







线性回归也就是可以用一条直线来拟合一个点集。博主大概总结下机器学习的线性模型,以及主要的公式推到,参考书籍是周志华教授的西瓜书《机器学习》,博主给出了一些西书中主要的公式推导思路或过程,对于常用的逻辑回归模型,利用sklearn机器学习包实现对MNIST公共数据集的简单分类应用。机器学习无非是回归和分类的问题,其目的就是学习一个数学函数,通过该数学函数输入得到输出。线性模型主要有以下三大类,也是本文要总结的三大类,其实只有前两者是用来做回归的,而最后一个是做分类的:
- 一元线性回归模型(一个自变量和一个因变量)
- 多元线性回归模型(多个因变量)
- 对数几率回归模型(逻辑回归模型,用来做分类)
1.一元线性回归模型
这个其实很好理解,直接看西瓜书给出的公式就知道:
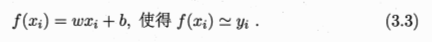
目的很简单,就是给定样本输入x求解输出f(x),而线性回归模型的主要工作就是学得参数w和b,且使得损失函数最小,也就是说在预测过程中,我们需要使预测值和真实值之间的误差最小。求解参数的主要思路步骤:
- 由最小二乘法导出损失函数E(w,b),也就是均方误差最小化求解。损失函数定义如下:
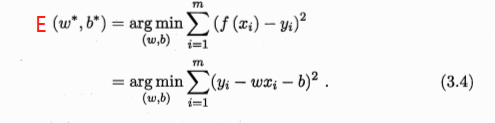
- 证损失函数是凸函数,根据二元函数凹凸性判定定理证明即可,也就是分别求出关于w和b的二阶偏导值,利用AC-B^2>=0来判断其为凸函数。
- 分别对w和b求解一阶偏导,并令其为0,解出的w和b就是我们要求得的参数能使得损失函数值最小,由此可以推导出西瓜书的等式:
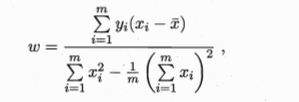
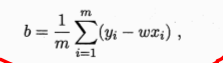
- 其实最后一步w参数的向量化目的是方便编程,在实际的应用中,给出的数据样本值x一般是一个序列,向量化有助于python利用矩阵工具计算相应的参数值。
2.多元线性回归模型
多元回归模型的推导思路和一元是一样的,但是不同的是需要把w和b统一为向量的形式(w;b),西瓜书中直接给出了损失函数让人看不懂: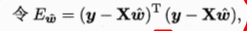
实际的推导如下*(因为公式不好敲,这里就贴个图片了哈,谅解!!!)*
现在最关键的一步就是损失函数的求解,求解最小值,这里讲述两种方式,第一种就是和一元的思路差不多,涉及到矩阵的求导和微分(牛顿法/拟牛顿法),第二种也是值得推荐的一种常用的方法,梯度下降法,其不只是使用在一元/多元线性回归上,其它机器学习的模型也常用梯度下降法来优化损失函数,求解最优参数解。现在分别大致描述下两种方法的思路。
1. 西瓜书的思路属于第一种,判断凹凸性,也就是Hessian矩阵正定,则为凸函数。Hessian矩阵其实就是在梯度(一阶偏导数存在) 的类似基础上,求解二阶偏导数存在。推到过程如下:
2. 梯度下降法它是用迭代的方法求解目标函数得到最优解,是在cost function(成本函数)的基础上,利用梯度迭代求出局部最优解。
对于线性回归模型:
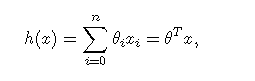
损失函数为:
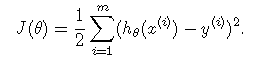
给一个初始值,使损失函数逐次变小,使每次都往梯度下降的方向改变:
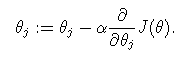 表示下降速度。
表示下降速度。
为了求偏导数,当只有一个样本时,即
 ;
;
当有多个训练样本时,下降梯度算法即为:
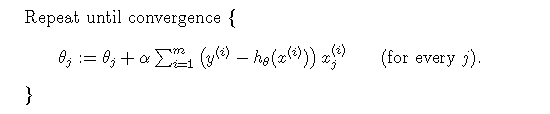
由于每次迭代都需要计算所有样本的残差并加和,因此此方法也叫做批下降梯度法(batch gradient descent),当有大规模数据时,此方法不太适合,可采取它得一个变种,即每次更新权重时,不是计算所有的样本,而是选取其中一个样本进行计算梯度,这个方法叫做随机下降梯度法(stochastic gradient descent):
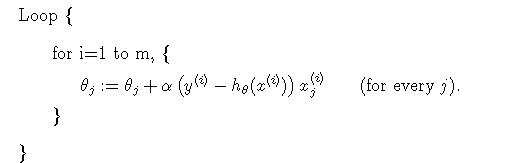
随机下降梯度法与下降梯度法对比可能收敛更快,但是可能找不到最优点而在最优点附近徘徊。
对于局部加权线性回归(LWLR),可以参考如下博客:
https://blog.csdn.net/tercel_w/article/details/62883704
**总结:**线性回归的优点计算简单,容易实现,缺点使无法拟合非线性数据!!!
逻辑回归模型(对数几率回归)
Logistic是用来分类的,是一种线性分类器。逻辑回归的表达式可以通过替代函数和广义线性模型来推导,需要记住其表达式为:
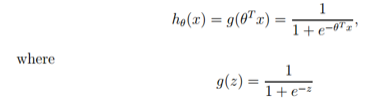
其导数形式为:
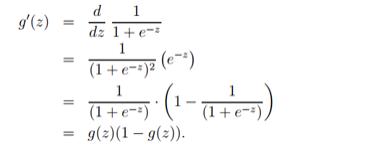
logsitc回归方法主要是用极大似然估计来学习的,所以单个样本的后验概率为:
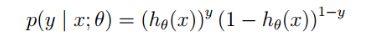
所以,整个样本的后验概率为:
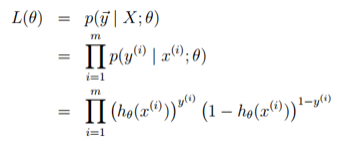
取对数,得似然函数:
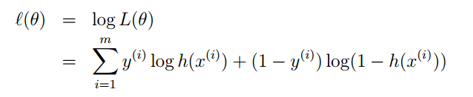
似然函数取得最大值即为损失函数取得最小值,也可采用梯度下降法求解参数:
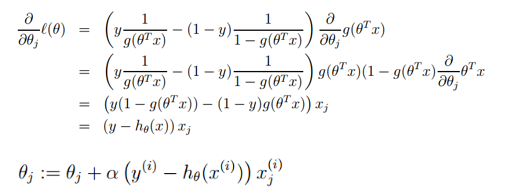
**总结:**逻辑回归的优点计算简单,分类时计算很快;缺点就是容易欠拟合,准确度不高,只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分。
Logistic回归模型的实践
采用的数据集为MNIST数据,可以进入该网盘下载:链接
链接:https://pan.baidu.com/s/1kc8oLBfUKdI_oK8j60RTNw
提取码:qcad
PyCharm+Anaconda实现代码:
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.utils import check_random_state
# 读取数据集
df = pd.read_csv('mnist_784.csv')
#按照行号来索引,区别于loc是按照index来索引
X = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
print(X.shape,y.shape) #查看维度
t0 = time.time()
train_samples = 5000 #训练样本大小
#check_random_state():这里使用的是numpy.random.RandomState().RandomState()可以使用int,array,None。None的时候就是随机。和np.random.seed()比较,seed只能用一次,每次调用随机函数用在之前再声明一下。
random_state = check_random_state(0)
permutation = random_state.permutation(X.shape[0]) #打乱顺序
X = X[permutation]
y = y[permutation]
X = X.reshape((X.shape[0],-1)) #reshape()最后一位如果是-1,表示适应前面的分法
X_train, X_test, y_train, y_test = train_test_split(X,y,train_size=train_samples,test_size=10000) #划分测试集和训练集,指定训练集和测试集的大小
#对每个特征,数据归一化(x-u)/s
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) #训练集上需要先拟合再标准化
X_test = scaler.transform(X_test) #测试集上直接标准化
"""
@penalty:正则化类型,默认为L2
@tol:迭代终止判断的误差范围
@C:默认:1.0;其值等于正则化强度的倒数,为正的浮点数。数值越小表示正则化越强。
@solver:{'newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'},默认: 'liblinear';用于优化问题的算法。
@multi_class:{ovr', 'multinomial'},默认:'ovr';如果选择的选项是“ovr”,那么一个二进制问题适合于每个标签,否则损失最小化就是整个概率分布的多项式损失。对liblinear solver无效。
"""
clf = LogisticRegression(C=50./train_samples,
multi_class='multinomial',
penalty='l1', solver='saga', tol=0.1)
clf.fit(X_train,y_train) #训练
sparsity = np.mean(clf.coef_ == 0) * 100
score = clf.score(X_test, y_test)
#打印结果
print("Sparsity with L1 penalty: %.2f%%" % sparsity)
print("Test score with L1 penalty: %.4f" % score)
coef = clf.coef_.copy()
plt.figure(figsize=(10, 5))
scale = np.abs(coef).max()
for i in range(10):
l1_plot = plt.subplot(2, 5, i + 1)
l1_plot.imshow(coef[i].reshape(28, 28), interpolation='nearest',
cmap=plt.cm.RdBu, vmin=-scale, vmax=scale)
l1_plot.set_xticks(())
l1_plot.set_yticks(())
l1_plot.set_xlabel('Class %i' % i)
plt.suptitle('Classification vector for...')
run_time = time.time() - t0
print('Example run in %.3f s' % run_time)
plt.show()结语:下一篇文章将在博主的博客**“项目”**里,简单运用Logistic分类模型实现达观杯的一个文本分类竞赛题,目的不是刷榜,而是想熟悉一下sklearn机器学习包的运用,以及一个机器学习算法是如何在一个实际场景中进行运用的。
参考资料:
[1]: 周志华.西瓜书《机器学习》
[2]:https://www.cnblogs.com/tornadomeet/p/3395593.html
[3]:https://blog.csdn.net/tercel_w/article/details/62883704
















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









