






paper:https://arxiv.org/pdf/2308.09687.pdf
code:https://github.com/spcl/graph-of-thoughts
0 Abstract
- 不同于以往的CoT和ToT,文章提出了GoT,将LLM生成的信息构建为任意图:
- 顶点:LLM thoughts(信息单元)
- 边:顶点之间的依赖
- GoT的优势:
- 将任意LLM thoughts【LLM对于给定prompt的回答】组合成协同结果,提炼模型本质,即让LLM更自由的去组合思想,获得答案;
- 相比sota实现了点和效率的双重提升;
- 作者认为思维图推导的方式更接近人类思维,可以辅助LLM解决更为复杂的问题。
1 Introduction
-
提示工程(prompt engineering)对LLM非常重要:in-context learning,zero-shot prompt…
- CoT/CoT-SC:提示解决问题的中间步骤;
- ToT:生成多路解决方案,具有从次优解决方案回溯的功能(DFS,BFS搜索)【作者提出,这种方案在LLM的思维过程中强加了树的结构,会限制模型的推理能力】;
- GoT:更接近人类思维过程:每个推理步骤有多于1条入边,支持链路合并,这些是CoT和ToT做不到的。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/10f83420d98bdd47854c79893294f65f.png)
-
应用GoT到LLM的挑战与解决方案:
- 挑战:每个任务最优的图结构?如何合并思想找出最优解?
- 解决方案:
- 实现对各个思维的细粒度控制;
- 架构设计的可扩展性。
-
GoT天然适合于可以分解为子步骤独立解决再合并得到最终解的任务。
-
文章还提出一个可以用于评估提示策略的指标:volume of a thought(思想体积)【对于给定的思想v,v的体积是LLM思想的数量,可以使用有向边到达v(有多少条路可以到达)。】
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/cd6e3817fa55f47ee461ddf2c3104caa.png)
2 The GoT Framework
2.1 Reasoning Process
- 推理过程可以抽象为一个有向图G=(V,E)的子集,有向边(t1,t2)表示LLM用t1作为直接输入生成t2;
- 在一些特殊例子,节点属于不同类别,GoT可以构建为异构图G=(V,E,c)【节点类型+边类型>2】;
- 使用thought transformations来推进推理过程,例如合并高评分的thoughts,或者循环增强一个thoughts。
2.2 Transformations of Thoughts
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/87b0954e88459ca4c8966be548ab83fb.png)
- 转变过程可以被抽象为T=(G,pθ),pθ表示LLM参数,T通常表现为为G加入新的顶点以及相应的入边;
- 为了最大化GoT的表达,允许用户显式地移除G中的边和点;
- 具体的思想转变方法:
- Aggregation Transformations:对于一个新节点,添加该节点的入边(即其他任意节点的出边)实现聚合;
- Refining Transformations:一个节点的出边是自己的入边(即自环),用于精炼该思想;
- Generation Transformations:基于现有的节点生成一个或者多个新节点。
2.3 Scoring & Ranking Thoughts
- 思想评估系统被抽象为:E=(v,G,pθ),v是指被评估的思想;
- 思想排名系统被抽象为:R=(G,pθ,h),h是指top-h,即要R返回的分数最高的h个思想;
- E和R$的具体形式取决于用例。
3 System Architecture & Extensibility
- Prompter:通过对当前推理图的结构进行编码,构建送入LLM的prompt
- Parser:从LLM的回复中提取信息,并更新GRS(即更新推理图状态)
- Scoring & Validation:对LLM的回复进行验证和评分,验证了给定的LLM的思想是否满足潜在的正确性条件(可以由LLM或者人类用户来给出)
- Controller:协调整个推理过程,并决定如何进展(使用什么思想转换?决定是否停止推理输出最终结果?)
- GoO & GRS:Controller的两个部件
- GoO【静态结构:在执行开始时由用户进行构建,GoO规定了应用于LLM的思想转换(可以执行什么操作?它们的顺序和依赖关系,以及如何评分?已经封装成了code),并且可以记录已经执行的操作】
- GRS【动态结构:维护正在进行的LLM推理过程的状态(思想的历史和状态)】
【图见文章中】
4 Example Use Cases
4.1 Sorting
- 输入序列:[a1,a2,…,an] 输出序列:[b1,b2,…,bn]
- 评分:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/38bce36b4973d1d5377a749a410568c5.png)
- X:有多少连续的数字对被错误地排序?
- Y:确定给定输出序列保留输出数字频率的程度。
【见文章中的详尽例子】
4.2 Set Operations(集合操作)
-
文章提供了集合操作,特别是集合合并(例如两个列表数字的合并)
-
评分: 输入集合1:A=[a1,a2,…,an] 输入集合2:B=[b1,b2,…,bn] 输出集合:C=[c1,c2,…,cn]
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/521f864add51dd7935d22da2f5aa768f.png)
- X1:C中不应该有的元素;
- X2:C中缺少的元素;
- Xd:C中的重复元素。
4.3 Keyword Counting
- 统计关键字的数量
- 首先将文本划分为N个段落,统计每个段落中关键字段数量,再进行合并
- 评分:推导出计算计数和正确计数之间的绝对差值
4.4 Document Merging
- 文档合并(合并的文档中存在重复段落,在确保最少重复量的同时保证信息最大化)
- 评分:查询方案冗余值(0-10) + 信息保留值(0-10)
5 The Latency-Volume Tradeoff
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/eb4278c8798a22a124884d3d4b2680e4.png)
6 Evaluation
-
使用GPT3.5,每个任务有100个输入样本,包含4k上下文;
-
ToT:对分支因子k(宽度)和层数L(深度)的数量进行了广泛的实验;
-
sorting:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/71565f720658d0ebcfaab46092f7693f.png)
- 在128排序中,GoT相比ToT提高了约62%的排序质量,同时降低>31%的计算成本(所有prompt和tokens的长度)
- 问题越复杂,GoT优势越明显
-
set intersection:
[图片]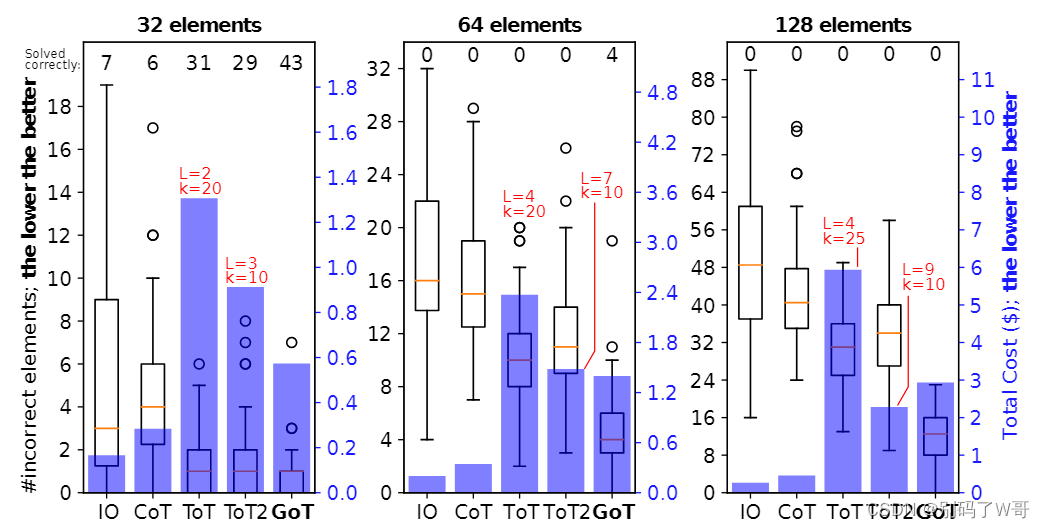
-
keyword counting:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/f74e3fe2f61f0887ec3620daebeb486f.png)
- 提示样例的大小对于加速整个过程有至关重要的作用;
- LLM可以使用单个提示(或一些额外的改进步骤)正确地解决问题;
- 相较于从头开始,对子结果进行聚合通常是更加高效的方式。
-
document merging:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/d3c60ae25036f769c706cb8bc4f2f49e.png)

















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









