







原文:http://blog.csdn.net/xunan003/article/details/73126425
其他参考文章:http://blog.csdn.net/jiongnima/article/details/52681816?locationNum=11&fps=1http://
一、前沿
写这篇博文,是因为一开始在做《21天学习caffe》第6天6.4练习题1的时候看着自己搜索的博文,在不理解其根本的情况下做的,结果显然是错的。在接下来阅读完源代码之后,在第10天学习完caffe model zoo之后,明白了其中原理,反过来再去做那个习题,一开始在网上搜索并没有完完整整解释整个过程的一篇博文,而是写的不知所云,本着我们初学者互相共享的精神,也方便自己查阅,特详细写一下,将自己的一张手写体图片送入训练好的caffemodels中测试这个过程,博主也是在仿照参考书目的命令来逐项百度每个文件的制作方法,最终成功。结果还是比较美好的。接下来,就让我们一起来看看ubuntu下手写体数字的测试情况。
二、具体步骤
1、首先我们要知道要利用模型lenet_iter_10000.caffemodel测试单张手写体数字所需要的文件: 1>待测试图片(自己画的也行,网络上下的也行,楼主是在自己windows系统下用画图工具画的并命名为3.jpg,当然你如果愿意也可以弄成.dmp,.png等其他格式);

这是博主自己画的图片
需要注意的是,不管是什么格式,都要转换为28*28大小的黑白灰度图像,具体转化方法请自行百度(我是就拿windows自带的画图工具转化的)。因为
mnist数据集都是28*28的单通道黑白灰度图像。
2>deploy.prototxt(模型描述型文件);具体生成方法下面我们解释。
3>network.caffemodel(模型权值文件);在本例中就是lenet_iter_10000.caffemodel
4>labels.txt(标签文件);生成方法一会儿描述
5>mean.binaryproto(二进制图像均值文件);生成方法下面描述(类似的还有python下的均值文件mean.pny我们这里不做考虑,想去尝试的可以自己尝试)
6>classification.bin(二进制程序名)。与二进制均值文件配合使用,只是均值文件不同的模型有不同的均值文件,而这个bin文件为通用的,就是任何模型都
可以做分类使用。但是如果采用python借口模式的测试就要自己再做一个classification分类文件,具体方法下面解释的时候给链接。
2、步骤1:生成待测试图片
具体要求在1中已有说明,这里不做过多阐述。如还有人不懂如何做图请自行百度。
3、步骤2:生成deploy.prototxt文件
要了解deploy.prototxt文件的作用请自行百度或google,这里我们需要知道的是,他和lenet_train_test.prototxt文件类似,或者说对后者改动可得到前者。在熟悉生成文件的原理及方法之后我们可以之间在原训练prototxt网络文件中改动。在examples/mnist目录下复制一份lenet_train_test.prototxt修改并保存后得到deploy.prototxt如下:
- name: "LeNet"
- layer {
- name:"data"
- type: "Input"
- top: "data"
- input_param { shape: { dim: 1 dim: 1 dim: 28 dim: 28 } }
- }
- layer {
- name:"conv1"
- type: "Convolution"
- bottom: "data"
- top: "conv1"
- convolution_param {
- num_output: 20
- kernel_size: 5
- stride: 1
- weight_filler {
- type: "xavier"
- }
- }
- }
- layer {
- name:"pool1"
- type: "Pooling"
- bottom: "conv1"
- top: "pool1"
- pooling_param {
- pool: MAX
- kernel_size: 2
- stride: 2
- }
- }
- layer {
- name:"conv2"
- type: "Convolution"
- bottom: "pool1"
- top: "conv2"
- convolution_param {
- num_output: 50
- kernel_size: 5
- stride: 1
- weight_filler {
- type: "xavier"
- }
- }
- }
- layer {
- name:"pool2"
- type: "Pooling"
- bottom: "conv2"
- top: "pool2"
- pooling_param {
- pool: MAX
- kernel_size: 2
- stride: 2
- }
- }
- layer {
- name:"ip1"
- type: "InnerProduct"
- bottom: "pool2"
- top: "ip1"
- inner_product_param {
- num_output: 500
- weight_filler {
- type: "xavier"
- }
- }
- }
- layer {
- name:"relu1"
- type: "ReLU"
- bottom: "ip1"
- top: "ip1"
- }
- layer {
- name:"ip2"
- type: "InnerProduct"
- bottom: "ip1"
- top: "ip2"
- inner_product_param {
- num_output: 10
- weight_filler {
- type: "xavier"
- }
- }
- }
- layer {
- name:"prob"
- type: "Softmax"
- bottom: "ip2"
- top: "prob"
- }
4、步骤3:生成labels.txt标签文件
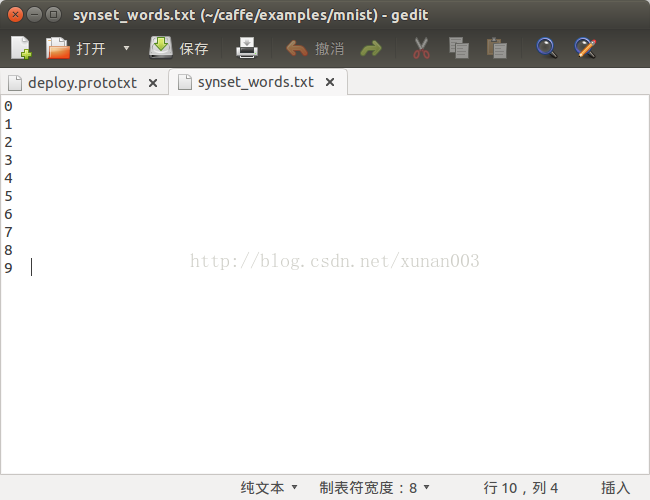
在当前目录下新建一个txt文件,命名为synset_words.txt,里面内容为我们训练mnist的图片内容,共有0~9十个数,那么我们就建立如下内容的标签文件:
5、步骤4:生成mean.binaryproto二进制均值文件
均值文件分为二进制均值文件和python类均值文件。因为博主还未配置python接口,故未采用python方法,这也是之前一直出错的原因。
生成均值文件的两种方法请参看博文:点击博文链接
caffe作者为我们提供了一个计算均值的文件compute_image_mean.cpp,放在caffe根目录下的tools文件夹里面,运行下面命令生成mean.binaryproto二进制均值文件。
- sudo build/tools/compute_image_mean examples/mnist/mnist_train_lmdb examples/mnist/mean.binaryproto
生成的mean.binaryproto均值文件保存在了examples/mnist目录下。
6、步骤5:分类器classification.bin(windows下caffe为classification.exe)
在example文件夹中有一个cpp_classification的文件夹,打开它,有一个名为classification的cpp文件,这就是caffe提供给我们的调用分类网络进行前向计算,得到分类结果的接口。就是这个文件在命令中会得到classification.bin,具体我们可以不用管它,在其他caffemodel下不用修改也可以用,不像均值文件,不同的模型需要不同的均值文件。
需要详细了解classification请参看博文(或其他资料):点击博文链接
如果是按照python接口方法做此测试,均值文件及分类classification以及测试过程请参看博文:点击博文链接
7、步骤6:准备测试
万事具备,只欠东风。下面我们就在caffe根目录下命令:
- ./build/examples/cpp_classification/classification.bin examples/mnist/deploy.prototxt examples/mnist/lenet_iter_10000.caffemodel examples/mnist/mean.binaryproto examples/mnist/synset_words.txt examples/images/3.jpg
下面看看我们的测试结果吧!

三、参考博文
参考博文链接:http://blog.csdn.net/jiongnima/article/details/52681816?locationNum=11&fps=1















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









