免活得重复提示。 - State evaluator
V
(
p
θ
,
S
)
V(p_θ, S)
V(pθ,S)。给定不同状态的一个边界,状态评估器评估了他们在解决问题方面取得的进展,以作为搜索算法的启发式工具,以确定要在哪些状态以及哪个顺序上继续探索。尽管启发式方法是解决搜索问题的标准方法,但它们通常是程序化(例如DeepBlue)或可学习(例如AlphaGo)的标准方法。我们通过使用LM对状态进行推理,提出了第三种替代方案。如果适用,这种启发式可以比编程规则更灵活,并且比可学习的模型更有效。与思维生成器类似,我们考虑了两种策略来独立或共同评估状态:
(a) 独立使用每个状态的价值进行评估: V ( p θ , S ) ( s ) 〜 p θ v a l u e ( v ∣ s ) ∀ s ∈ S V(p_θ,S)(s)〜p^{value}_θ(v|s) ∀s∈S V(pθ,S)(s)〜pθvalue(v∣s)∀s∈S,其中使用一个关于状态 s s s的价值提示来生成一个标量值 v v v(例如1-10)或者可以启发变成价值的类别(例如,确定/可能/不可能)。这种评估推理的基础可能会因问题和思维步骤而发生改变。在这项工作中,我们通过很少的前向模拟来探索评估(例如,可以通过5 + 5 + 14迅速确认5、5、14能得到24,或者“hot_l”可以通过填充“ e”表示“inn”)。再加上常识(例如1 2 3太小而无法达到24,或者没有一个单词可以从“ tzxc”开始)。前者可以得到一个好的状态,后者则可以帮助消除坏的状态。这些价值估计不需要非常准确,只需要大致即可。
(b)不同状态间的投票: V ( p θ , S ) ( s ) = I [ s = s ∗ ] V(p_θ,S)(s)=\mathbb I[s=s^∗] V(pθ,S)(s)=I[s=s∗],其中一个好状态 s ∗ 〜 p θ v o t e ( s ∗ ∣ S ) s^∗〜p^{vote}_θ(s^∗|S) s∗〜pθvote(s∗∣S)基于对 S S S中不同状态采用vote prompt进行比较来投票。当问题很难直接通过价值来评估时(例如,通行连贯性),通过投票来选择最合适的一个是一种自然的选择。这在原则上与“逐步”自洽策略相似,即将“要探索的状态”作为多选QA,并使用LM样本对其进行投票。
对于这两种策略,我可以对LM提示多次来整合获得最终的价值或投票结果,以对时间/资源/成本进行平衡。 - Search algorithm。最后,在ToT框架内,可以根据树结构采用不同搜索算法。我们探索两种相对简单的搜索算法,并基于更多高级算法(例如A*,MCT)作为未来的探索工作:
(a) 广度优先搜索(BFS)(算法1)每步维护一组 b b b个最有可能的状态集合。这用于24字游戏和创意写作,其中树的深度受限( T ≤ 3 T≤3 T≤3),然后初始思维不厚可以评估并修剪至小集合( b ≤ 5 b≤5 b≤5)。
(b) 深度优先搜索(DFS)(算法2)首先探索最有希望的状态,直到达到最终输出( t > T t>T t>T),或状态评估器认为无法从当前 s s s解决问题(即 V ( p θ , { s } ) ( s ) ≤ v t h V(p_θ,\{s\})(s)≤v_{th} V(pθ,{s})(s)≤vth,其中 v t h v_{th} vth是一个阈值)。在后一种情况下,DFS回溯到 s s s的父状态以继续探索。
从概念上讲,作为通过LM解决一般问题的方法,ToT具有多种好处:(1)一般性。可以将IO,CoT,CoT-SC和自我修正看作是ToT的特殊情况(即深度和宽度有限的树;图1)。(2)模块化。 基于LM的思维分解,生成,评估和搜索过程都可以独立变化。(3)适应性。 可以容纳不同的问题属性,LM功能和资源限制。(4)便利。不需要额外的培训,只有预训练的LM就足够了。
4.Experiments



















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









